 距離マップは、特定のポイントから特定のサーフェスまでの距離をすばやく取得できるオブジェクトです。 通常、固定ピッチのノードの距離値のマトリックス。 多くの場合、ゲームでプレーヤーまたはオブジェクトへの「取得」を決定するため、およびオブジェクトを結合する最適化タスクのために使用されます。オブジェクトを互いにできるだけ近くに配置します。 最初のケースでは、距離マップの品質(つまり、ノード内の値の精度)は大きな役割を果たしません。 第二に、人生はそれに依存する可能性があります(脳神経外科に関連する多くのアプリケーションで)。 この記事では、妥当な時間で距離マップを正確に計算する方法を説明します。
距離マップは、特定のポイントから特定のサーフェスまでの距離をすばやく取得できるオブジェクトです。 通常、固定ピッチのノードの距離値のマトリックス。 多くの場合、ゲームでプレーヤーまたはオブジェクトへの「取得」を決定するため、およびオブジェクトを結合する最適化タスクのために使用されます。オブジェクトを互いにできるだけ近くに配置します。 最初のケースでは、距離マップの品質(つまり、ノード内の値の精度)は大きな役割を果たしません。 第二に、人生はそれに依存する可能性があります(脳神経外科に関連する多くのアプリケーションで)。 この記事では、妥当な時間で距離マップを正確に計算する方法を説明します。
主なオブジェクト
ボクセルのセットによって定義された表面Sがあるとします。 ボクセル座標は、通常のグリッドでカウントされます(つまり、X、Y、Zに沿ったステップは同じです)。
サーフェスを含む立方体にあるすべてのボクセルの距離マップM [X、Y、Z]を計算する必要があります。 M [x、y、z] = d((x、y、z)、S)= min(d((x、y、z)、(S n x、S n y、S n z))= sqrt (min((xS n x) 2 +(yS n y) 2 +(zS n z) 2 ))最後の等式は通常のグリッドにのみ当てはまり、残りは明白です。
データはどこから来たのですか
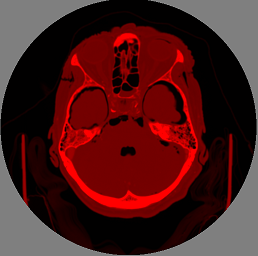
このタスクでは、データはMRIデバイスから取得されます。 私たちは3D画像で作業しているので、3D画像全体がZの異なるスライスのフラットな画像のセットであることを思い出させてください。これは確かにここでは想像できません。 それらはXおよびY解像度よりわずかに小さく、一般的なトモグラフィーのサイズは約625x625x592ボクセルです。

かなり難しい変換の結果、頭の表面の境界が目立ちます。 これらの変換の本質は、「ノイズ」を除去するさまざまなフィルターと、勾配によって境界自体を決定する機能にあります。 ここには新しいものは何もありません。そのようなことは、特に 「画像処理」の主題で説明されました。 境界線自体は、距離を計算してマップを作成するターゲットセットです。
直接検索
最初に、「定義による」値-境界点までの最小距離で距離マップを埋めない理由を推定しましょう。 合計マップポイント:X * Y * Z、最大次数のサーフェスポイント(X、Y、Z) 2 。 ソースデータのサイズを思い出して、592 * 625 4の算術演算のオーダーを取得します。 計算機は、それが90兆を超えることを教えてくれます。 控えめに言っても、少し多すぎるので、今は直接検索を延期します。
動的プログラミング
データが3次元配列で表されるという事実の使用を頼みます。 どういうわけか、各ポイントでその近傍を使用して値を計算できます。もちろん、これを行うのは私たちが初めてではありません。 サイズが592 * 625 * 625 * sizeof(float)の構造(約1ギガバイト)を維持することは、ややリソースを消費するという事実に反発します。 さて、トモグラフィーを2倍の解像度(さらに8倍)で撮影できることを忘れてください-640Kバイトが長い間欠落していました。
迷路をバイパスするアルゴリズムと同様に、最も簡単な塗りつぶし方法(都市ブロック)は数秒で完了しますが、3次元グリッドの最大誤差は、計算された最大距離50ステップに対して42グリッドステップになります。 それはどれほど悪いですか? 完全な失敗。
クラスの唯一のアルゴリズム( 中心点 )は、ほぼ満足のいく精度(0.7グリッドステップ以下の誤差)を提供しますが、数分で機能します。
チェスボードの距離を実装することで妥協点を見つけようとしました(説明は中心点と同じ記事にあります)が、最終的な精度は調整できず、その動作時間は数十秒でした。
 写真はフルサイズへのリンクですが、プレビューでも表面ポイントから十分に離れた「奇妙な」動作を示します。特に内部オブジェクトもカウントする必要がある場合はそうです。 左側にはチェス盤があり、右側には直接列挙によって得られたものがあります。 繰り返しになりますが、写真だけを見る人にとっては3D画像について話しているので、内部の奇妙な「穴」は理解できます-それらは次または前のZスライドの表面に近接していることが原因です。
写真はフルサイズへのリンクですが、プレビューでも表面ポイントから十分に離れた「奇妙な」動作を示します。特に内部オブジェクトもカウントする必要がある場合はそうです。 左側にはチェス盤があり、右側には直接列挙によって得られたものがあります。 繰り返しになりますが、写真だけを見る人にとっては3D画像について話しているので、内部の奇妙な「穴」は理解できます-それらは次または前のZスライドの表面に近接していることが原因です。
