 QNXリアルタイムオペレーティングシステムに関する一連の注意事項の続き。 今回は、QNX6でのスレッドスケジューリングについて説明したいと思います* 。 読者( シリーズの前の記事を読んだ読者)が既に知っているように、QNX6マイクロカーネルはプロセスではなくスレッドを制御します。 そして、次の瞬間に制御を受け取るべきスレッドのコンテキストをロードするのはマイクロカーネルです。 プロセッサによって実行される(つまり、プロセッサ時間を積極的に使用する)スレッドの選択は、スレッドのスケジューリングです。
QNXリアルタイムオペレーティングシステムに関する一連の注意事項の続き。 今回は、QNX6でのスレッドスケジューリングについて説明したいと思います* 。 読者( シリーズの前の記事を読んだ読者)が既に知っているように、QNX6マイクロカーネルはプロセスではなくスレッドを制御します。 そして、次の瞬間に制御を受け取るべきスレッドのコンテキストをロードするのはマイクロカーネルです。 プロセッサによって実行される(つまり、プロセッサ時間を積極的に使用する)スレッドの選択は、スレッドのスケジューリングです。
スレッドのスケジューリングが発生したとき
QNX Neutrinoマイクロカーネルは継続的に動作しませんが、システムコール、例外、および割り込みの場合にのみ制御を受け取ります。 また、作業中の小核はフロー計画を実行します。 このことから、スケジューリングフローの操作はそれ自体ではなく、何らかのイベントによって発生するという正しい結論を下すことができます。 実際、そのようなイベントはほとんどありません。
- 混み合っています。 現在実行中のスレッドよりも高い優先度を持つスレッドが準備完了状態(READY)になった場合、マイクロカーネルは現在実行中のスレッドを停止し、コンテキストを切り替え、より高い優先度でスレッドを開始します。 以前に実行されていたスレッドは、実行キューの最初に残ります。
- ブロッキング。 実行中(つまり、操作中)にスレッドがブロックを引き起こす関数を呼び出す場合があります。 たとえば、システム関数
MsgSend()
を使用して(直接的または間接的に)セマフォのキャプチャまたはメッセージの送信を試みます。 この場合、カーネルはそのようなプロセスを実行キューから削除し、制御を別のスレッドに転送します。 - 割り当て (コントロールの譲渡、収益)。 スレッドは、
sched_yield()
関数を呼び出すと、制御を自発的に転送できます。 この場合、スレッドは実行キューの最後に配置され、マイクロカーネルは制御を別のスレッド(制御を与えたばかりのスレッド)に転送します。
計画に影響するフローパラメータ
QNX Neutrinoマイクロカーネルの主な機能の1つ( およびメッセージング後のおそらく最も重要な機能)は、スレッドスケジューリングです。 コンテキストを切り替えて、次の時点で実行するスレッドを選択するのはマイクロカーネルです。 マイクロカーネルは、これをすべて同様に行うのではなく、左ヒールの要求ではなく、次のフローパラメータに基づいて行います。
- ストリームの優先度 (ストリームの優先度レベル)。 QNX6 RTOSの各スレッドは、特定の優先度で実行されます。 優先度が高いほど、スレッドが最初にプロセッサを取得する可能性が高くなります。 システムにREADY状態(実行準備完了)のスレッドが2つ以上ある場合、マイクロカーネルは優先度の高いスレッドに制御を移します。
- 計画の規律。 システム内の各スレッドは、特定の計画規律で実行されます。 システム内に同じ優先度で実行されているREADY状態のスレッドが2つ以上ある場合、マイクロカーネルは計画の規律を考慮します。
procnto
-p
オプションを指定します。 ゼロ(最低)の優先度では、
idle
スレッドが実行され、システムにREADY状態でより高い優先度のスレッドがなくなると、常に制御が行われることに注意してください。
QNX6オペレーティングシステムは、 FIFO 、カルーセル(サイクリック、ラウンドロビン、RR)および散発的な**の複数のフロープランニングの分野をサポートしています。 このスレッド属性は、マイクロカーネルが同じ優先度レベルのスレッドから選択する必要がある場合にのみ考慮されます。 計画分野については後述します。
スイッチングフローの順序に影響する別の要因があります。 プロセッサを実行して使用する準備ができているすべてのスレッド(READY状態のスレッド)はキューに入れられます。 システムには256個のそのようなキューがあります(優先度の数による)。 すべてが等しく、マイクロカーネルが同じ優先度レベルを持つ2つのスレッドから選択する必要がある場合、キューの最初のスレッドが実行を開始します。 繰り返しますが、ストリームの混雑が優先されると、キューの最初に配置され、割り当て時に(
sched_yield()
