 この記事は、州下院のウェブサイトにある革新に関する一連の記事の2番目です( 記事1 )。
この記事は、州下院のウェブサイトにある革新に関する一連の記事の2番目です( 記事1 )。
開かれた政府の概念は、現在人気を集めています。 たとえば、米国政府部門からの大量のデータがdata.govで公開され、同様の英国の資料がdata.gov.ukで公開されています。 構造化された情報を公開する重要な側面は、機械で読み取り可能な形式で情報を受信できることです。 HTMLテーブルも正常に解析できることは明らかですが、外部システムとの統合に便利な形式で情報を提供することは、オープン性の非常に重要な指標です。 したがって、 請求書検索システム用のAPIの開発は、State Duma Webサイトのフレームワーク内での「オープンステート」コンセプトの実装における重要なステップになりました。 請求書のデータを外部の情報システムに簡単に統合できるようになりました。 たとえば、分析ポータルでは、特定の法案に関する記事の隣に、法案の進捗状況に関する現在の情報を反映するウィジェットを配置できます。
API機能
提供されたAPIは、実際には、多くのパラメーターを考慮して、請求書の検索を実装します。 さらに、さまざまな参考書へのアクセスと、各請求書の成績証明書の表示を提供します。 クエリとそのパラメータのリストは、 ドキュメントに記載されています 。
APIによって処理される検索クエリの例をいくつか見てみましょう。
- 州下院のZhirinovsky V.Vの副議長が提案した拒否された法案。
- 警察法案とその改正。
- ロシア連邦大統領によって導入された法案は、現在、下院の委員会による検討を待っています。
これらのクエリの検索結果はここにあり、PHPのソースコードはドキュメントにあります 。
APIとの対話は、RESTアーキテクチャスタイルに従って実行されます。つまり、HTTPプロトコルが使用され、応答がXML、JSON(JSONPを含む)、およびRSS形式で発行されます。 幅広いサポートされている形式により、さまざまな状況でAPIを適用できます。 JavaScriptブラウザーから直接アクセスできます。 アプリケーションのサーバー側から、またはシッククライアントからでもリクエストを送信できます。 また、RSSを介して特定の検索クエリに登録し、最新の情報を直接追跡できます。
統計
州下院の新しいウェブサイトの導入以来、請求書の検索システムは7万人以上で使用されています。 APIの導入により、検索の人気がさらに高まることが予想されるため、検索が機能するだけでなく、迅速に機能することも重要でした。 直接最適化の前に、請求書の既存の検索フォームでユーザーが行うクエリに関する統計が収集されました。
最初に、検索パラメーターを使用する頻度を分析しました(1つの要求で複数のパラメーターを使用できるため、100を超えるパーセントの合計)。
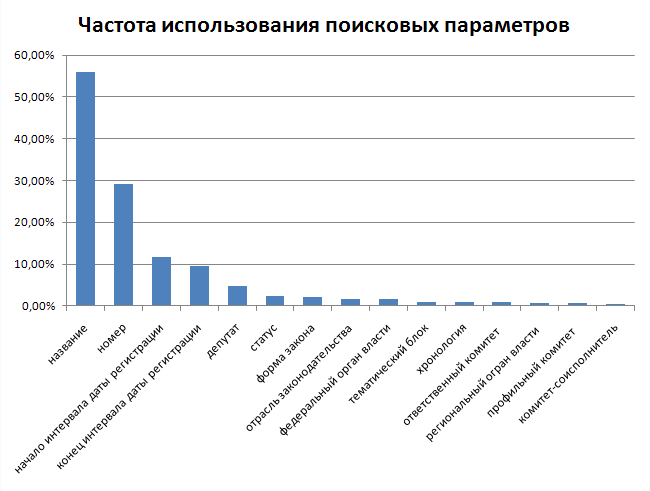
ご覧のとおり、分布は非常に不均一であり、最初にデータのインデックスを作成するために必要なパラメーターをすぐに確認できます。 もちろん、APIの公開後、リクエストの配信はサイトの請求書の検索フォームとはわずかに異なることが判明する可能性がありますが、良いリファレンスを受け取りました。
次に、ユーザーがページネーションを使用する方法を見てみましょう。
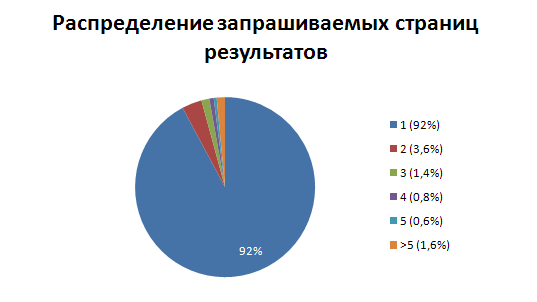
このグラフは、ユーザーが結果をスクロールすることはめったにないという事実をよく反映しています。リクエストの97%以上が最初の3ページに該当します。 したがって、多数のページを発行する最適化は無視できます。
次に、並べ替えの種類ごとにクエリの分布を調べました。

ご覧のとおり、デフォルトの並べ替えを変更する人はほとんどいないため、この並べ替えは最初にインデックスで表示する必要があります。
パフォーマンスを最適化する1つの方法は、検索クエリの結果をキャッシュすることです。 キャッシングが意味をなすためには、リクエストを十分な頻度で繰り返す必要があります。 同じ検索パラメーターを持つクエリの数がどのように分布しているかは、以下のグラフで確認できます。

