 QRコードを読み取る必要があるときに、そのような状況が発生することがありますが、手元にスマートフォンはありません。 どうする? 手で読んでみようとするだけです。 誰かがそのような状況に遭遇した場合や、QRコードがマシンによってどのように読み取られるかについて興味がある場合は、この記事がこの問題の理解に役立ちます。
QRコードを読み取る必要があるときに、そのような状況が発生することがありますが、手元にスマートフォンはありません。 どうする? 手で読んでみようとするだけです。 誰かがそのような状況に遭遇した場合や、QRコードがマシンによってどのように読み取られるかについて興味がある場合は、この記事がこの問題の理解に役立ちます。
この記事では、コンピューターを使用せずにQRコードの基本機能と情報をデコードする方法について説明します。
イラスト:14、キャラクター:8 510。
QRコードが何であるかを知らない人のために、英語版ウィキペディアの良い記事があります。 また、Habréのテーマ別ブログや、 検索で見つけることができる関連トピックに関する優れた記事も読むことができます。
例として2つのコードを使用して、QR画像から情報を直接読み取る問題の解決策を検討します。 情報はオンラインジェネレーターQR Coder.ruでエンコードされました。
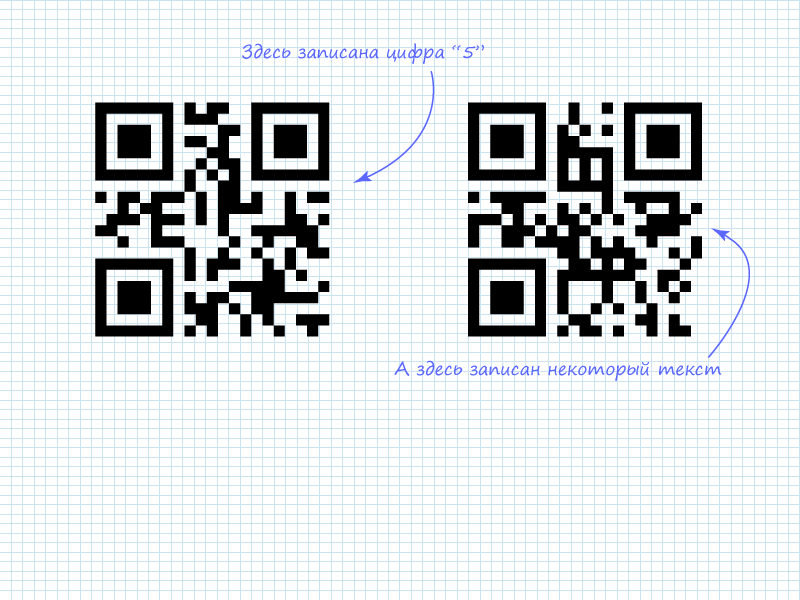
コードからデータを抽出する方法を理解するには、アルゴリズムを理解する必要があります。 QRコードファミリにはいくつかの標準があり、その基本原則は仕様に記載されています。 簡単に説明します。エンコードする必要があるデータは、エンコードモードに応じてブロックに分割されます。 モードとブロック数を示すヘッダーがブロックに分割されたデータに追加されます。 より複雑な情報配置の構造が使用されるようなモードもあります。 これらのモードから情報を手動で抽出することは実用的ではないため、これらのモードは考慮しません。 ただし、以下で説明する原則に基づいて、これらのモードに適応できます。
データの読み取りが正しくない場合、QRコードで特別なコードが使用され、読み取りの欠陥を修正できます。 これらは、いわゆるリードソロモンコードです。 情報ブロックのエラーを修正するだけでなく、コードの計算の原理については考慮しません。これは別の記事のトピックです。 リードソロモン(RS)エラー修正コードは、すべての情報データの後に記録されます。 これにより、情報を直接読み取るタスクが大幅に簡素化されます。コードに触れることなくデータを読み取ることができます。 実践が示すように、通常、QRマトリックスのほとんどは修正RSコードで占められています。
規格によれば、RSコード付きのデータは、画像に書き込まれる前に「混合」されます。 これらの目的のために、特別なマスクが使用されます。 8つのアルゴリズムがあり、そのうち最適なものが選択されます。 選択基準は、詳細なシステムに基づいています。これは、仕様で読むこともできます。
「混合」データは、テンプレート画像上に特別なシーケンスで記録され、そこにデバイスをデコードするための技術情報が追加されます。 説明したアルゴリズムに基づいて、QRコードからデータを抽出するためのスキームを区別できます。

