 膨大な数のユーザーがHabréに住んでおり、ユーザーベースの若い、ダイナミック、そして最も重要な急成長中の企業で使用されているテクノロジーとアーキテクチャの説明を読みながら唇をなめていると確信しています。 残念ながら、比較的少数の同胞が世界中のそのような企業で働いており、社内のキッチンでまだ働いている人々は、さまざまな雇用契約の条件または最も興味深い詳細の流出を禁止する平凡なNDAに拘束されています。 それでも、私は個人的に多くの専門家、特に高負荷に興味があり、この情報を直接入手できる場所がわからない専門家を知っています。
膨大な数のユーザーがHabréに住んでおり、ユーザーベースの若い、ダイナミック、そして最も重要な急成長中の企業で使用されているテクノロジーとアーキテクチャの説明を読みながら唇をなめていると確信しています。 残念ながら、比較的少数の同胞が世界中のそのような企業で働いており、社内のキッチンでまだ働いている人々は、さまざまな雇用契約の条件または最も興味深い詳細の流出を禁止する平凡なNDAに拘束されています。 それでも、私は個人的に多くの専門家、特に高負荷に興味があり、この情報を直接入手できる場所がわからない専門家を知っています。
この問題は唯一の方法で解決することができます-開発部門のマネージャーから、または十分に高いポストを占有し、開発に精通している他の人にフロアを提供し、その後、すべての詳細を引き出します。 Twitterエンジニアの1人であるEvan Weaverに、会社が長い間レール上で開発を続けていた理由と、他のテクノロジーの使用に切り替えることを決めた理由とその結果を尋ねたとき、 Information Queueはそれを行いました。
この記事では、移行の本質と、JVMを使用することで得られる利点(主に生産性とスケーラビリティ)を説明するEvanの言葉を完全に参照します。 しかし、後ほど学習するように、この決定は、個々のサービスを分離し、製品の一般的なアーキテクチャをわずかに変更したいという要望によっても決定されました。
そのため、昨年はTwitterがバックエンド(メッセージキュー)のアーキテクチャの変更を発表し、ScalaでTwitterストレージを書き換える意向を発表し、春に検索エンジン全体の書き換えを開始したときに始まります。 これらの変更の一環として、MySQLデータベース(検索の基礎)はLuceneに置き換えられました。 そして最後に、ごく最近、開発チームは検索領域での Ruby on Railsの置き換えを発表しました -その代わりに、彼ら自身がBlenderと呼ぶJavaサーバーでした。 この置換の結果、検索クエリを実行するときの遅延が3倍減少しました。
概要
Twitterの一般的なアーキテクチャを見ると得られる最初の結論の1つは、開発者の決定の多くが完全に実用的であるように見えるということです。 たとえば、製品バックエンドはMySQLと分散Cassandraデータベースの両方を使用します 。 Twitterエンジニア自身の開発について知っている人はほとんどいません。Gizzardは、MySQLデータベースに基づいて分散ストレージを作成するために使用されるフレームワークです。 ウィーバーによると、「比較的柔軟ではないため、主に高度に構造化されたデータ(SLAデータ)に使用されます。」
すべてのリアルタイムデータは、Gizzard / MySQLまたはCassandraから取得されます。 また、このアーキテクチャは、Hadoop分散コンピューティングスタックをオフラインコスト計算に幅広く利用しています;オンラインでは、 Redisキーバリューデータベースと前述のGizzardで構築されたシステムを使用しています。
フロントエンドとバックエンドのレベル間の関係は、Facebook- Thrift ( RPCとして使用されるインターフェース記述言語)と、Twitterおよび新製品サイトのすべての「公式」クライアントで使用されるJSON REST APIの開発を通じて実装されます。
言語
会社で使用されているプログラミング言語の選択にも、同様の実用的なアプローチがあります。 第1レベルの言語:JavaScript、Ruby、Scala、およびJava。 この作業はCでも部分的にサポートされていますが、新しいサービスは書かれていません。 一般に、EvanはRubyの知識と、C / C ++の分野で以前に働いたことのある人によるJavaの使用を備えたScala開発者への移行について話します。
