
1対多の原則に従って相互接続されたエンティティAとBがあるとします。 これらのエンティティのインスタンスの数は非常に多くなります。 ユーザーにエンティティを表示する場合、エンティティAとエンティティBの両方に対して、多数の独立した基準を適用する必要があります。さらに、基準を適用した結果は、数百万レコードの十分に高いパワーのセットです。 フィルタリング基準とソート原則は、ユーザーが設定します。 0秒以内にこれらすべてをユーザーに表示するにはどうすればよいですか(1つの画面で何百万ものレコードが必要なのはなぜですか?
このような問題を解決することは常に興味深いですが、その解決策はデータベースが実行されているDBMSに大きく依存しています。 オラクルの形であなたの袖にエースがあれば、彼がこれらの松葉杖を自分で置き換える可能性があります。 しかし、現実には、MySQLしか持っていないので、理論を読む必要があります。
sqlを使用すると、タスクは次のように定式化できます。
drop table if exists pivot;
drop table if exists entity_details;
drop table if exists entity;
create table pivot
(
row_number int (4) unsigned auto_increment,
primary key pk_pivot (row_number)
)
engine = innodb;
insert into pivot(row_number)
select null
from information_schema.global_status g1, information_schema.global_status g2
limit 500;
create table entity(entt_id int (10) unsigned auto_increment,
order_column datetime,
high_selective_column int (10) unsigned not null ,
low_selective_column int (10) unsigned not null ,
data_column varchar (32),
constraint pk_entity primary key (entt_id)
)
engine = innodb;
create table entity_details(edet_id int (10) unsigned auto_increment,
det_high_selective_column int (10) unsigned not null ,
det_low_selective_column int (10) unsigned not null ,
det_data_column varchar (32),
entt_entt_id int (10) unsigned,
constraint pk_entity_details primary key (edet_id)
)
engine = innodb;
insert into entity(order_column,
high_selective_column,
low_selective_column,
data_column
)
select date_add(str_to_date("20000101", "%Y%m%d"),
interval (p1.row_number + (p2.row_number - 1) * 300 + (p3.row_number - 1) * 300 * 300) second
)
order_column,
round((p1.row_number + (p2.row_number - 1) * 300 + (p3.row_number - 1) * 300 * 300) / 3, 0)
high_selective_column,
(p1.row_number + (p2.row_number - 1) * 300 + (p3.row_number - 1) * 300 * 300) mod 10 low_selective_column,
p1.row_number + (p2.row_number - 1) * 300 + (p3.row_number - 1) * 300 * 300 data_column
from ( select * from pivot limit 300) p1,
( select * from pivot limit 300) p2,
( select * from pivot limit 300) p3;
insert into entity_details(det_high_selective_column,
det_low_selective_column,
det_data_column,
entt_entt_id
)
select e.high_selective_column + p.row_number det_high_selective_column,
case when e.low_selective_column = 0 then 0 else p.row_number end det_low_selective_column,
concat(e.data_column, ' det' ) det_data_column,
e.entt_id
from entity e,
( select * from pivot limit 2) p;
create index idx_entity_details_entt
on entity_details(entt_entt_id);
select *
from entity_details ed, entity e
where ed.entt_entt_id = e.entt_id
order by order_column desc
limit 0, 10;
額の照会計画は慰めません。
| id | select_type | テーブル | タイプ | possible_keys | 鍵 | key_len | ref | 行 | 追加 |
| 1 | シンプル | e | すべて | プライマリ | 26982790 | ファイルソートの使用 | |||
| 1 | シンプル | 編 | ref | idx_entity_details_entt | idx_entity_details_entt | 5 | test.e.entt_id | 1 | どこを使うか |
不要なインデックスの束を混乱させる前に、2つのテーブルに基づいてこのような問題を解決できるかどうかを分析しましょう。 最初のテーブルにエンティティの特性を保存し、2番目のテーブルにその詳細を保存します。 通常、参照整合性を確保するために制約を使用する必要がありますが、大量のデータと定数DMLを含むこの種類のテーブルが2つある場合、 Not a BUG#15136のため、これはお勧めしません 。 また、危険なinnodb_locks_unsafe_for_binlogパラメーターを明示的にtrueに設定してデータベースを読み取りコミットモードにすると、保存されません。 さて、これは羊の話です。 まず、ドキュメントを見てみましょう- 注文を高速化するためのオプションは何ですか?
