なんで? この多様性をすべて理解する方法は?
SIMD、SMP、GPGPU、その他の恐ろしい言葉の意味はどんどん増えていますか?
既存の生産性技術の適用性の限界は何ですか?
はじめに
なぜそのような困難があるのですか?
コンピュータの処理能力は急速に成長しており、常に、既存の速度ですべてが十分であると思われます。
しかし、いいえ-生産性の向上により、以前はアプローチできなかった問題を解決できます。 家庭レベルでも、ホームビデオのエンコードなど、長時間コンピューターをロードするタスクがあります。 産業や科学には、さらに多くのそのようなタスクがあります。巨大なデータベース、分子動力学計算、複雑なメカニズムのモデリング-車、ジェットエンジンなど、すべての計算にはますます強力な力が必要です。
過去数年間、主な生産性の向上は、マイクロプロセッサー要素のサイズを縮小することにより、非常に簡単に提供されました。 同時に、消費電力が低下し、動作周波数が増加し、コンピューターはますます高速になり、一般的にはアーキテクチャが維持されました。 超小型回路の製造プロセス技術は変化しており、メガヘルツはギガヘルツに成長し、メガが百万であれば、ギガはすでに1秒あたり10億回の操作であるため、生産性が向上します。
しかし、ご存知のように、楽園は永遠ではないか、誰にとってもそうではありません。コンピューターの世界で終わったのはそれほど昔ではありません。 周波数をこれ以上上げることはできないことが判明しました。漏れ電流が増大し、プロセッサが過熱しており、これをバイパスすることはできません。 もちろん、冷却システムを開発したり、ラジエーターを使用したり、液体窒素で完全に冷却したりできますが、これはすべてのユーザーがアクセスできるわけではなく、スーパーコンピューターやテクノマニアだけが利用できます。 また、冷却を行った場合、成長の可能性は小さく、約2倍になりました。これは、幾何学的進行に慣れているユーザーには受け入れられませんでした。
トランジスタの数と関連するコンピューターのパフォーマンスが1.5年から2年ごとに2倍になったムーアの法則は適用されなくなるようです。
考えて実験する時間です。計算の速度を上げるために考えられるすべての方法を思い出してください。
性能式
最も一般的な性能式を取ります。

生産性は、1秒あたりに実行される命令の数で測定できることがわかります。
プロセスをより詳細に説明し、クロック周波数を紹介します。

受け取った作業の最初の部分は1クロックサイクル(IPC、1命令あたりの命令)で実行される命令の数、2番目は単位時間あたりのプロセッサクロックの数、クロック速度です。
したがって、パフォーマンスを向上させるには、クロック周波数を上げるか、サイクルごとに実行する命令の数を増やす必要があります。
なぜなら 頻度の増加が停止した場合、実行可能な命令の数を「一度に」増やす必要があります。
並列処理を有効にする
サイクルごとに実行される命令の数を増やす方法は?
明らかに、一度に複数の命令を並行して実行します。 しかし、それを行う方法は?
