現在最も一般的なプロセッサアーキテクチャはx86-64です。 これらはCISCに分類されます。 それらにはコマンドの巨大なセットがあり、それがチップ上のコアの広い領域につながった。 これは、チップ上にいくつかのコアを実装するのに困難を伴いました。 X86プロセッサは、複数の小さな命令セット(RISC)の実行が必要なマルチスレッドコンピューティングには理想的ではありません。
レンダリングは、ほぼ無制限の数のコアに完全に並列化できるアルゴリズムです。
偏りのないレンダリング
鉄の生産性が着実に成長しているという事実を考慮すると、技術的な問題(たとえば、V線での材料の反射のサンプリング、アンチエイリアシングのバイアスの量、モーションブラー、被写界深度、ソフトシャドウ)が鉄の肩にますますシフトしています。 そのため、数年前、最初の商用の不偏レンダリングが登場しました-Maxwell Render。
その主な利点は、最終的な画像の品質、最小限の設定、あらゆる種類の「バイアス」でした。 時間が経つにつれて、画質は「理想」に近づきます。 そして、欠点はありました-レンダリング時間。 騒音が鳴るまで待つのに非常に長い時間がかかり、多くの人が数回の試行の後すぐにそれを拒否しました。 状況はアニメーションでさらに悪化しました(理由は明らかです)。
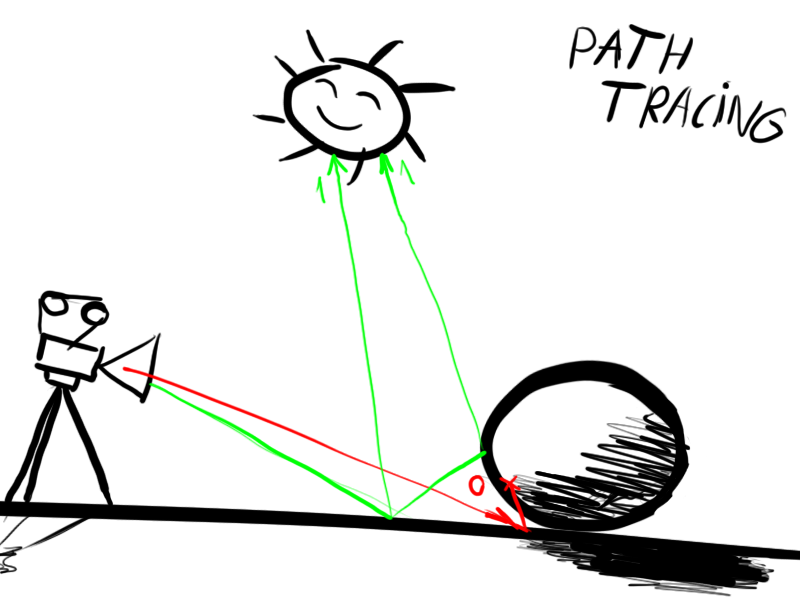
アルゴリズム
1.ビーム(画面上の特定のピクセルに対応する開始点)がカメラから解放されます。
2.ジオメトリ要素の1つがビームを横切ったかどうかを確認します。 そうでない場合は、手順1に進みます。
3.ビームとカメラに最も近いジオメトリの交点を決定します。
4.交差点から光源に向かって新しいビームを放します。
5.交差点と光源の間のビームに障害物がある場合、ステップ7に進みます。
6.ピクセルを色で塗りつぶします(単純化、特定のポイントでの表面の色に、ビームとの接触ポイントでの光源の強度を掛けたもの)
7.交点から任意の方向に新しい光線を放し、反射の最大数に達するまで手順2に進みます(ほとんどの場合4〜8、シーンに多くの反射または屈折がある場合、この数を増やす必要があります)。

「ノイズの多い」画像の例。
優れた品質を達成するためのピクセルあたりのサンプル数は、数千単位で測定できます。 たとえば、10,000(シーンに応じて)
画像あたりの光線の数FullHD 2mpix * 10,000-200億。
パストレースの最適化にはいくつかのタイプがあります。双方向パストレース、メトロポリスライトトランスポート、エネルギー再配布パストレース。光線を「必要な場合」にできるように設計されています。 CPUでのほとんどのレンダリングは、この目的のためにMLTアルゴリズム(Maxwell、Fry、Lux)を使用します。
GPUの役割
このアルゴリズムは浮動小数点演算を再利用し、このアルゴリズムにはマルチスレッドが不可欠です。 したがって、このタスクは徐々にGPU自体に受け入れられます。
既存のテクノロジー:CUDA、FireStream、OpenCL、DirectCompute、およびシェーダー上で直接プログラムを作成することもできます。

状況は次のとおりです。
CUDA-全員に書き込み、さまざまなもの(iRay、Octane Render、Arion Render、Cyclesなど)。
FireStream-何も表示されません。
OpenCL-SmallLuxGPU、サイクル、Indigo Render。 誰も真剣に受け止めていないようです。
DirectCompute-何も表示されません。
シェーダーはほんの一例です。 シェーダーでのパストレースの WebGL実装。
レンダリングの比較はパート2で行われます。