したがって、メモリの構成を理解するには、レジスタ、スタックなどの基本的な概念を理解する必要があります。 これも指で説明しようとしますが、この記事のトピックではないため、非常に簡単に説明します。 それでは始めましょう。
ご存知のように、プログラムを作成するプログラマは物理アドレスではなく、論理アドレスでのみ機能します。 そして、彼がアセンブラーでプログラミングしている場合。 同じCでは、プログラマーからのメモリセルはその利便性のために既にポインターによって隠されていますが、おおよそポインターを使用する場合、これはメモリーの論理アドレスの別の表現であり、Javaにはポインターがありません。これは本当に悪い言語です。 ただし、有能なプログラマは、少なくとも一般的なレベルでメモリがどのように構成されているかを知ることを妨げられません。 一般的に、マシンの仕組みがわからないプログラマーには非常に悲しくなります。通常、これらはベースボードの下に資格を持つJavaプログラマーやその他のphpの人たちです。
さて、悲しいことについては十分です。ビジネスに取り掛かりましょう。
32ビットプロセッサのプログラムモードのアドレス空間を考慮します(64ビットの場合、すべて類推による)
このモードのアドレス空間は、0〜2 ^ 32-1の番号が付けられた2 ^ 32個のメモリセルで構成されます。
プログラマはこのメモリを操作し、変数を定義する必要がある場合、アドレスを持つメモリセルにはそのようなデータ型が含まれると言いますが、プログラマ自身はこのセルが次のような値を書き込むかどうか分からない場合があります:
intデータ= 10;
コンピューターはこのように理解します。ストップの数を含むセルを取得し、整数10を入力する必要があります。さらに、セル18894のアドレスすら知らないため、非表示になります。
すべては問題ありませんが、メモリが異なる可能性があるため、コンピューターがこのメモリセルをどのように探すのかという疑問が生じます。
レベル3キャッシュ
レベル2キャッシュ
レベル1キャッシュ
主記憶
ハードドライブ
これらはすべて異なるメモリですが、コンピュータはintデータ変数がどれにあるかを簡単に見つけます。
この問題は、オペレーティングシステムとプロセッサを組み合わせることで解決されます。
これ以降の記事はすべて、このメソッドの分析に専念します。
x86アーキテクチャはスタックをサポートしています。
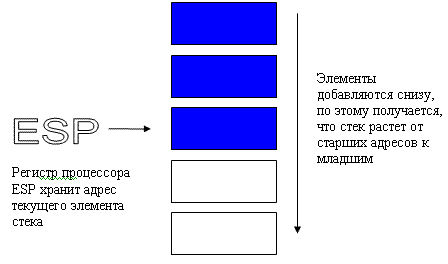
スタックとは、プレートのスタックの原理によって編成されたRAMの連続領域です。スタックの中央からプレートを取り出すことはできません。一番上にしかプレートを置くことができず、スタックの一番上にしか移動できません。
スタックを操作するためのプロセッサでは、特別なマシンコードが編成されます。アセンブラのニーモニックは次のようになります。
オペランドをプッシュ
オペランドをスタックにプッシュします
ポップオペランド
スタックの最上部から値を取得し、そのオペランドに入れます
メモリ内のスタックは上から下に成長します。つまり、値を追加するとスタックの上部のアドレスが減少し、そこから抽出するとスタックの上部のアドレスが増加します。
次に、レジスタとは何かを簡単に検討します。
これらは、プロセッサ自体のメモリセルです。 これは最速で最も高価なタイプのメモリです。プロセッサが値またはメモリを使用していくつかの操作を実行すると、これらの値をレジスタから直接取得します。
プロセッサには複数のロジックセットがあり、それぞれに独自のマシンコードと独自のレジスタセットがあります。
基本プログラムレジスタ(基本プログラムレジスタ)これらのレジスタは、整数データの処理に役立つすべてのプログラムで使用されます。
浮動小数点ユニットレジスタ(FPU)これらのレジスタは、浮動小数点形式で提示されるデータを処理します。
それでも、多数のオペランドで1つの命令を実行する必要がある場合、これらのレジスタが使用されるMMXおよびXMMレジスタがあります。
メインプログラムのレジスタについてさらに詳しく考えてみましょう。 これらには、8つの32ビット汎用レジスターが含まれます:EAX、EBX、ECX、EDX、EBP、ESI、EDI、ESP