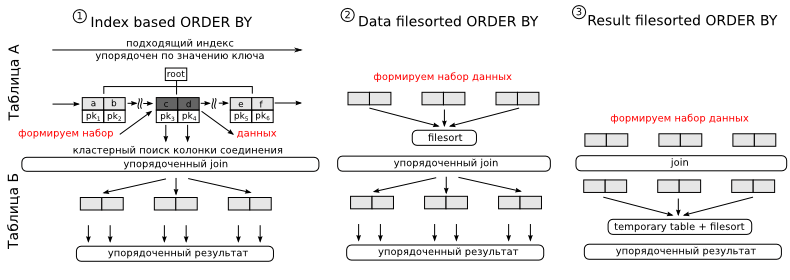
オプション1。インデックスがあり、最初のフィールドがwhereにリストされている列であり、最後の列がソートが行われているとします。 インデックス内のデータはソートされた形式で保存されるため、MySQLはそれを使用してソートを最適化できます。 作業のアルゴリズムは次のようになります。 アクセス述語を使用して、必要なインデックスのセクションを見つけます。 プランでは、 typeカラムにrange 、 ref 、またはindexが表示されます。 次のバッチのデータを取得し、ランタイムモードで、結合を完了するために必要な残りの列を読み取り(インデックスに必要な列がすべてない場合があるため、論理的に聞こえます)、次の表に接続します。 インデックスからデータを順番に読み取るため、このような結合の出力は順序付けられた形式で取得されます。 適切な量のデータを取得したら、インデックスの読み取りを停止できます。 私たちにとって、このアプローチの主な欠点は、検索が実行される列とソートが実行される列が異なるテーブルにあることです。 したがって、非正規化を行う必要があります。
オプション2と3は、接続のデータ量が少ない場合にのみ適しています。 高度に選択的なスピーカーにのみ適しています。 オプション2では、結果を最初に並べ替えてから結合を実行し、オプション3では、結合後に並べ替えを行います。 MySQLによって実行されるソートは1つのテーブルでのみ実行できるため、3番目のケースでは一時テーブルが必要です。 これは恐ろしいことではありませんが、多くを引きずることができます。 ただし、MySQLがさまざまな最適化を適用して結合を高速化できる場合、3番目のケースが唯一の可能なオプションです。 最初の2つのケースでは、ネストされたループになります。 実行に関して、これらのソートは次のように異なります。
| インデックスを使用して並べ替える | 空です |
| テーブルAにfilesortを使用する | 「filesortの使用」 |
| JOIN結果を一時テーブルに保存し、filesortを使用する | 「一時的な使用。 ファイルソートの使用” |
2番目と3番目のソート方法では、制限はソートプロセスの最後にのみ適用できます。このため、オプション2と3はすべての場合に使用できるわけではありません。
不可解なファイルソートは、クイックソートマージにすぎません。

ソートは2つの方法で実行できます。 最初に、ソートが最初に行われ、次にテーブルから残りのデータが読み取られます。これは、クエリを完了するために必要です。 2番目のオプションは最適化されていると見なされます。これは、テーブルが必要なすべての列とともに1回読み取られてからソートされるためです。 計画によれば、それらを互いに区別することはできませんが、簡単な実験によってこれを行うことができます。 しかし、最適化されたソートが適用されるかどうかに関係なく、 max_length_for_sort_dataパラメーターは答えます 。 タプルに含まれるデータがこのパラメーターで指定されたものよりも少ない場合、ソートは最適化されます。
drop procedure if exists pbenchmark_filesort;
delimiter $$
create procedure pbenchmark_filesort(i_repeat_count int (10))
main_sql:
begin
declare v_variable_value int (10);
declare v_loop_counter int (10) unsigned default 0;
declare continue handler for sqlstate '42S01' begin
end ;
create temporary table if not exists temp_sort_results(
row_number int (10) unsigned
)
engine = memory;
truncate table temp_sort_results;
select variable_value
into v_variable_value
from information_schema.session_status
where variable_name = 'INNODB_ROWS_READ' ;
begin_loop:
loop
set v_loop_counter = v_loop_counter + 1;
if v_loop_counter <= i_repeat_count then
insert into temp_sort_results(row_number)
select sql_no_cache row_number from pivot order by concat(row_number, '0' ) asc ;
truncate table temp_sort_results;
iterate begin_loop;
end if ;
leave begin_loop;
end loop begin_loop;
select variable_value - v_variable_value records_read
from information_schema.session_status
where variable_name = 'INNODB_ROWS_READ' ;
end
$$
delimiter ;
