タスク:分散ファイルストレージを整理する
-自己組織化カーネル、モジュール、パッチなし
-rwモードで複数のマウントの可能性がある場合、
-POSIX互換性、
-耐障害性、
-すでに使用されている技術との互換性、
-ローカルファイルシステムと比較したI / O操作の合理的なオーバーヘッド、
-構成、保守、および管理の容易さ。
作業では、 ProxmoxおよびOpenVZコンテナー仮想化を使用します。 便利で、飛び、このソリューションには類似の製品よりも多くの利点があります。 少なくとも私たちのプロジェクトと私たちの現実では。
ストレージ自体は、FCのどこにでもマウントされています。
OCFS2
このファイルシステムを使用して成功したので、最初に試してみることにしました。 Proxmoxは最近Redhatカーネルに切り替え、ocfs2サポートがオフになりました。 カーネルにはモジュールがありますが、openvzフォーラムとproxmoxフォーラムでは使用を推奨していません 。 カーネルを再構築してみました。 モジュールバージョン1.5.0、debian squeeze、proxmox 2.0beta3、カーネル2.6.32-6-pveに基づく4台の鉄製マシンのクラスター。 テストでは、ストレスが使用されました。 問題は数年間同じままでした。 すべてが起動し、この束を設定するのに力から30分かかります。 ただし、負荷がかかると、クラスターが自発的に崩壊する可能性があり、これにより、すべてのサーバーでカーネルパニックが同時に発生します。 テストの日に、マシンは合計5回再起動しました。 処理されますが、そのようなシステムを使用可能な状態にすることは非常に困難です。 また、カーネルを再構築してocfs2を有効にする必要がありました。 マイナス
Gfs2
カーネルはRedhatですが、モジュールはデフォルトで有効になっていますが、ここでも起動できませんでした。 それはすべて、proxmoxについてであり、2番目のバージョンからは、設定を保存するためのチェスと詩人を持つ独自のクラスターを思いつきました。 cfs、corosync、およびgfs2-toolsからの他のパッケージがあり、すべてpve専用に再構築されています。 したがって、gfs2のスナップインは、すべてのproxmoxを最初に破棄することを提供するため、パッケージから除外されません。 3時間の嗜癖で、なんとか勝ちましたが、再びカーネルパニックは終わりました。 パッケージをproxmoxに適合させて問題を解決しようとする試みは成功しませんでした。2時間後、このアイデアを放棄することになりました。
セフ
私たちはその上で停止しました。
POSIX互換、高速、優れた拡張性、大胆で興味深い実装方法。
ファイルシステムは、次のコンポーネントで構成されています。

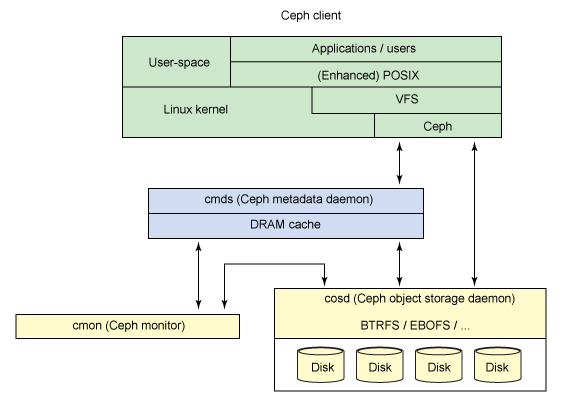
1.顧客。 データユーザー。
2.メタデータサーバー。 分散メタデータはキャッシュされ、同期されます。 クライアントは、メタデータを使用して、必要なデータがどこにあるかをいつでも知ることができます。 メタデータサーバーも新しいデータを配布します。
3.オブジェクトを保存するためのクラスター。 ここでは、データとメタデータの両方がオブジェクトとして保存されます。
4.クラスターモニター。 システム全体の健全性を監視します。
実際のファイルI / Oは、クライアントとオブジェクトストレージクラスターの間で発生します。 したがって、高レベルのPOSIX機能の管理(オープン、クローズ、および名前変更)はメタデータサーバーを使用して実行され、通常のPOSIX機能(読み取りおよび書き込み)はオブジェクトストレージクラスターを通じて直接管理されます。
管理者が直面しているタスクに応じて、いくつかのコンポーネントがあります。
ファイルシステムは、カーネルモジュールを使用して直接接続するか、FUSEを介して接続できます。 ユーザーの観点から見ると、Cephファイルシステムは透過的です。 巨大なデータストレージシステムにアクセスするだけで、メタデータサーバー、モニター、およびこれに使用される大規模なストレージプールを構成する個々のデバイスを認識しません。 ユーザーには、標準のファイルI / O操作を実行できるマウントポイントが表示されるだけです。 管理者の観点からは、必要な数のコンポーネント、モニター、ストレージ、メタデータサーバーを追加することにより、クラスターを透過的に拡張できます。
開発者は誇らしげにCephエコシステムを呼び出します。
GPFS、Lustre、およびその他のファイルシステム、およびアドオンについては、今回は考慮しませんでした。セットアップが非常に難しいか、開発しないか、仕事に合わないかのいずれかです。
構成とテスト
設定は標準であり、すべてCeph wikiから取得されます。 一般的に、ファイルシステムは良い印象を残しました。 2TBのアレイは、SASおよびSATAディスク(FCによるブロックデバイスのエクスポート)、ext3のパーティションから半分に組み立てられました。
Cephストレージは、4つのハードウェアノード上の12の仮想マシン内にマウントされ、すべてのマウントポイントから読み取り/書き込みが可能です。 ストレステストの4日目は正常に合格し、I / Oは平均75 mb / sで発行されます。 ピーク時の記録。
他のCeph機能についてはまだ検討していません(まだかなり多くあります)。FUSEにも問題があります。 しかし、開発者は、このシステムは実験的であり、本番環境では使用すべきではないと警告していますが、本当にしたいのであれば、次のことができると信じています-_-
PMに関心のあるすべての人、およびすべてのシンパサイザに質問します。 このトピックは非常に興味深いものであり、発生した問題について話し合い、解決する方法を見つけるために、志を同じくする人々を探しています。
参照:
-http://ru.wikipedia.org/wiki/Ceph
- プロジェクトサイト
-この記事の執筆に使用した簡単な概要