データをレジスタに入れる、またはレジスタからメモリセルにデータを取り除くには、movコマンドを使用します。
mov eax、10
10をeaxレジスタにロードします。
movデータ、ebx
ebxレジスタに含まれる数値をデータメモリの場所にコピーします。
ESPレジスタには、スタックの最上位のアドレスが含まれています。
汎用レジスタに加えて、メインプログラムレジスタには6つの16ビットセグメントレジスタが含まれます:CS、DS、SS、ES、FS、GS、EFLAGS、EIP
EFLAGSは、フラグと呼ばれるビットを表示します。これは、プロセッサの状態を反映するか、前のコマンドの進行状況を特徴付けます。
EIPレジスタには、プロセッサによって実行される次のコマンドのアドレスが含まれています。
FPUレジスタは必要ないので、ペイントしません。 そのため、レジスタとスタックに関する小さな余談は終わりましたが、メモリの構成に戻ります。
覚えているように、この記事の目的は、論理メモリから物理メモリへの変換について説明することです。実際にはまだ中間段階があり、完全なチェーンは次のようになります。
論理アドレス->線形(仮想)->物理
線形アドレス空間全体がセグメント化されています。 各プロセスのアドレス空間には、少なくとも3つのセグメントがあります。
コードセグメント。 (実行されるプログラムのコマンドが含まれています。)
データセグメント。 (データ、つまり変数を含む)
上で書いたスタックセグメント 。

線形アドレスは次の式で計算されます。
線形アドレス=セグメントのベースアドレス(図ではセグメントの開始点)+オフセット
コードセグメント
コードセグメントのベースアドレスは、CSレジスタから取得されます。 コードセグメントのオフセット値は、命令のアドレスを格納するEIPレジスタから取得され、その後、このコマンドのサイズだけEIP値が増加します。 コマンドが4バイトを占める場合、EIP値は4バイト増加し、次の命令を示します。 これはすべて、プログラマーの参加なしに自動的に行われます。
メモリには複数のコードセグメントがある場合があります。 私たちの場合、彼は一人です。
データセグメント
データは、DS、ES、FS、GSレジスタにロードされます
これは、データセグメントが最大4倍になることを意味します。 私たちの写真では、彼は一人です。
データセグメント内のオフセットは、命令のオペランドとして指定されます。 デフォルトでは、DSレジスタが指すセグメントが使用されます。 別のセグメントを入力するには、セグメント置換プレフィックスコマンドでこれを直接指定する必要があります。
スタックセグメント
使用されるスタックセグメントは、SSレジスタの値によって設定されます。
このセグメント内のオフセットは、ESPレジスタによって表されます。ESPレジスタは、思い出すとスタックの最上部を指します。
メモリ内のセグメントは互いにオーバーラップする可能性があり、さらに、すべてのセグメントのベースアドレスが、たとえばゼロで一致する可能性があります。 このような縮退したケースは、メモリの線形表現と呼ばれます。 現代のシステムでは、メモリは通常この方法で編成されます。
今、セグメントのベースアドレスの定義を検討してください、それらはレジスタSS、DS、CSに含まれていると書きましたが、これは完全に真実ではありません、彼らはいくつかの16ビットセレクタを含みます。これは必要なアドレスがすでに格納されているセグメントの特定の記述子を示します。

これがセレクタの外観です。13ビットの記述子インデックスが記述子テーブルに含まれています。 2 ^ 13 = 8192がテーブル内の記述子の最大数であると計算するのは難しいことではありません。
一般的に、記述子テーブルにはGDTとLDTの2つのタイプがあります。1つ目はグローバル記述子テーブルと呼ばれ、システム内で常に1つのみであり、開始アドレス、またはゼロ記述子のアドレスは48ビットシステムレジスタGDTRに格納されます。 そして、システムが起動した瞬間から、システムは変化せず、スワップに参加しません。
ただし、記述子の値は異なる場合があります。 セレクタのTIビットがゼロの場合、プロセッサは単にGDTに移動し、このセグメントにアクセスするためにインデックスを使用して目的の記述子を検索します。