それはすべて、実行しているプログラムに依存します。
プログラマーがプログラムをシングルスレッドとして記述し、すべての命令が順番に実行される場合、プロセッサー(またはコンパイラー)は「人のために考え」、同時に実行できるプログラムの並列部分を検索する必要があります。
命令レベルの並行性
簡単なプログラムを見てみましょう:
a = 1
b = 2
c = a + b
最初の2つの命令は並行して実行でき、3番目の命令のみがそれらに依存します。 そのため、プログラム全体は3つのステップではなく2つのステップで完了することができます。
独立した競合する命令を独立して決定し、それらを並列に実行できるプロセッサをスーパースカラーと呼びます。
最新のx86-スーパースカラープロセッサを含む多くの最新のプロセッサがありますが、別の方法があります。プロセッサを単純化し、コンパイラに並列処理を割り当てることです。 同時に、プロセッサは、プログラムコンパイラが準備した「バッチ」でコマンドを実行します。このような「バンドル」は、互いに独立しており、並行して実行できる命令のセットです。 このアーキテクチャはVLIW(非常に長い命令語-「非常に長いマシン命令」)と呼ばれ、そのさらなる開発はEPIC(明示的な並列命令コンピューティング)-コマンドの明示的な並列性を備えたマイクロプロセッサアーキテクチャ)
このアーキテクチャを持つ最も有名なプロセッサは、Intel Itaniumです。
サイクルごとに実行される命令の数を増やすための3番目のオプションがあります。これはハイパースレッディングテクノロジです。この技術では、スーパースカラープロセッサは1つのスレッドの命令を並列化しませんが、複数の(最新のプロセッサでは2つの)並列スレッドのコマンドを並列化します。
つまり 物理的には、プロセッサコアは1つですが、1つのタスクプロセッサ電源を実行するときにアイドル状態を使用して、別のタスクを実行できます。 オペレーティングシステムは、ハイパースレッディングテクノロジを備えた1つのプロセッサ(または1つのプロセッサコア)を2つの独立したプロセッサと見なします。 しかし、実際には、もちろん、ハイパースレッディングは実際の2つの独立したプロセッサよりも動作が悪くなります。 そのタスクは、それらの間で計算能力を競います。
命令レベルの同時実行技術は、90年代と2000年代前半に積極的に開発されましたが、現在ではその可能性はほとんど枯渇しています。 コマンドの再配置、レジスタの名前変更、その他の最適化の使用、シリアルコードからの並列実行セクションの選択は可能ですが、依存関係と分岐ではコードを自動的に並列化できません。 命令レベルでの並行性は、人間の介入を必要としないため良好ですが、これも悪いことです。人がマイクロプロセッサーより賢い限り、真の並列コードを書かなければなりません。
データレベルの同時実行性
ベクトルプロセッサ
既にスカラー性について説明しましたが、スカラーに加えてベクトルがあり、スーパースカラープロセッサに加えてベクトルがあります。
ベクトルプロセッサは、データ配列全体、ベクトルに対して何らかの操作を実行します。 「純粋な」形で、ベクトルプロセッサは80年代に科学計算用のスーパーコンピューターで使用されました。
フリンの分類によると 、ベクトルプロセッサはSIMDに属します(単一命令、複数データ-単一命令ストリーム、複数データストリーム) 。
現在、x86プロセッサは多くのベクトル拡張を実装しています-これらはMMX、3DNow!、SSE、SSE2などです。
たとえば、SSEを使用して1つのコマンドで4組の数値を乗算するように見えるものは次のとおりです。
float a[4] = { 300.0, 4.0, 4.0, 12.0 };
float b[4] = { 1.5, 2.5, 3.5, 4.5 };
__asm {
movups xmm0, a ; // 4 a xmm0
movups xmm1, b ; // 4 b xmm1
mulps xmm1, xmm0 ; // : xmm1=xmm1*xmm0
movups a, xmm1 ; // xmm1 a
};
したがって、4つの連続したスカラー乗算の代わりに、たった1つのことを行いました。ベクトルです。
ベクトルプロセッサは、大量のデータの計算を大幅に高速化できますが、その範囲は限られており、固定アレイでの一般的な操作はどこにも適用できません。