ここでは、緑色のフェルトペンが、コードを直接読み取るときに実行する必要があるポイントを強調しています。 残りの項目は、読み取りが人によって行われるため、省略できます。
ステップ0。QRコード

写真を見ると、いくつかの異なる領域を見ることができます。 これらの領域は、QRコードを検出するために使用されます。 これらのデータは、記録された情報の観点からは重要ではありませんが、干渉しないように、それらを消すか、単にその場所を覚えておく必要があります。 コードフィールドの残りの部分には、有用な情報が含まれています。 システム情報とデータの2つの部分に分けることができます。 コードのバージョンに関する情報もあります。 コードに書き込むことができるデータの最大量は、コードのバージョンによって異なります。 アップグレードすると、たとえば次のような特別なブロックが追加されます。

それらの上で、QRのどのバージョンが目の前にあるかをナビゲートして理解できます。 高いバージョンのコードは、通常、手動で読み取ることも実用的ではありません。
システム情報の配置を図に示します:

システム情報が複製されるため、コードの検出および読み取り中にエラーが発生する可能性を大幅に減らすことができます。 システム情報は15ビットのデータで、そのうち最初の5つは有用な情報であり、残りの10はシステムデータのエラーを修正できるBCH (15,5)コードです。 RSコードもBCHコードとして分類されます。 図では、15ビットの2つのストリップが交差していないことに注意してください。
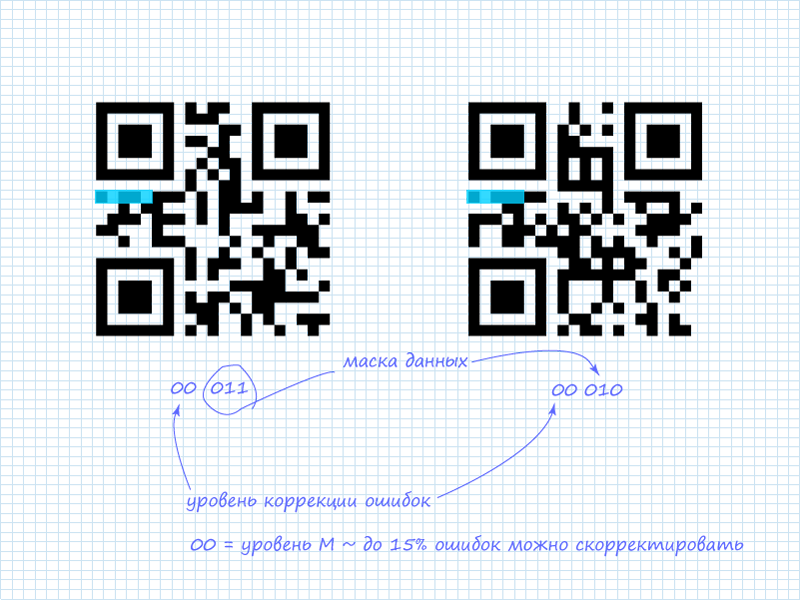
手順1. 5ビットのシステム情報を読み取る
すでに述べたように、最初の5ビットのみが対象です。 そのうち2ビットはエラー訂正のレベルを示し、残りの3ビットは利用可能な8のマスクがデータに適用されることを示します。 考慮されるQRコードでは、システム情報には以下が含まれます。