検索エンジンチームに関しては、ここのツールが言語の選択を指示します。 LuceneはJava上に構築されているため、プログラマーは主にこの言語で操作する必要があります。
開発者が自分に最適な作業言語を選択できるようにするために、Twitterはすべてのチームの共通の努力をカプセル化する内部フレームワークの作成に多大な労力とお金を費やしました。 たとえば、 Finagle (Scalaで記述)は、Java、Scala、またはJVMプラットフォーム上のその他の言語で非同期RPCサーバーとクライアントを作成するためのライブラリです。
バックエンド全体が徐々にJVMに向かっている一方で、フロントエンド(クライアント)コードはブラウザーベースのJavaScriptの使用にますます傾いており、Ruby言語のシェアを減らしています。
検索:RubyからJavaへ
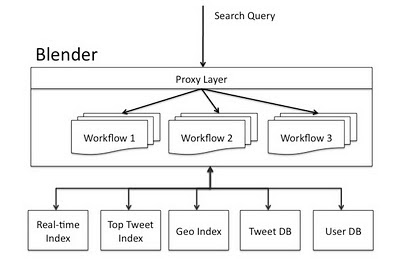
RubyからJavaベースのBlenderフレームワークへの移行は、2つのステップで行われました。 1つ目は、既存のMySQLバックエンドを、Luceneに基づくEarlybirdという名前のリアルタイムの逆インデックスに置き換えることでした。 その試運転により、使用されるメモリの効率が倍増し、さまざまな検索フィルターを追加して製品検索の急増する需要をサポートする柔軟性が得られました。 システムのこの部分の操作のメカニズムのより詳細な説明はTwitterエンジニアによって説明されました 。
フロントエンドのパフォーマンスが低いという問題を解決するために、開発チームはJava Blenderサーバーを構築しました。 Blenderは、既に述べたThriftサービスとHTTP APIで、Javaで記述され、さまざまなサーバープロトコルの開発を可能にするNettyとスケーラブルなクライアント/サーバーライブラリNEW I / O(NIO)で構築されています。 Nettyを使用すると、会社は複数のバックエンドサービス(リアルタイムインデックス、トップツイート、ジオデータなど)から結果を収集できる完全に非同期の集約サービスを作成できます。
これにより、I / Oでの高いキューを回避し、CPUのパフォーマンスを最適化し、現在のリクエストの処理を高速化することができました。 さらに、バックエンドの多くのリクエストを並行して処理できるため、レイテンシが大幅に削減されます。

Twitterの検索エンジンは世界で最も忙しいものの1つであり、1日あたり約10億件のクエリを処理しています。 Blenderへの切り替えの結果は素晴らしく、リクエストの95%が3倍速く処理され始め、遅延が800ミリ秒から250ミリ秒に減少し、製品の両端(フロントエンド-バックエンド)のプロセッサ負荷が半分に減少しました。 同社の現在の能力により、製品は、これらのテクノロジーをアーキテクチャに適用する前の10倍のマシン要求を処理できます。 したがって、同社は、アーキテクチャ全体を生産性の高い状態に維持するために必要なサービスのコストを削減します。
また、パフォーマンスとスケーラビリティはJVMの使用を増やす必要のある重要な問題でしたが、Evanはカプセル化がこの移行の鍵であると言います。 Twitterの現在のアーキテクチャは、一般的に非常によく機能しています。 JVMへの移行は、その開発者の生産性が高く、その結果、製品全体の生産性が高いという事実によって主に決定されました。
MySQLデータベースと組み合わせたRuby on Railsフレームワークの組み合わせは、過去数年にわたり西洋の新興企業に非常に人気がありました。 利点は明らかです。開発者は、提案がユーザーの要求によって決定される実際の市場での作業条件での影響をテストするために、新しくシンプルなアイデアをすばやくテストできます。 ただし、このようなバンドルの欠点は非常に明白です。スケーラビリティとパフォーマンスの問題、および主にRoRに関係するライブラリとツールの未熟さです。
ivaxerへの正確な配合の助けをありがとう
RRW経由のInfoQ