ただし、ベクトル化を計算するための競争は決して終わりではありません。そのため、最新のIntelプロセッサでは、新しいベクトル拡張AVX(Advanced Vector Extension)
しかし、彼らは今、もっと面白そうです
GPU
最新のビデオカードのプロセッサの理論的な処理能力は、従来のプロセッサよりもはるかに速く成長しています(NVIDIAの有名な図を参照)

少し前まで、この機能はCUDA / OpenCLを使用したユニバーサル高性能コンピューティングに適合していました。
グラフィックプロセッサのアーキテクチャ(GPGPU、GPUでの汎用計算-ビデオカードによる汎用計算)は、すでに考慮されているSIMDに近いものです。
SIMT-(単一命令、複数スレッド、1命令-複数スレッド)と呼ばれます。 SIMDの場合と同様に、操作はデータ配列を使用して実行されますが、処理されるデータのセルごとに、コマンドの個別のスレッドが機能するはるかに自由度があります。
結果として
1)並行して、数百のデータセルに対して数百の操作を実行できます。
2)コマンドの任意のシーケンスが各スレッドで実行され、異なるセルを参照できます。
3)分岐が可能です。 ただし、この場合、操作のシーケンスが同じスレッドのみを並列に実行できます。
GPGPUは、いくつかのタスクで印象的な結果を達成します。 しかし、この技術が普遍的な命の恩人になることを許可しない根本的な制限があります、すなわち
1)GPUで加速できるのは、データに応じた並列コードのみです。
2)GPUは独自のメモリを使用します。 GPUメモリとコンピューターメモリの間でデータを転送するのは非常に高価です。
3)多数のブランチを持つアルゴリズムはGPUで非効率的に動作します
マルチアーキテクチャ
そのため、コマンドとデータの両方で独立して並列する完全な並列アーキテクチャになりました。
Flynnの分類では、これはMIMD(複数命令ストリーム、複数データストリーム-複数コマンドストリーム、複数データストリーム)です。
このようなシステムの能力を最大限に活用するには、マルチスレッドプログラムが必要であり、その実行を複数のマイクロプロセッサで「分散」することができ、それにより頻度を増やすことなく生産性の向上を実現できます。 さまざまなマルチスレッドテクノロジーがスーパーコンピューターで長い間使用されてきましたが、現在ではそれらは一般ユーザーに「天から下がって」おり、マルチコアプロセッサが例外よりも一般的です。 しかし、マルチコアは万能薬とはほど遠いものです。
厳しい法律ですが、それは法律です
並列処理は、クロック速度の制限を回避する良い方法ですが、独自の制限があります。
まず、これはアムダールの法則であり、
さまざまな計算機で命令を並列化することによりプログラムの実行を加速することは、その逐次命令を実行するのに必要な時間によって制限されます。
コードアクセラレーションは、プロセッサの数と式に従ってコードの並列性に依存します

実際、並列実行を使用すると、並列コードのみの実行時間を短縮できます。
どのプログラムでも、並列コードに加えて、連続したセクションがあり、プロセッサの数を増やしてセクションを高速化することはできず、1つのプロセッサのみがそれらに取り組んでいます。
たとえば、シーケンシャルコードの実行にプログラム全体の実行時間の25%しかかかっていない場合、このプログラムを4回以上加速すると失敗します。
並列コンピューティングプロセッサの数に対するプログラムの加速の依存関係のグラフを作成しましょう。 順次コードの1/4と並列の3/4を式に代入すると、次のようになります。
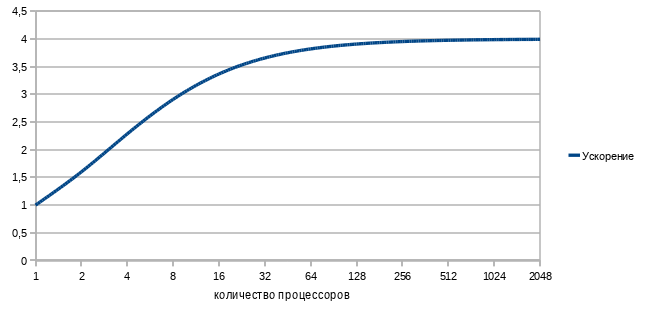
悲しいです そのように。
数千のプロセッサとテラバイトのメモリを備えた世界最速のスーパーコンピューターで、一見優れた(75%!)並列タスクで、通常のデスクトップクワッドの2倍未満の速度です。
そして、この理想的な場合よりもさらに悪いです。 現実の世界では、並列処理のコストがゼロに等しくなることはありません。したがって、プロセッサを追加すると、ある時点からパフォーマンスが低下し始めます。
しかし、現代の非常にマルチコアなスーパーコンピューターのパワーはどのように使用されていますか?