呼び出すことにより)、ストリームはキューの最後になります。
FIFO計画規律
フローにFIFOスケジューリング規則(先入れ先出し、先入れ先出し)が指定されている場合、必要な限り実行できます。 制御が別のスレッドに移るのは、スレッドが優先度の高いスレッドに取って代わられるか、ブロックされるか、自発的に制御を放棄する場合のみです。 この計画規律を使用すると、長時間の数学的計算を実行するスレッドはプロセッサを完全にキャプチャできます(つまり、同じ優先度と低い優先度のスレッドは許可されません)。
カルーセル訓練計画
この計画規律はFIFOに完全に似ていますが、スレッドが「際限なく」実行されず、特定のタイムスロット(タイムスライス)でのみ機能する点が異なります。 タイムクォンタムが終了すると、小核はプロセスを実行可能なスレッドのキューの最後に配置し、制御は次のスレッド(同じ優先度レベル)に転送されます。 この優先度レベルでREADY状態の他のスレッドが存在しない場合、別のスレッドにタイムスライスが割り当てられます。
操作のスケジューリングのカルーセル規則でスレッドに割り当てられる時間の量は、
sched_rr_get_interval()
関数を使用して決定できます。 実際、タイムスライスはticksizeのちょうど4倍です。 同様に、クロック間隔は、40MHz以上のプロセッサを搭載したシステムでは1ms、低速のプロセッサを搭載したシステムでは10msです*** 。 通常のx86コンピューターおよびラップトップでは、タイムクォンタムは4ミリ秒です。
散発的な計画規律
FIFOスケジューリングのように、散発的なスケジューリングが適用されるスレッドは、ブロックされるか、より高い優先度のスレッドに置き換えられるまで実行されます。 さらに、適応計画の場合と同様に、散発的な計画が適用されるフローの優先順位は低くなります。 ただし、散発的な計画では、フロー制御が大幅に正確になります。
散発的な計画では、スレッドの優先度は、フォアグラウンドの優先度(フォアグラウンド、通常の優先度)とバックグラウンド(低い)優先度の間で動的に変更できます。 この散発的な遷移を制御するには、次のパラメーターを使用します。
- スレッドの初期予算(初期予算)(C)-低い優先度(L)を取得する前にスレッドが通常の優先度(N)で実行できる時間。
- 低優先度 (L)-ストリームの優先度を下げる優先度レベル。 優先度(L)が低いと、スレッドはバックグラウンドで実行されます。 スレッドに通常の優先度(N)がある場合、フォアグラウンドの優先度で実行されます。
- 補充期間(T)-スレッドが実行予算を費やすことができる期間。
- 現在の補充の最大数(保留中の補充の最大数)-この値は、実行される補充操作の数に制限を設定し、それによって散発的な計画の分野に割り当てられるシステムリソースの量を制限します。
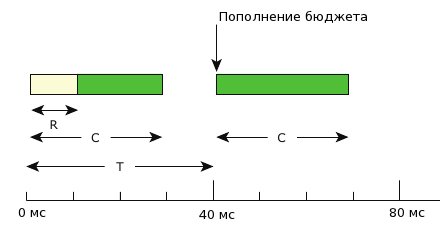
図 1. フロー実行期間の補充は定期的に発生します
通常の優先度Nでは、スレッドは初期実行予算Cで設定された期間実行されます。この期間が終了すると、補充操作が発生するまでスレッドの優先度は低レベルLに下げられます。
たとえば、フローが決してブロックまたは中断されないシステムを想像してください-図 2。
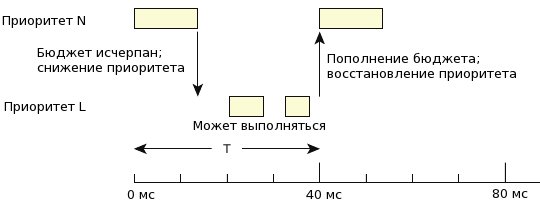
図 2. スレッドの優先度は、実行予算が補充されるまで低下します。
この場合、スレッドはより低い優先度(バックグラウンドモード)のレベルに移動し、その実行はシステム内の他のスレッドの優先度に依存します。
補充が発生するとすぐに、フローの優先度が初期レベルに上がります。 したがって、適切に構成されたシステムでは、スレッドは期間Cごとに最大時間C実行されます。これにより、優先度Nで実行されるすべてのスレッドがシステムリソースのC / Tパーセントのみを使用します。
スレッドが数回ブロックされると、異なる時点で複数の補充操作が発生する可能性があります。 これは、期間T内のフロー実行予算がCの値に達することを意味する場合があります。 ただし、この期間中、予算は継続的でない場合があります。

図 3. フローの優先度は、高と低の間で異なります
図 図3は、40ミリ秒の補充期間Tごとに、ストリームCの実行の予算が10ミリ秒であることを示しています。
- フローは3ミリ秒後にブロックされるため、3ミリ秒の補充操作は40ミリ秒で実行されるようにスケジュールされます。 その時点で、最初の補充期間の完了。
- フローの実行は6ミリ秒で再開し、この瞬間は次の補充期間Tの始まりを示します。フロー実行の予算にはまだ7ミリ秒のマージンがあります。
- フローはブロックせずに7ミリ秒間実行され、その結果、フロー実行バジェットが使い果たされ、フローの優先度がレベルLに低下します。レベルLでは、制御を取得できる、または取得できません。 46ミリ秒(40 + 6)に7ミリ秒の補充が計画されています。 期間Tの後