set session max_length_for_sort_data = 0;
call pbenchmark_filesort(10000);
-- records_read
-- 10 000 000
-- 0:00:12.317 Query OK
set session max_length_for_sort_data = 1024;
call pbenchmark_filesort(10000);
-- records_read
-- 5 000 000
-- 0:00:06.228 Query OK
この例からわかるように、アルゴリズム番号2によるソートは、読み取りが2倍少ないため、実際には2倍高速です。 ただし、最適化された並べ替えにはかなりのメモリコストが必要であり、変数max_length_for_sort_dataの値を高すぎる値に設定すると、完全に単純なプロセッサーで多くの入出力が得られることに留意してください。
そのため、利用可能なソリューションを最大限に活用します。 非正規化を行っています(どのようにサポートするか、これは別の問題です)。 また、非選択スピーカー用の複合インデックスと、高選択スピーカー用の通常のインデックスを作成します。 したがって、インデックスによる並べ替えと制限による制限は、選択性の低い列のみが関係する基準のクエリに使用され、選択性の高い列の場合は、よりコンパクトで高速なインデックスが使用され、その後、マージせずにシングルパスのファイルソートが行われます。
create table entity_and_details(entt_entt_id int (10) unsigned not null ,
edet_edet_id int (10) unsigned not null ,
order_column datetime,
high_selective_column int (10) unsigned not null ,
low_selective_column int (10) unsigned not null ,
det_high_selective_column int (10) unsigned not null ,
det_low_selective_column int (10) unsigned not null ,
constraint pk_entity_and_details primary key (entt_entt_id, edet_edet_id)
)
engine = innodb;
insert into entity_and_details(entt_entt_id,
edet_edet_id,
order_column,
high_selective_column,
low_selective_column,
det_high_selective_column,
det_low_selective_column
)
select entt_id,
edet_id,
order_column,
high_selective_column,
low_selective_column,
det_high_selective_column,
det_low_selective_column
from entity_details ed, entity e
where ed.entt_entt_id = e.entt_id;
create index idx_entity_and_details_low_date
on entity_and_details(low_selective_column, order_column);
create index idx_entity_and_details_det_low_date
on entity_and_details(det_low_selective_column, order_column);
create index idx_entity_and_details_date
on entity_and_details(order_column);
create index idx_entity_and_details_high
on entity_and_details(high_selective_column);
create index idx_entity_and_details_det_high
on entity_and_details(det_high_selective_column);
残念ながら、非正規化の後、1つの欠点がありました。 ページレイアウトは、1つのエンティティの詳細を異なるページに分散させることができます。 私たちはこれを許すことはできません。したがって、私は教会をさらに発展させることを提案します。 必要なすべてのデータを一度に選択する代わりに、すべての基準の条件を持つエンティティAの識別子のみを選択し、ページングの制限構造に追加してから、エンティティの詳細を取得します。
select distinct entt_entt_id
from entity_and_details
where det_low_selective_column = 0
order by order_column
limit 0, 3;
select *
from entity_and_details
where entt_entt_id in (10, 20, 30);
