最初の部分: http : //habrahabr.ru/blogs/sql/119317/
リレーショナル、階層、ネットワーク、Key-Valueなど。DBMSはデータモデルのみを定義します。情報モデルは自由に選択できます(データモデルと混同しないでください)。 いずれにせよ、情報モデル要素のデータモデルへの分解とマッピングが必要になります。
たとえば、古典的なIDEF1X情報モデルは、エンティティ、属性、1対1の関係、1 対多の関係、多対多の関係、分類(1対1の関係)の要素で構成されます。 また、RDBMSリレーショナルデータモデルには、テーブル、フィールド、1対多の関係のみがあります。 エンティティは1つ以上のテーブルにマッピングされ、すべてのタイプの関係は1対多(RDBMSの大部分には他のタイプは存在しません)として表され、記事の前半で説明した方法で分類が導入されます 。
抽象化のレベルを上げるのを妨げるものは何ですか? まず第一に、開発者はアプリケーションの情報モデルの一部を作成することを余儀なくされているという事実。 つまり、モデルのこの部分を修正すると、サブジェクト領域をカスタマイズする柔軟性が失われます。 リレーショナルストレージやその他のストレージと並行して使用される動的に解釈されるメタモデルを導入することで、この問題の解決策を見つけました。 メタモデルは、サブジェクト領域の記述の不確実性を軽減し、アプリケーションから「アタッチメントポイント」を削除して、タスクの詳細に対する固執を取り除くことができます。
アプリケーションアプリケーションの開発に必要な情報モデリングコンポーネントのほとんどを組み立てようとしました。 最初のパートの最後に図がありました:
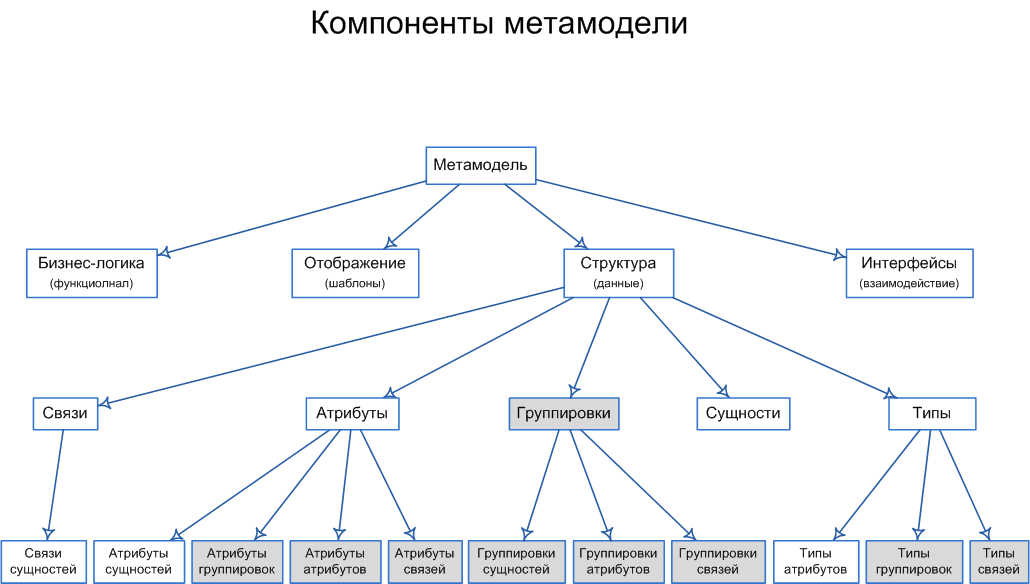
ここで、より詳細に説明します。 図の一番下の行では、リレーショナルデータのコンポーネントは白でマークされ、RDBMSに配置するために分解またはメタ記述が必要なコンポーネントはグレーでマークされています。 それらをより詳細に検討しましょう。
エンティティのグループ化
多くの場合、最初に不足しているのは、サブジェクトエリアのエンティティをグループに結合する機能です。
適用 :エンティティは本質的に同質ではない場合があり、1つのサブジェクトエリアの異なるレベルの抽象化または1つのデータベースが提供する異なるサブジェクトエリアに関連している場合、またはサブジェクトエリア内の複数のクラスター/ゾーンを区別したい場合があります。
ソリューションオプション:テーブル名にプレフィックスを使用し、データベース構造をさまざまな色で着色しますが、ほとんどの場合、データベースを操作するソフトウェアはグループを直接「認識」し、グループはコードに「配線」され、コードなしのモデルは不完全です。
属性グループ
自然に、機能的、意味的に、またはエンティティモデリングのさまざまな側面に関連するセマンティックブロック内のエンティティの属性のグループ化のようです。
アプリケーション :たとえば、住所に関連するフィールド(国、都市、通り、家、郵便番号など)をグループ化するか、2つのフィールドで1つの属性を説明すると便利です(緯度と経度が「座標」属性を表す)。
考えられる解決策:フィールド名にプレフィックスを導入し、フィールドを順番にリストしますが、基本的に、情報モデルのこの側面はユーザーインターフェイスに「縫い付け」られ、 モデルはインターフェイスなしでは完全ではないことがわかります 。
グループのリンク
テーブル間のリレーションは常に名前が付けられているわけではないため、名前によるリレーションのグループ化はほとんどありませんが、非常に必要なタスクがあります。
アプリケーション :例#1-多対多の人々がクロスタブを介して再リンクし、関係の一部を「関連」、一部を「友好的」または「労働者」として強調表示する必要があります。 多対多のクロステーブルがいくつかある場合のグループ化の別の一般的なケース(例#2)があり、車両の所有者、財産所有者、ペット所有者をいくつかのグループにグループ化する必要があります:元の所有者、現在の所有者、所有権を争う人。