多くのアルゴリズムでは、パラレルコードの実行時間は処理されるデータの量に大きく依存しますが、シリアルコードの実行時間はそうではありません。 処理する必要があるデータが多いほど、並列処理からのゲインが大きくなります。 したがって、大量のデータをスーパーコンピューターに「駆り立てる」ことで、十分な加速が得られます。
たとえば、スーパーコンピューターで3 * 3の行列を乗算すると、通常のシングルプロセッサバージョンとの違いに気付くことはほとんどありませんが、サイズが1000 * 1000の行列を乗算することは、マルチコアマシンではすでに完全に正当化されます。
そのような簡単な例があります:1か月の9人の女性は1人の子供を出産できません。 ここでは並行性は機能しません。 しかし、9か月で同じ81人の女性が出産することができます(最高の効率を実現します!)81人の子供に、つまり、並列性の向上から最大の理論的生産性を得ることができます。 。
大きなコンピューターには大きなタスクがあります!
マルチプロセッサ
マルチプロセッサは、複数のプロセッサとすべてのプロセッサから見えるプロセッサを含むコンピュータシステムです。 アドレス空間。
マルチプロセッサは、メモリを使用した作業の構成が異なります。
共有メモリシステム
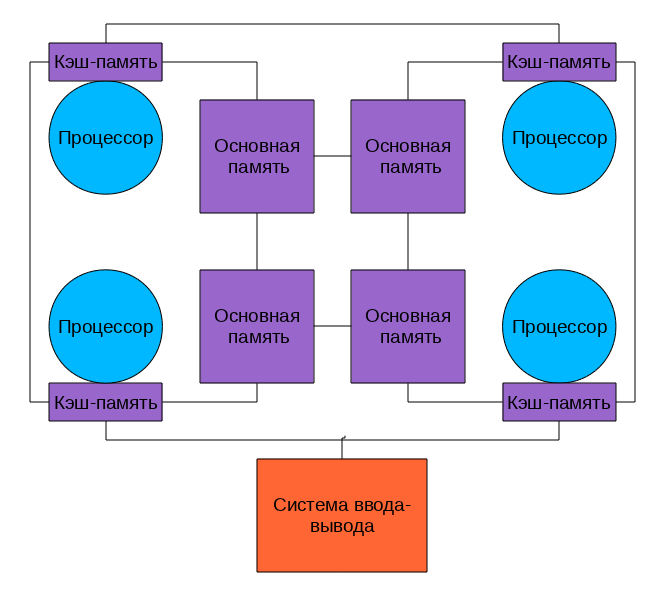
このようなシステムでは、複数のプロセッサ(およびプロセッサキャッシュ)が同じ物理RAMにアクセスできます。 このようなモデルは、多くの場合、対称型マルチプロセッシング(SMP)と呼ばれます。 このようなシステム設計におけるメモリへのアクセスは、UMA(Uniform Memory Access)と呼ばれます。 任意のプロセッサが任意のメモリ位置にアクセスでき、このアクセスの速度はメモリアドレスに依存しません。 ただし、各マイクロプロセッサーは独自のキャッシュを使用できます。

複数のプロセッサキャッシュサブシステムは通常、バスを介して共有メモリに接続されます
写真を見てみましょう。
何が私たちに良いですか?
どのプロセッサもすべてのメモリにアクセスし、すべて同じように機能します。 このようなシステムのプログラミングは、他のマルチアーキテクチャよりも簡単です。 悪いニュースは、すべてのプロセッサがバスを介してメモリにアクセスし、処理コアの数が増えると、このバスのスループットがすぐにボトルネックになることです。
頭痛とキャッシュの一貫性を確保する問題を追加します。
キャッシュの一貫性
マルチプロセッサコンピューターがあるとします。 上図のように、各プロセッサには独自のキャッシュがあります。 一部のプロセッサにメモリセルを読み取らせると、キャッシュに格納されます。 このセルが変更されていない限り問題ありません-高速キャッシュから読み取られ、何らかの形で計算に使用されます。
プログラムの結果、プロセッサの1つがこのメモリセルを変更し、不一致がない場合、他のすべてのプロセッサがこの更新を「見る」ようにするには、 すべてのプロセッサのキャッシュの内容を変更し、この更新中に何らかの方法で速度を落とす必要があります。
デスクトップコンピューターのように、コア/プロセッサの数が2であれば良いのですが、8または16であれば? そして、それらがすべて1つのバスを介してデータを交換する場合はどうでしょうか?
パフォーマンスの低下は非常に重大です。
マルチコアプロセッサー
タイヤの負荷を減らす方法は?