率直に言って、私の考えでは、そのようなボリュームのテーブルでの明確な + オーダー + 制限という形式の設計はすぐには機能しませんが、MySQL開発者は異なる考え方をしています。 この問題に取り組んでいるときに、 Not a BUG#33087バグに遭遇しました 。これは通常どおり、バグではなく機能であることが判明しました。 その後、MySQLがdistinctを最適化する方法を理解することにしました。 ドキュメントの最初のフレーズは、 明確な最適化のために、 group byに使用されるものと同じ最適化をすべて使用できることです。 完全にグループ化するには、2つのアルゴリズムを使用できます。

最初のケースは、グループ化を自動的に定義するインデックスがある場合にのみ適用できます。 2番目のスキームは、他のすべての場合に使用されます。 インデックスのグループ化は順番に実行され、制限することができます。これは、選択性の低いインデックスで結果を表示するために必要なものであるため、非常に便利です。 一時テーブルはこのアプローチでは使用されません(正直なところ、これは完全に真実ではありません。一般に、部分結合の結果と、現在のグループのグループ化の結果として得られる値自体を保存する必要があるためです)。 グループ化の結果はすべて、グループ識別子が主キーである一時テーブルに保存する必要があるため、2番目のスキームの動作は非常に遅く、大量のRAMを消費します。 値が非常に大きい場合、このテーブルはMyISAMに変換され、ディスクにフラッシュされます。 新しく到着したグループはすべて、この大きなテーブルで最初に検索され、必要に応じてその中の値を変更するか、グループが見つからない場合は新しい行を追加します。 最終的なソートにより、このアルゴリズムのパフォーマンスが向上します。 このため、順序付きセットが必要ない場合は、 nullによる順序を追加することをお勧めします 。
このように、最初のアプローチと、 limit構造がdistinctと一緒に使用されるとMySQLがデータの検索を停止するという事実により、グループ化の結果を非常に迅速に取得できます。
不快なことについて
そこで、最初のレコードをすばやく見つけるアルゴリズムを取得しましたが、このアルゴリズムではレコードの総数を計算できません。 回避策として、画面に[ 次へ ]ボタンが表示されるように、もう1つのエントリを返すことができます。
MySQLは、単一のテーブルのクエリで複数のインデックスを使用できません。 これはどのように私たちを脅かしますか? 次のようなクエリを実行してみましょう。
select distinct entt_entt_id
from entity_and_details
where det_low_selective_column = 0 and low_selective_column = 1
order by order_column
limit 0, 3;
信じてください。データを見ると、そこに特別に形成された障害が表示されるので、終了するのを待ちません。 基準det_low_selective_column = 0を満たすセットには、基準low_selective_column = 1を満たすセットとの共通部分がありません。 私たちはこれを知っていますが、残念ながらMySQLはそれについて何も知りません。 したがって、彼はインデックスを選択しますが、これはスキャンに最適であり、選択されたPKと2つのインデックスのフルスキャンを実行します。 主キーのスキャンは、実際にはクラスター構成のためにテーブルの完全なスキャンであるため、これは致命的です。 このようなギャップはすべて、複合インデックスで課税する必要があります。
そして最後に、最も不快な瞬間。 InnoDBはインデックスごとに1つのミューテックスのみを使用します。 したがって、データの書き込みと読み取りを同時に行うクエリを断続的に実行すると、InnoDBエンジンはインデックスをロックし、読み取り操作を一時停止します。書き込み操作によりBツリーが分割され、目的のレコードが別のページに表示される可能性があるためです。 スマートデータベースはツリー全体をブロックするのではなく、分割された部分のみをブロックします。 MySQLでは、このアルゴリズムはまだ実装されていません(このトピックでInnoDBプラグインを見ることができますが、5.5では標準になったようですが、おそらくすべてがそれほど悪くないでしょう)。 この問題を回避するには、データを分離する、つまりパーティションを使用する必要があります。 パーティションテーブルのすべてのインデックスはローカルにパーティション化されています。実際、この点で各パーティションは個別のテーブルですが、パーティション化は別の話なので、この記事では説明しません。
おわりに
厳しい現実が私たちを促す多くの問題の解決策は、一言で説明することはできません。 いくつかのセットでの多基準検索の問題はその1つです。 Sphinxを使用して、このコミュニティが提供する多数のテンプレートをダウンロードできますが、遅かれ早かれ、だれも思い付かない問題に出くわします。 そのため、ドキュメントにアクセスしてデータを調査し、ユーザーにこれを行わないように説得する必要があります。 このレビュー記事が、この厄介な道であなたを待っている落とし穴のいくつかを避けることができることを願っています。
Z.Y. 記事が非常に大きいことが判明したため、group byの多くの最適化を省略しなければなりませんでした。 これらの問題について完全に理解するために、 公式ドキュメントや実用的なヒントでそれらについて読むことができます。
*すべてのコードソースは、 ソースコードハイライターで強調表示されました。