再び直接検索
はい、写真のCUDAという言葉はほのめかしています。 たぶん90兆ドル-それほど多くない、あるいはこの数は精度を損なうことなく何らかの形で減らすことができます。 いずれにせよ、ミドルエンドビデオカードは、同じクラスのプロセッサよりも80〜120倍高速なプリミティブコンピューティング操作を処理します。 やってみましょう。
はい、直接列挙には大きな利点があります-距離マップ全体をメモリに保持する必要がないため、結果として-線形スケーラビリティ。
バスト削減
論文:各ポイントが境界線の各ポイントまでの距離をチェックすることは意味がありません。 実際、距離マップは、境界に近接した場合にのみ良好な精度を確保する必要があり、遠い点は完全に省略でき、中間点はおおよその距離でマークする必要があります。
正確性の基準は、境界付近の絶対精度(最大10(GUARANTEED_DIST)グリッドステップの距離)、36(TARGET_MAX_DIST)ステップの距離での良好な精度、および視覚的妥当性(アーチファクトなし-外科医を混乱させる理由)です。 10と36の数字は、タスクから直接取得されます(通常、これらの値はミリメートルとミリメートルグリッドで表されます)。
キュービックインデックス
各ポイントについて、その値をどれだけ正確に計算する必要があるかを判断したいと思います。 明らかに、そのような構造のサイズは元の画像のサイズと一致しますが、これは非常に多く、長い間考慮されます。
ポイントを「キューブ」にマージします。 キューブサイズを32(CUBE_SIZE)とすると、インデックスのサイズは20 x 20 x 19になります。
その中にある「最良の」ポイントのタイプに従ってキューブをマークします。 少なくとも1つのポイントで正確な計算が必要な場合、キューブ全体を確実に考慮します。 最悪の場合、私たちはまったく考えません。
キューブにすばやくラベルを付ける方法は? 境界点から始めましょう:それぞれに27方向すべてのオフセットGUARANTEED_DIST((-1,0,1)x(-1,0,1)x(-1,0,1))を追加し、対応するキューブのインデックスを取得します。 32(CUBE_SIZE)で除算し、「正確」としてマークします。結局、正確な計算が必要なポイントが少なくとも1つ含まれています。 目的:これで十分な理由を説明し、正確な計算のためのポイントを含むすべてのキューブに正しくマークを付けます。
念のため、これを実行する非常に簡単なコードは次のとおりです。
for (size_t t = 0; t < borderLength; t++)
{
for ( int dz = -1; dz <= 1; dz++)
for ( int dy = -1; dy <= 1; dy++)
for ( int dx = -1; dx <= 1; dx++)
{
float x = border[t].X + ( float )dx * GUARANTEED_DIST;
float y = border[t].Y + ( float )dy * GUARANTEED_DIST;
float z = border[t].Z + ( float )dz * GUARANTEED_DIST;
if (x >= 0 && y >= 0 && z >= 0)
{
size_t px = round(x / CUBE_SIZE);
size_t py = round(y / CUBE_SIZE);
size_t pz = round(z / CUBE_SIZE);
size_t idx = px + dim_X * (py + skip_Y * pz);
if (idx < dim_X * dim_Y * dim_Z)
{
markedIdx[idx] = true ;
}
}
}
}
実際のデータに基づいて、このアイデアにより、「合計」の検索順序を4〜5倍減らすことができました。 すべて同じですが、多くのことが判明しましたが、キューブを使用したアイデアは依然として有用です。
立方体の容器
実際、境界のすべてのポイントまでの距離を計算することは意味がなく、最も近いポイントについてのみ計算するだけで十分です。 そして今、私たちはそのような構造を整理する方法を知っています。
境界線Sのすべてのボクセルをキューブに分散します(これ以降、インデックスキューブについては忘れます。それらを構築し、それらの使用方法を理解し、現在はもう使用していません)。 各キューブに、到達可能な境界ポイントを配置します(TARGET_MAX_DIST以下の距離にあります)。 これを行うには、立方体の中心を計算し、距離sqrt(3)/ 2 * CUBE_SIZE(これは立方体の対角線)+ TARGET_MAX_DISTを脇に置きます。 ポイントがキューブの上部または側面の任意のポイントから到達可能な場合、その内部から到達可能です。
コードを与えることは意味をなさないと思います。前のものと非常に似ています。 アイデアの正確さも明らかですが、重要なポイントが1つ残っています。実際、境界のポイントを「乗算」します。その数は、妥当なTARGET_MAX_DIST(キューブのサイズ未満)で最大27倍、さらにはさらに倍増します。
最適化:
