さらに、すべてのサーバーで古いファイルを一度に削除する必要がある場合がありますが、これまでのところ手動で行われ、数日かかります。 このようなユースケースの最速のファイルシステムの問題については、後で説明する予定です。 いくつかの理由でXFSが選択された場合のみ予約できます。
いくつかのクラスターテクノロジーとファイルシステムをテストした後、シニアフレンドのアドバイスを受けて、同じrsyncをinotifyと組み合わせて使用することにしました。 このような既製のソリューションをインターネット上で少し検索して、車輪を再発明しないために、csyncd、inosync、およびlsyncdに出会いました。 ハブにはcsyncdに関する記事が既にありましたが、ここでは機能しません。 SQLiteデータベースにファイルのリストを保存します。これは、100万件のレコードでも機能する可能性は低いです。 そして、そのようなボリュームとの余分なリンクは役に立ちません。 しかし、lsyncdがまさに必要なものであることがわかりました。
UPD:実践が示しているように、具体的な変更とテキストへの追加が必要です。 私は主要部分にわずかな変更のみを加え、記事の最後で新しい発見を共有することにしました。
Rsync + inotify = lsyncd
Lsyncdは、ローカルディレクトリの変更を監視し、それらを集約し、しばらくしてからrsyncがそれらの同期を開始するデーモンです。
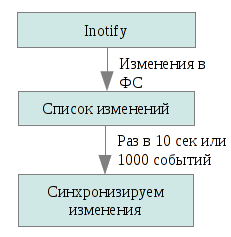
したがって、すべてを一度にrsyncすることはできませんが、変更されたもののみを更新できます。 Inotifyは、ファイルシステムの変更をアプリケーションに通知するカーネルサブシステムで、後者について通知します。 Lsyncdはローカルファイルツリーの変更のイベントを監視し、この情報を10秒で収集します(他の時間を指定できます)、または1000イベントが収集されるまで(いずれかのイベントが最初に発生するまで)、rsyncを実行してこれらのファイルをクラスター内の他のノードに送信します。 Rsyncはupdateパラメーターで始まります。つまり、受信者のファイルが新しい場合にのみ、受信者のファイルが送信されたファイルに置き換えられます。 これにより、衝突や不要な操作を回避することができます(たとえば、同じファイルが送信側と受信側の両方で並行して生成された場合)。
実装
Ubuntu 11.10のインストールプロセスについて説明します。 他のバージョンとは異なる場合があります。
1.許可なしで任意のノードから別のノードにログインできるようにsshを構成します 。 おそらく誰もがこれを行う方法を知っていますが、念のために説明します。
ssh-keygen
パスフレーズは空のままにします。
次に、〜/ .ssh / id_rsa.pubのコンテンツを〜/ .ssh / authorized_keys内のクラスター内の他のすべてのノードに追加します。 当然、同期フォルダーへの書き込み権限を持つユーザーに対して$ HOMEを選択します。 最も簡単な方法は/ルートの場合ですが、セキュリティの観点からは最良の選択ではありません。
すべてのノードを/ etc / hostsに登録することもお勧めします。 それらをnode01、node02、node03と呼びました。
すべてのノードで繰り返します。
2. lsyncdをインストールします
apt-get install lsyncd
3.設定は手動で作成する必要がありますが、非常に簡単です。 Lua言語で書かれています 。 lsyncdの作者からLuaを選んだ理由についてのコメントも興味深いものです。 また、ログ用に別のディレクトリを作成しました。
mkdir -p /etc/lsyncd mkdir -p /var/log/lsyncd vi /etc/lsyncd/lsyncd.conf.lua
コメント付きの構成の内容:
settings = {<br/> logfile = "/var/log/lsyncd/lsyncd.log", <br/> statusFile = "/var/log/lsyncd/lsyncd.status", <br/> nodaemon = true --<== . .<br/> } <br/> --[[<br/> sync { <br/> default.rsync, --<== rsync . -, - .<br/> source="/raid", --<== , <br/> target="node01:/raid", --<== dns- - <br/> rsyncOps={"-ausS", "--temp-dir=/mnt-is"}, --<== temp-dir .<br/> delay=10 --<== , <br/> } <br/> ]]<br/> sync { <br/> default.rsync, <br/> source="/raid", <br/> target="node02:/raid", <br/> rsyncOps={"-ausS", "--temp-dir=/mnt-is"}, <br/> delay=10 <br/> } <br/> <br/> sync { <br/> default.rsync, <br/> source="/raid", <br/> target="node03:/raid", <br/> rsyncOps={"-ausS", "--temp-dir=/mnt-is"}, <br/> delay=10<br/> }
構成を一度作成してからすべてのノードに配布し、特定のサーバーごとに余分なブロックをコメントアウトする方が簡単です。 コメントはすべて「-[[」と「]]」の間にあります。
使用されるrsync呼び出しオプション:
a-アーカイブモード。 -rlptgoDに相当します。つまり、アクセス権、グループ、所有者を保持しながら、シンボリックリンクと特殊ファイルとともに再帰的にコピーします。
u-受信者のファイルが新しい場合、それらを更新しません。
s-ファイル名にスペースが含まれる場合。
S-ゼロで構成されるデータの送信を最適化します。
詳細については、man lsyncdまたはドキュメントを参照してください。
4.すべてのメモでデーモンを開始します。
/etc/init.d/lsyncd start
構成に「nodaemon = true」のままにしておくと、何が起こっているかを確認できます。