- 40ミリ秒で、フローバジェットが3ミリ秒補充されます(図のステップ1を参照)。その結果、フローの優先度は通常に上昇します。
- スレッドは予算の3ミリ秒を費やしてから、優先度の低い方に切り替えます。
- 46ミリ秒で、スレッドバジェットが7ミリ秒補充され(ステップ3を参照)、スレッドは再び通常の優先順位を受け取ります。
プログラムから計画の優先順位と規律を設定する方法
起動時の各スレッドは、親スレッドから優先順位と計画規律を継承します。 操作中に、スレッドはこれらの属性を変更する場合があります。 この目的のために、QNX6には次の機能があります。
| POSIX呼び出し | 説明 |
|---|---|
sched_getparam()
| 優先順位を取得します。 |
sched_setparam()
| 優先度を設定します。 |
sched_getscheduler()
| 計画の規律を取得します。 |
sched_setscheduler()
| 計画の規律を確立します。 |
SchedGet()
および
SchedSet()
使用できます。
ちょっとした管理
前回の投稿で、私はすでに
pidin
コマンドについて言及しました。 今回は、QNXに固有の2つのチームに会います。 すべてのQNX6管理者は、これらのコマンドを知っており、使用できる必要があります。 そして、おそらく最も重要なコマンドは
use
です。
use
ユーティリティは、何らかの方法で
man
コマンドに類似しています。 このユーティリティを使用すると、実行可能モジュール(バイナリ実行可能ファイル、スクリプト、または共有ライブラリ)に関するヘルプを取得できます。
use
の原則は、
man
use
多少異なり
use
すべてのヘルプ情報は、個別ではなく、実行可能モジュール自体に保存されます。 コマンドは、非常に単純に、たとえば次のように呼び出されます。
# use sleep sleep - suspend execution for an interval (POSIX) sleep time Where: time is the number of seconds to sleep and can be a non-negative floating point number (0 <= time <= 4294967295).
ユーティリティユーティリティは、コマンドの操作に関する小さなヘルプを表示します;完全な説明はヘルプシステムで利用可能です。
すべての自尊心のあるQNX6管理者の武器にならなければならないもう1つの便利なコマンドは
pidin
です。 このユーティリティは、実行スレッドやプロセスなど、システムに関するさまざまな種類の情報を提供します(この場合、ユーティリティは
ps
ユーティリティに似ています)。 たとえば、システムに関する一般情報を表示するには、次のコマンドを実行する必要があります。
# pidin in CPU:X86 Release:6.5.0 FreeMem:166Mb/255Mb BootTime:Jul 05 15:53:27 MSKS 2011 Processes: 43, Threads: 107 Processor1: 131758 Pentium II Stepping 5 2593MHz FPU
パラメータなしでユーティリティを呼び出すと、すべてのプロセスとスレッドに関する情報が表示されます。 対象のプロセスに関する情報を取得するには、たとえば、
-P
スイッチを指定するだけです。
# pidin -P io-audio pid tid name prio STATE Blocked 90127 1 sbin/io-audio 10o SIGWAITINFO 90127 2 sbin/io-audio 10o RECEIVE 1 90127 3 sbin/io-audio 10o RECEIVE 1 90127 4 sbin/io-audio 10o RECEIVE 1 90127 5 sbin/io-audio 50r INTR 90127 6 sbin/io-audio 50r RECEIVE 7
プロセスがメモリを使用する方法を確認するには、次のコマンドを実行します。
# pidin -P io-audio mem pid tid name prio STATE code data stack 90127 1 sbin/io-audio 10o SIGWAITINFO 128K 112K 8192(516K)* 90127 2 sbin/io-audio 10o RECEIVE 128K 112K 4096(132K) 90127 3 sbin/io-audio 10o RECEIVE 128K 112K 8192(132K) 90127 4 sbin/io-audio 10o RECEIVE 128K 112K 4096(132K) 90127 5 sbin/io-audio 50r INTR 128K 112K 4096(132K) 90127 6 sbin/io-audio 50r RECEIVE 128K 112K 4096(132K) libc.so.3 @b0300000 472K 12K a-ctrl-audiopci.so @b8200000 12K 4096 deva-mixer-ac97.so @b8204000 24K 8192
使用されている共有ライブラリに関する情報も表示されます。 私の意見では、とても便利です。