要求が十分に頻繁に繰り返されるため、キャッシュが正当化されることがわかります。
そして、統計の最後に、TOP-10検索クエリ。

統計収集の時点で最もホットなトピックの1つは、教育に関する法律でした。
最適化
APIの開発とともに、法案データベースをOracleからPostgreSQLに転送するタスクもありました(データはora2pgを使用してインポートされました)。 次の最適化方法が適用されました。
GINインデックスを使用したPostgreSQLの組み込み全文検索が使用されます。
インデックスは、並べ替えが可能なフィールドと、フィルタリングが最も頻繁に実行されるフィールドに対して作成されました。
以前は、Oracle DBMSを使用してページごとのナビゲーションを行う場合、仮想rownum列に制限が課されていました。これは、選択の行番号を反映しています。 つまり たとえば、クエリによって返された最初の20行を表示する必要がある場合は、次の構成が使用されました。
選択 x。* から (main_query)x どこ rownum <= 20
これは一般に、最も正しい方法ではありませんでしたが、使用されているバージョン(Oracle 9i)では正常に機能しました。 また、たとえば100から始まる20行を表示する必要がある場合、次の構成が適用されました。 その中で、内部クエリは最初の120行を選択し、外部クエリは最後の20行のみを残します。
選択
*
FROM(
選択
rownum AS xrownum、
x。*
から
(main_query)x
どこ
rownum <= 120)
どこ
xrownum> 100;
PostgreSQLへの移行に伴い、LIMITおよびOFFSETコンストラクトが適用され始めました。 さらに、最適化の目的で、LIMITおよびOFFSET構造はテーブル結合の可能な限り深くに配置されました。 例を考えてみましょう。 テーブルaとbを組み合わせて、インデックス付きのフィールドで並べ替えます。 次に、LIMITとOFFSETをクエリ全体に適用すると、次のクエリプランが得られます。
選択
*
から
b
参加する
a
オン
b.a_id = a.id
ORDER BY
b.value
b.id
制限20
オフセット100;
クエリプラン
-------------------------------------------------- ----------------------------------------------
制限(コスト= 52.30..62.76行= 20幅= 39)
->ネストされたループ(コスト= 0.00..522980.13行= 1,000,000幅= 39)
-> bのb_value_id_idxを使用したインデックススキャン(コスト= 0.00..242736.13行= 1,000,000幅= 27)
-> aでa_pkeyを使用したインデックススキャン(コスト= 0.00..0.27行= 1幅= 12)
インデックス条件:(a.id = b.a_id)
つまり インデックスb_value_id_idxを通過し、見つかったテーブルbのレコードごとに、テーブルaのレコードがインデックスa_pkeyで結合されます。 この方法で見つかった最初の100レコードはスキップされ、次の20レコードが取得されます。次に、LIMITとOFFSETをテーブルbのみに適用した場合の結果を見てみましょう。 ページナビゲーションの構成の詳細については、 こちらをご覧ください。
選択
*
から
(
選択
*
から
b
ORDER BY
b.value
b.id
制限20
オフセット100
)b
参加する
a
オン
b.a_id = a.id;
クエリプラン
-------------------------------------------------- -------------------------------------------------- -
ハッシュ結合(コスト= 29.44..49.39行= 20幅= 60)
ハッシュ条件:(a.id = public.b.a_id)
-> aのSeqスキャン(コスト= 0.00..16.00行= 1000幅= 12)
->ハッシュ(コスト= 29.19..29.19行= 20幅= 48)
->制限(コスト= 24.16..28.99行= 20幅= 27)
-> bのb_value_id_idxを使用したインデックススキャン(コスト= 0.00..241620.14行= 1,000,000幅= 27)
ご覧のとおり、テーブルbの必要な行のみを選択した後、テーブルaへの接続は既に行われているため、保存されています。 2つではない場合、10個のテーブルがこの方法で結合されるとしましょう。その場合、効果は非常に大きくなります。 原則として、フィールドb.a_idが nullではなく、フィールドa.idが主キーである場合、グライダーにはそのような最適化を実行するために必要なすべての情報があります。 しかし、彼はそれを行う方法を知りません。おそらく、将来のバージョンでは状況が変わるでしょう。 そのため、LIMITとOFFSETを可能な限り深く配置するルールにすることができますが、それ以上悪化することはありません。
クエリ結果のキャッシュは、memcachedを使用して整理されます。 請求書の各検索の特徴は次のとおりです。
- 適用されたフィルターのセット
- 選別方法
- 表示されるページ番号。
2種類のキャッシュが提供されました。
- キーは重ねられたフィルターのセットで、値は満足できる結果の数です。
- キーはスーパーインポーズされたフィルターのセット、ソート方法、ページ番号(つまり、すべての検索パラメーター)であり、値は見つかった請求書のIDです。
したがって、データはキャッシュにコンパクトに格納されるため、キャッシュされたリクエストの数が増加しますが、リクエストの処理コストは増加します データの一部はメインデータベースからロードされます。
データベースの最適化により、65,000件の検索クエリのテストサンプルの処理時間を10時間から15分に短縮できました。
まとめ
完了した作業のおかげで、サイト上の請求書の検索フォームを介して以前に実行できたことはすべて、プログラムで実行できるようになり、さまざまな状況で使用できるようになりました。 私たちの努力が無駄にならず、開発されたAPIが有用で人気のあるサービスになることを願っています。
例として、APIで利用可能なすべての機能を使用する「法案による検索」というモバイルアプリケーションと、新しい法案の通知を受信して検索クエリにサブスクライブする機能を開発することにしました。 間もなく公開します。