次に、同期用に指定したディレクトリ内の何かをコピー/作成/削除し(I raid / raid)、数秒待ってから同期の結果を確認します。
データ転送速度は300 Mbit / sに達し、これはサーバー負荷にほとんど影響を与えません(たとえば、同じGlusterFSと比較して)。この場合の遅延はピークを滑らかにします。 さらに多くは、使用するFSに依存します。 ここでも、状況は非常に具体的であり、既存の公開されたテストの結果はタスクに必要なものを反映していないため、数値とグラフで少し調査する必要がありました。
他に何が考慮され、なぜこの場合に適合しないのか
この調査全体は、Amazon EC2の制限と機能を考慮して、Amazon EC2と連携することを目的としていたため、調査結果は主に彼女のみに関係しています。
- DRBD-レプリケーションはブロックレベルです。 1つのキャリアが劣化した場合、両方が殺されます。 2ノードの制限。 (さらに可能ですが、3番目と4番目はスレーブとしてのみ接続できます。)
- Ocfs2 -DRBD(Haberdに良い記事があります)経由で使用されるか、複数のノードから1つのパーティションをマウントできる必要があります。 ec2では不可能。
- Gfs2はocfs2の類似物です。 テストによれば、このFSはocfs2よりも遅いため、試したことはありません。
- GlusterFS-ここでは、ほぼすべてがすぐに機能しました。 シンプルで論理的な管理。 任意のレプリカ値を使用して、最大255ノードのクラスターを作成できます。 サーバーのペアからクラスターパーティションを作成し、それらを別のディレクトリにマウントしました(つまり、サーバーは同時にクライアントでもありました)。 残念ながら、クライアントでは、このクラスターはFUSEを介してマウントされ、書き込み速度は3 MB / s未満であることが判明しました。 そして、使用の経験はとても良いです。
- 光沢-このことをkrenelモードで実行するには、カーネルにパッチを適用する必要があります。 奇妙なことに、Ubuntuリポジトリにはこれらのパッチを含むパッケージがありますが、そのパッチ自体、または少なくともDebianのパッチは見つかりませんでした。 そして、レビューから判断して、私はそれを借金制度に入れることはシャーマニズムであることに気付きました。
- Hadoop w / HDFS、 Cloudera-別の解決策が見つかったため、試行しませんでした(以下を参照)。 しかし、あなたの目を引く最初のものはJavaで書かれているため、食べるリソースがたくさんあり、スケールはFacebookやYahuのようではなく、これまでに4つのノードしかありません。
UPD:このソリューションはテストでは優れていることがわかりました(その後記事が書かれました)が、戦闘状態ではすべてが完全に異なることが判明しました。 最小の実稼働構成は、584千のネストされたディレクトリです。 また、lsyncdは各ディレクトリでinotifyをハングさせます。 これをツリー全体ですぐに行うことは不可能です。 584千音のメモリは、(使用可能な16 GBのうち)約200 MBという比較的少ない消費量ですが、このプロセスには22分かかります。 原則として、それは怖いものではありません:始めたばかりで忘れていました。 しかし、その後、標準構成では、lsyncdはすべてのファイルの同期を開始します。これは、私たちの状況ではバグがあるか、数日かかりました。 一般的に-オプションではありません。 100%の一貫性は必須ではなく、最初の同期なしで実行できます。 それをオフにするために残った。 幸いなことに、デーモンは、その機能のほとんどすべてを構成から直接変更できるように作成されています。 また、パフォーマンスを向上させるために、default.rsyncはdefault.rsyncsshに置き換えられ、カーネルはinotify制限のためにnunyunになりました。 つまり、ほとんどのタスクでは上記の構成が適切ですが、特定の状況では次のように機能します。
settings = { logfile = "/var/log/lsyncd/lsyncd.log", statusFile = "/var/log/lsyncd/lsyncd.status", statusInterval = 5, --<== } sync { default.rsyncssh, source = "/raid", host = "node02", targetdir = "/raid", rsyncOps = {"-ausS", "--temp-dir=/tmp"}, --<== delay = 3, --<== -, init = function(event) --<== . log("Normal","Skipping startup synchronization...") --<== , end } sync { default.rsyncssh, source = "/raid", host = "node03", targetdir = "/raid", rsyncOps = {"-ausS", "--temp-dir=/tmp"}, delay = 3, init = function(event) log("Normal","Skipping startup synchronization...") end }
カーネル設定
Inotifyには3つのパラメーターがあります(ls / proc / sys / fs / inotify /を参照):
max_queued_events-キュー内のイベントの最大数。 デフォルト= 16384;
max_user_instances-1人のユーザーが実行できるinotifyインスタンスの数。 デフォルト= 128;
max_user_watches-1人のユーザーが追跡できるファイルの数。 デフォルト= 8192。
作業値:
echo " fs.inotify.max_user_watches = 16777216 # fs.inotify.max_queued_events = 65536 " >> /etc/sysctl.conf echo 16777216 > /proc/sys/fs/inotify/max_user_watches echo 65536 > /proc/sys/fs/inotify/max_queued_events
そのため、すべてがすでに生産で機能していました。
ご清聴ありがとうございました!