pidin
ユーティリティは、多くのコマンドとオプションをサポートしています。
pidin
リストと説明は、QNXヘルプシステムにあります。
そして、最後ではあるが、価値ではなく、
slay
ユーティリティです。 ご想像のとおり、このコマンドはプロセスにシグナルを送信するために使用されます。 デフォルトでは、SIGTERMシグナルが送信され、通常はプロセスの終了につながります。 プロセスに送信する必要がある別のシグナルを指定できます。 この使用法では、
slay
killコマンドに似ていますが、最も興味深いことに、 slayコマンドはプロセス識別子(PID)だけでなく、プロセスの名前も受け入れます。 これは管理にも非常に便利です。 信号の送信に加えて、ユーティリティを使用して、プロセス計画の優先順位または規律を変更できます。 単一のストリームの特性を変更する場合は、
-T
スイッチを指定できます。 次のいくつかのコマンドは、3つの
io-audio
プロセススレッドのスケジューリングの優先順位と規律を変更します。
[22:47:33 root]# pidin -P io-audio pid tid name prio STATE Blocked 90127 1 sbin/io-audio 10o SIGWAITINFO 90127 2 sbin/io-audio 10o RECEIVE 1 90127 3 sbin/io-audio 10o RECEIVE 1 90127 4 sbin/io-audio 10o RECEIVE 1 90127 5 sbin/io-audio 50r INTR 90127 6 sbin/io-audio 50r RECEIVE 7 [22:47:36 root]# slay -T 3 -P 11r io-audio [22:47:38 root]# pidin -P io-audio pid tid name prio STATE Blocked 90127 1 sbin/io-audio 10o SIGWAITINFO 90127 2 sbin/io-audio 10o RECEIVE 1 90127 3 sbin/io-audio 11r RECEIVE 1 90127 4 sbin/io-audio 10o RECEIVE 1 90127 5 sbin/io-audio 50r INTR 90127 6 sbin/io-audio 50r RECEIVE 7
slay
ユーティリティの詳細な説明は、QNXヘルプシステムにあります。
念のため、QNX6にはおなじみのUNIX
ps
と
kill
ユーティリティもあります。 ただし、QNX6を使用する方が、
pidin
や
pidin
よりもはるかに便利です。 システムの詳細を考慮します。
おわりに
この記事を読んだ後、QNX6のスレッドスケジューリングのアイデア、計画の優先順位と分野、システム機能とプロセスとスレッドを管理するためのユーティリティに関する十分な知識が得られました。 QNXには、興味深い技術であるアダプティブパーティショニング(適応分解)もあります。これにより、プロセスのグループを形成し、それらにCPU時間の割合を割り当てることができます。 すべてを統合しないために、この技術を次のメモのいずれかで説明します。
参照資料
- リアルタイムオペレーティングシステムQNX Neutrino 6.3。 システムアーキテクチャ。 ISBN 5-94157-827-X
- リアルタイムオペレーティングシステムQNX Neutrino 6.3。 ユーザーマニュアル。 ISBN 978-5-9775-0370-9
- Rob Krten、「QNX Neutrinoの紹介2.リアルタイムアプリケーション開発者向けガイド」、第2版。 ISBN 978-5-9775-0681-6
*この記事のQNX6はQNX 6.5.0を指します。 QNX Neutrinoカーネルは次のバージョンのいずれかで変更できるため、ここで説明するフロープランニングメカニズムは変更される可能性があります。
** QNX6には、ラウンドロビン(ラウンドロビン、RR、r)と同じ別の計画規律(OTHER、o)もあります。
***クロック間隔(ティックサイズ)は、たとえば
ClockPeriod()
関数を使用して変更できます。