ソリューションオプション:ケース#1の場合-クロスタブにフラグを入力するか、リンクグループのディレクトリを追加します。 ケース#2の場合、異なるテーブルに同じフラグとディレクトリを入力することは確かに可能ですが、1つのリクエストですべての「現在の所有者」を選択したいと思います。 これを行うには、 最初のパートで説明したように、抽象的な「畳み込み」を使用できます。
属性とグループタイプ
上記の各グループは独自の属性とタイプを持つことができ、これは非常に自然なことです。 また、さまざまなグループに対して、多くの例と実装方法があります。
リンク属性
エンティティ間の接続は同種ではなく、確かにバイナリではありません。 関係の確立日、接続の強さ、情報の信頼係数、情報のソースまたはユーザー(接続の所有者)およびその他の属性を関係に付加する必要がある場合があります。
アプリケーション :たとえば、スペシャリストとポジションの間の関係には、ポジションへの入社日と任命された給与が含まれる場合があります。
ソリューションのバリエーション:関係の属性を記述するために、通常はエンティティ自体またはリンクテーブルのフィールドを記述するテーブルフィールドを使用します。 つまり、アプリケーションは、フィールドの名前によって既に「認識」および「識別」されます。ここで、エンティティの属性、および通信の属性です。
属性属性
このようなトートロジーですが、考えてみればナンセンスではありませんが、多くのサブジェクト領域では、エンティティの属性が独自の属性を多数持つことができます。
アプリケーション :たとえば、センサーの測定値は、エラー評価、変更単位、測定にかかる時間、変更を行った人またはシステムにデータを入力した人へのリンクによって補完できます。
ソリューションのバリエーション:通常、1つのテーブルに2つ、3つ、またはそれ以上のフィールドを作成します。ユーザーインターフェイスまたはアプリケーションのレベルでは、1つのフィールドが別のフィールドの属性であることは既に暗示されています。
関係の種類
私の意見では、最も重要な情報モデルの要素は、エンティティ間の関係のタイプです。 ほとんどの場合、アプリケーションとユーザーインターフェイスに「接続」されるのはこの特性であり、場合によっては明示的にどこにも定義されておらず、ユーザーが注意を払って直接処理します。
アプリケーション :いくつかのタイプを選択します(完全なリストからはほど遠い):1対1、多対多、ディレクトリへのリンク、リンクタイプ「マスター/ディテール」、リンクタイプ「コンテナー」など。
ソリューションオプション:ディレクトリとの通信は、コンボボックスまたは自動増分入力フィールドの形式でユーザーインターフェイスに実装できます。 Master-Detailは、ポップアップ、複数のグリッド、ツリーのようなグリッド、またはコンボボックスとグリッドなど、さまざまな方法で実装できます。 たとえば、どの「マスター/ディテール」に応じて、日付、購入した商品、または弱い接続でグループ化されたログを表示できます。たとえば、ホテルの部屋での人々の決済に関するデータです。 「ホテル」と「部屋」の接続を「部屋」と「ゲスト」の接続と比較すると、部屋はホテルの不可欠な部分ですが、ゲストとの接続は「ソフト」であることに注意してください。マスターディテール。」 一般に、データベース構造とアプリケーション画面の例を使用して、関係の分類に関する別の記事を書くことができます。
したがって、アプリケーション、インターフェイス、テンプレートに配置される情報モデルの要素は多数あり、本質的にモデルの一部です。 ここで、純粋にソフトウェアおよびシステムソリューションからそれらを分離するには、メタモデルレイヤーも必要です。 この場合、DBMSは、データとメタモデルの両方の2つの抽象化レベルの物理リポジトリとして使用されます。 アプリケーション実行中のメタモデルの動的な解釈により、複数の抽象化レベルを単一の全体にリンクできます。
第三部では、応用問題におけるメタモデルの適用例を検討する予定です。
ご清聴ありがとうございました。