ステップ2.システム情報のマスク
システム情報を保護するための既に発表されたスキームに加えて、さらに、システム情報に適用される静的マスクが使用されます。 形式は101010000010010です。 最初の5ビットのみが対象であるため、マスクを短くして覚えやすくすることができます: 10101 ( 10-100 )。 「排他的OR」(xor)操作を適用した後、情報を取得します。
可能なエラー修正レベル:
| L | 01 |
| M | 00 |
| Q | 11 |
| H | 10 |
可能なマスク:
| 000 | (i + j)mod 2 = 0 |
| 001 | i mod 2 = 0 |
| 010 | j mod 3 = 0 |
| 011 | (i + j)mod 3 = 0 |
| 100 | ((i div 2)+(j div 3))mod 2 = 0 |
| 101 | (ij)mod 2 +(ij)mod 3 = 0 |
| 110 | ((ij)mod 2 +(ij)mod 3)mod 2 = 0 |
| 111 | ((i + j)mod 2 +(ij)mod 3)mod 2 = 0 |
ステップ3.データヘッダーの読み取り
処理するデータを理解するには、まずモードに関する情報を含む4ビットヘッダーを読む必要があります。 データの読み取りの詳細を図に示します。

可能なモードのリスト:
| ECI | 0111 |
| 数値 | 0001 |
| 英数字 | 0010 |
| 8ビット(バイト) | 0100 |
| 漢字 | 1000 |
| 構造化された加算 | 0011 |
| Fnc1 | 0101(1番目の位置)
1001(2番目の位置) |
ステップ4.マスクをヘッダーに適用する
モードを説明する4ビットを抽出した後、それらにマスクを適用する必要があります。
この場合、2つのマスクは異なるマスクを使用します。 マスクは上の表の式で定義されます。 この式が座標(i、j)のビットに対してTRUE(true)に減少する場合、ビットは反転されます。それ以外の場合、すべては変更されません。 左上隅の原点(0,0) 。 式を見ると、それらのパターンに気付くことができます。 問題のQRコードの場合、マスクは次のようになります。
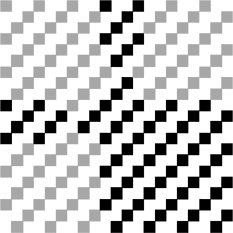

モードを取得します:

ステップ5.データの読み取り
モードに関するデータを受信した後、情報の読み取りを開始できます。 数値データと英数字データは簡単に解釈できるため、数値データと英数字データを読むことは最も興味深いことに注意してください。 しかし、8ビットも恐れないでください。 簡単に解釈できる情報でもあります。 たとえば、多くのオンラインQRテキストジェネレーターは、 ASCIIを使用してこのモードでエンコードします。 最初にモードを読み取る必要があるもう1つの理由は、データパケットの数がモードに依存していることです。 これは、コードのバージョンにも依存します。 より読みやすいモードのブロック1〜9のバージョンの場合:
| 数値 | 10ビット/ 4ビット |
| 英数字 | 9ビット |
| 8ビット(バイト) | 8ビット |
モードポインターの後の最初のブロックは文字数です。 数値モードの場合、数値は次の10ビットでエンコードされ、8ビットモードの場合は8ビットでエンコードされます(トートロジーについては謝罪します)。

この図は、左のQRコードに記載されているように、数字5が書き留められていることを示しています。これは、文字数インジケーターとそれに続く4ビットで確認できます。 10ビットボリュームが必要ない場合、10ビットブロックと共に数値モードでは、スペースを節約するために4ビットブロックが使用されます。 4文字が正しいコードで暗号化されています。 現時点では、暗号化されているものはわかりません。 したがって、次の列の読み取りに進み、4つの情報ブロックすべてを抽出する必要があります。

この図は、4つのパッケージすべてが「habr」という単語を形成するASCIIラテン文字であることを示しています
当然、携帯電話をポケットから取り出して、カメラをQR画像に向けて、すべての情報を読み取るのが最善の方法です。 ただし、緊急の場合には、説明した手法が役立つ場合があります。 もちろん、モードのすべてのインデックスとマスクの種類、およびASCII文字を頭の中に保持するわけではありませんが、一般的な組み合わせ(少なくとも記事で説明されている組み合わせ)を覚えておくことができます。
仕様:
BS ISO / IEC 18004:2006。 情報技術。 自動識別およびデータキャプチャテクニック。 QR Code 2005バーコード記号仕様。 ロンドン:BSI。 2007. p。 126. ISBN 978-0-580-67368-9。
PSリソースルールとCreative Commons Attribution 3.0 Unported(CC BY 3.0)の条件に従ってください
PPSブログを間違えた場合、どこに教えてください-転送します。