創造の歴史
統計、より正確には、その最初のバージョンは、11月に作成されました(クラウドのローンチが公表されるまで)。 これは非常に素朴なバージョンで、各マシンの統計を正直にカウントし、データベースに書き込みました。これらの統計のいくつかのスクリーンショットは、ブログにも掲載されました。
突然、不幸な事実が明らかになったとき、私たちは顧客にそれを公開する準備がほぼ整いました。文字通り数百台のマシンでは、8コアXeonはすべてを数えるには不十分です。
その理由は、素朴な数学でした。 各仮想マシンの統計のソース:
- プロセッサ
- 記憶
- ディスク操作:2個。 (読み取り/書き込み)
- 読み取り/書き込みデータのボリューム:2個。
- ディスクスペース
- ネットワーク:2個
300台の車で、「単純な」統計をオフにして、それを正しく行う方法を考えなければなりませんでした...
その結果、もう少し-独自のデータベースと統計を収集するためのややこしいアルゴリズムができました。 私たちの推定によると、結果として得られるデザインは、数万台の車に対応できます。 このデータベースのために、Python(システムのほとんどを開発するために使用されている言語)を放棄し、Erlangを使用する必要さえありました。 私自身は彼があまり好きではありませんが、彼がPythonよりもはるかにうまくタスクを解決していることを認めなければなりません(本格的なマルチタスクと毎秒数万のトランザクションは過剰です)。 2番目の重要な機能は、エラー分離、既製のスーパーバイザー、およびITC(スレッド間通信)を備えた「非スレッド」(グリーンレットの類似物、競合マルチタスクを備えたファイバー)の適切なサポートでした。
RRDについて少し
もちろん、「統計」と「グラフ」という言葉で、「ラウンドロビンデータベース」という言葉は、 ドラムに統計データを保存するための最も一般的なシステムの1つである言語で回転しています。 この記事はRRDに関するものではないので、基本的な原則を言います。データは固定サイズのファイルに保存され、新しいデータは古いものを押し出します。 1つのドラムから押し出されたデータは、加算モードで別のドラムに転送されます。 ドラムにはさまざまなディメンションがあります。たとえば、「秒カウントのある時間」、「分カウントのある日」、「時間カウントのある月」、「日カウントのある年」などです。RRDを選択しなかったのはなぜですか? 答えは簡単で悲しいです。RRDは一括挿入をサポートしていません-1回の操作で複数の値を保存することはできません。 これは、数千の個別のトランザクションを実行する必要があることを意味し、各トランザクションはディスクに痛烈な打撃を与えます。
震える
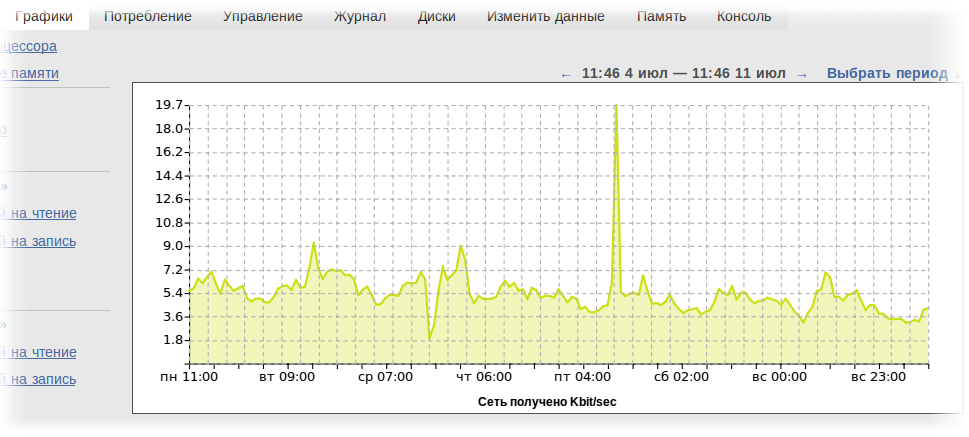
もう1つの問題は、グラフのジッターの問題です。 値を書き留めている間は少なくとも少し長持ちする価値があります-チャートにわずかな失敗が現れているので-次の反復でわずかなスプラッシュがあります。 断続的な負荷ではほとんど感知できないため、このジッターは、メモリ消費量とディスクサイズのグラフではかなりばかげて見えました。問題解決