- 最初の(強制)-キューブのサイズは、「乗算された」ポイントの総数がそれらのメモリの最大量を超えないように選択されます(512メガバイトかかりました)。 キューブサイズをすばやく選択できます(少しの計算)。
- 2番目の(合理的な)方法は、各キューブのポイントの初期配置と最終配置にインデックスを使用することです。これらのインデックスは交差できます。また、適切な計算により、メモリサイズをさらに2倍節約できます。
私は両方のポイントに対して正確なアルゴリズムを意識的に与えることはしません(それらをより良く実装して競合他社になったらどうしますか?;))、アイデアよりも言葉があります。
一般に、キューブは検索順序をX / CUBE_SIZE * Y / CUBE_SIZE * Z / CUBE_SIZE倍減らしますが、キューブのサイズを小さくするとかなり多くのメモリが必要になり、画像のしきい値は約24〜32になることに注意してください。
したがって、タスクは約1,000〜2,000億の材料操作に削減されました。 理論的には、これはグラフィックカードで数十秒で計算可能です。
CUDAカーネル
とてもシンプルで美しいことが判明したので、私はそれを表示するのが面倒ではありません:
__global__ void minimumDistanceCUDA( /*out*/ float *result,
/*in*/ float *work_points,
/*in*/ int *work_indexes,
/*in*/ float *new_border)
{
__shared__ float sMins[MAX_THREADS]; // max threads count
for ( int i = blockIdx.x; i < BLOCK_SIZE_DIST; i += gridDim.x)
{
sMins[threadIdx.x] = TARGET_MAX_DIST*TARGET_MAX_DIST;
int startIdx = work_indexes[2*i];
int endIdx = work_indexes[2*i+1];
float x = work_points[3*i];
float y = work_points[3*i+1];
float z = work_points[3*i+2];
// main computational entry
for ( int j = startIdx + threadIdx.x; j < endIdx; j += blockDim.x)
{
float dist = (x - new_border[3*j] )*(x - new_border[3*j] )
+ (y - new_border[3*j+1])*(y - new_border[3*j+1])
+ (z - new_border[3*j+2])*(z - new_border[3*j+2]);
if (dist < sMins[threadIdx.x])
sMins[threadIdx.x] = dist;
}
__syncthreads();
if (threadIdx.x == 0)
{
float min = sMins[0];
for ( int j = 1; j < blockDim.x; j++)
{
if (sMins[j] < min)
min = sMins[j];
}
result[i] = sqrt(min);
}
__syncthreads();
}
}
列挙の距離マップポイントの座標ブロック(work_points)、境界点の列挙の対応する開始インデックスと終了インデックス(work_indexes)、およびキューブを使用したアルゴリズムによって最適化された境界(new_border)を読み込みます。 単一の材料精度で結果を取得します。
実際、カーネルコード自体は、CUDAの複雑さがなくても理解するのに非常に便利です。 その主な機能は、ビデオカードで実行中のスレッドのセットから現在のスレッドのインデックスを示すgridDim.xおよびthreadIdx.x変数を使用することです。誰もが同じことをしますが、異なるポイントを使用して、結果が同期され、正確に記録されます。
CPU上でwork_pointsの計算を正しく整理するためだけに残っています(しかし、それはとても簡単です!)そして、計算機を起動します:
#define GRID 512 // calculation grid size
#define THREADS 96 // <= MAX_THREADS, optimal for this task
minimumDistanceCUDA<<<GRID, THREADS>>>(dist_result_cuda, work_points_cuda, work_indexes_cuda, new_border_cuda);
Core Duo E8400およびGTX460グラフィックスカードでは、平均的な断層撮影が1分以内に処理され 、メモリ消費は512MBに制限されます。 プロセッサ時間の配分は、CPUおよびファイル操作で約20%、ビデオカードの最低値の計算で残りの80%です。
そして、ここに遠点の「粗面化」で数えた写真があります:

どういうわけか、何かが役に立つといいのですが。 大きなリクエストです。写真をコピーせず、許可なく再公開しないでください(メソッドの作成者ですが、「メソッド」と呼ぶことは困難です)。
良い一日を!