これまでのところ、すべてが単純でしたが、TIが1の場合、これはLDTが使用されることを意味します。 これらのテーブルは多数ありますが、LDTRシステムレジスタにロードされるセレクターは、GDTRとは異なり、変更できるため、現時点では使用されます。
セレクタインデックスは、セグメントのベースアドレスを指すのではなく、ローカル記述子テーブルが格納されているメモリ、より正確にはそのゼロ要素を指す記述子を指します。 それでは、すべてがGDTと同じです。 したがって、操作中に、必要に応じてローカルテーブルを作成および破棄できます。 LDTには、他のLDTの記述子を含めることはできません。
そのため、プロセッサが記述子に到達する方法がわかり、この記述子に含まれているものを図で確認できます。
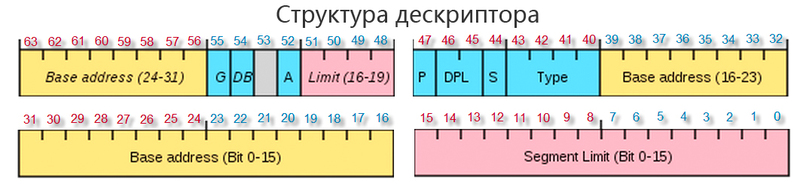
記述子は8バイトで構成されます。
ビット15-39および56-63には、このセグメント記述子で記述された線形ベースアドレスが含まれています。 線形アドレスを見つけるための式を思い出させてください:
線形アドレス=ベースアドレス+オフセット
この簡単な操作で、プロセッサは目的のリニアメモリアドレスにアクセスできます。
記述子の他のビットを考えてみましょう。セグメント制限または制限は非常に重要であり、0〜15および48〜51ビットの20ビット値を持ちます。 制限は、セグメントのサイズを設定します。 データおよびコードセグメントの場合、間隔内にあるすべてのアドレスが使用可能です。
[ベース; ベース+制限)
55 Gビット(粒度)に応じて、制限はゼロビット値でバイト単位で測定でき、最大制限は1 mb、または1の値で、制限はそれぞれ4 kbのページで測定されます。 そのようなセグメントの最大サイズは4GBになります。
スタックセグメントの場合、制限は次の範囲になります。
(ベース+制限;頂点]
ところで、なぜディスクリプタでベースとリミットが引き裂かれているのでしょうか。 実際、x86プロセッサーは進化的に進化し、286x記述子の時点で合計8ビットであり、最上位の2バイトが予約されていました。その後のプロセッサーモデルでは、ビット深度の増加とともに記述子も増加しましたが、下位互換性を維持するために、構造をそのままにしておく必要がありました。
「頂点」アドレスの値は、54番目のDビットに依存し、0の場合、頂点は0xFFF(64kb-1)、Dビットが1の場合、頂点は0xFFFFFFFF(4GB-1)です。
41〜43ビットでは、セグメントタイプがエンコードされます。
000-データセグメント、読み取り専用
001-データセグメント、読み取りおよび書き込み
010-スタックセグメント、読み取り専用
011-スタックセグメント、読み取りおよび書き込み
100-コードセグメント、実行のみ
101-コードセグメント、読み取りおよび実行
110-スレーブコードセグメント、実行のみ
111-スレーブコードセグメント、実行および読み取り専用
44 Sビットが1に等しい場合、ハンドルはRAMの実際のセグメントを表し、そうでない場合、Sビットの値は0です。
最も重要なビットは、47番目のPビットのプレゼンスです。 ビットが1の場合、セグメントまたはローカル記述子テーブルがRAMにロードされ、このビットが0の場合、このセグメントはRAMになく、ハードディスクにあり、割り込みが発生し、プロセッサの特別なケースが実行され、特別なケースハンドラが起動されます必要なセグメントをハードディスクからメモリにロードします。Pビットが0の場合、記述子のすべてのフィールドは意味を失い、サービス情報を自由に格納できます。 ハンドラーが完了すると、Pビットが1に設定され、記述子が再度アクセスされます。そのセグメントは既にメモリ内にあります。
これで論理アドレスの線形への変換が終了し、これは一見の価値があると思います。 次回は、線形から物理への変換の2番目の部分を説明します。
また、関数に引数を渡すこと、および変数をメモリに配置することについて少し話をする価値があると思います。メモリに変数を配置することは既に直接であるためです。システムプログラマーのための理論的な作成。 しかし、メモリの仕組みを理解しないと、これらの変数がメモリにどのように保存されているかを理解することは不可能です。
一般的に、私たちが再び会うまで、それが面白かったと思います。