私たちのソリューションは、統計情報を収集し、コンベヤーに沿って移動する「バケット」に記録する特別な方法です。 バケットは、レコードが存在するかどうかに関係なく移動します。 記録が発生すると、その内容は記録の瞬間に比例して2つのバケットに分割されます。 1:01と1:02のバケットがあり、記録が1:01.33に発生した場合、値の3分の2が最初のバケットに、3分の1が2番目に書き込まれます。コンベアは異なる速度で移動し(読み取り、解像度が異なります)、一定の長さを持ちます-実際には、特定の解像度の統計が利用可能な間隔です。 単一の値を書き込むと、すべてのパイプラインに(低速と高速の両方で)すぐに分散され、さらに、一度にさまざまな回路のさまざまなパイプラインの値を記録できます。
私はすでにこのソリューションの速度について書きましたが、速度に加えて、このアプローチは別の問題を解決しました-ジッタがありません(実際、バケットへの書き込みと整数への丸め誤差の決定の不正確さのために存在しますが、0.1最大0.5%。これは、グラフの通常のサイズの線の太さよりも小さく、単純な「rrdのような」データベースでは1〜5%です。
残念ながら、このアルゴリズムには小さな欠陥があります-最初と最後のポイントが正しく表示されていません-「バケット」はまだ満杯ではないため、組立ラインの最初と最後でグラフが明らかに低下しています。 また、これがスケジュールの「開始」にとって特に重要でない場合は、最後の分の誤った表示が問題になります。 残念ながら、これは残りの問題をうまく解決するための価格です。
保管
現在の(一時的な)実際のバックエンドは、必要なデータ型と速度のサポートのおかげで、Redisです。 ただし、この速度はまだ十分ではないため、クラウドの開発に合わせて、ニーズに完全に完全に合わせた独自のストレージに置き換えます。 現在、パイプラインで1つのティックを処理するには複数のトランザクションが必要であり、これは好ましくありません。ディスプレイ
私たちの伝統に従い、HTML / JSを使用してすべてを実行しようとしました-グラフィックは、サーバー側からPNGに予備レンダリングすることなく、SVGでJSによって直接描画されます。 このために、gRaphaëlライブラリー( http://g.raphaeljs.com/ )を使用します 。既知の問題
頻繁にドライブを接続したり取り外したりするお客様は、ドライブを再接続するたびに、I / O操作に関するすべての統計が失われることがあります。 実際、失われることはなく、仮想マシンとディスクの間の接続のみが毎回新しくなります。したがって、データベース内の新しいパイプラインです。
統計は少し漏れやすいことがあります-クライアントマシンやアカウンティングデータとは異なり、統計を特に優先度の高いサービスとは見なしません(そのためのクラスターもありません)。ラクナエ。 申し訳ありませんが、現状のままです。
同じ理由で、先月の統計にいくつかの理解不足があるかもしれません-私たちはいくつかのポイントを「生きている」デバッグしました。
特定の解像度(たとえば、時間カウント)で統計情報をめくると、すぐに終わりに出くわします。 RRDと同様に、高解像度チャートのデータをしばらく保存するだけです。その場合、データはより粗い形式でのみ使用できます(たとえば、日ごとの時間カウントではなく)。
外観、私たちはまだ、 ここのコメントに基づきます。
消費量表示
また、別の投稿に値するものではない、もう1つの小さな変更:固定サンプル(今日/昨日/週/月/常時)だけでなく、毎日の消費量を確認できるようになりました。 これは明らかに私たちがやりたいことではありませんが、カレンダーを台無しにするのは簡単でした。 このタブはまだスタブ状態です。つまり、大幅に変更します。