まず、一貫性を確保するために使用を停止できます。 これを行う最も簡単な方法は何ですか?
はい、はい、共有キャッシュを使用します。 これが、最新のマルチコアプロセッサの動作方法です。

写真を見てみましょう。前のものとは2つの違いがあります。
はい、キャッシュは今やすべてのものになりました。一貫性の問題は価値がありません。 そして、円が長方形に変わり、これはすべてのコアとキャッシュが同じチップ上にあるという事実を象徴しています。 実際には、画像はやや複雑で、キャッシュはマルチレベルで、一部は一般的、一部はそうではなく、それらの間の通信に特別なバスを使用できますが、すべての実際のマルチコアプロセッサはキャッシュの一貫性を確保するために外部バスを使用しないため、負荷が軽減されます。
マルチコアプロセッサは、最新のコンピューターのパフォーマンスを向上させる主な方法の1つです。
すでに6つの核プロセッサが生産されていますが、将来的にはさらに多くのコアがあります...制限はどこにありますか?
第一に、プロセッサの「核性」は放熱によって制限されます。1つのクリスタルで同時に動作するトランジスタが多くなるほど、このクリスタルが熱くなるほど、冷却が難しくなります。
また、2番目の大きな制限は、外部バスの帯域幅です。 多くのコアでは、粉砕するために大量のデータが必要であり、バス速度が十分でなくなるため、SMPを放棄する必要があります
NUMA
NUMA(Non-Uniform Memory Access-またはNon-Uniform Memory Architecture-Non-Uniform Memory Architecture)-共通のアドレス空間で、メモリアクセスの速度がその場所に依存するアーキテクチャ通常はプロセッサ「独自の」メモリがあり、アクセスはより速く、「異質な」アクセスはより遅くなります。
現代のシステムでは、このように見えます
プロセッサはメモリに接続され、高速バスを介して相互に接続されます。AMDの場合はHyper Transport、最新のIntelプロセッサの場合はQuickPath Interconnectです
なぜなら すべてのユーザーに共通のバスはありません。「自分の」メモリを操作する場合、システムのボトルネックになることはなくなります。
NUMAアーキテクチャにより、かなり効率的なマルチプロセッサシステムを作成できます。また、最新のプロセッサのマルチコアの性質を考慮すると、プロセッサとメモリの混同のキャッシュコヒーレンスを確保する複雑さによって主に制限される「1つのパッケージ」ですでに非常に深刻なコンピューティングパワーが得られます。
しかし、さらにパワーが必要な場合は、複数のマルチプロセッサを
マルチコンピューター
マルチコンピューターは、共有メモリのないコンピューティングシステムであり、相互に接続された多数のコンピューター(ノード)で構成され、各コンピューターには独自のメモリがあります。 共通のタスクで作業する場合、マルチコンピューターノードは相互にメッセージを送信することにより相互作用します。
多くの典型的なパーツから構築された最新のマルチコンピューターは、コンピューティングクラスターと呼ばれます。
最新のスーパーコンピューターのほとんどはクラスターアーキテクチャ上に構築され、高速ネットワーク(ギガビットイーサネットまたはInfiniBand)を使用して多くのコンピューティングノードを組み合わせ、現代の科学の発展において最大限のコンピューティング能力を実現することを可能にします。
彼らの力を制限する問題もかなり大きい。
これは:
1)数千のコンピューティングプロセッサを並列に実行するシステムのプログラミング
2)巨大な電力消費
3)基本的な信頼性の欠如につながる複雑さ
すべて一緒に
さて、強力なコンピューティングシステムを構築するためのほぼすべての技術と原則について簡単に説明しました。
今では、現代のスーパーコンピューターの構造を想像することができます。
これはマルチコンピュータークラスターであり、各ノードは複数のプロセッサーを備えたNUMAまたはSMPシステムであり、各プロセッサーは複数のコアを備え、各コアはスーパースカラー内部並列処理とベクトル拡張の可能性を備えています。 これに加えて、GPGPUアクセラレータは多くのスーパーコンピューターにインストールされています。
これらすべてのテクノロジーには利点と制限があり、アプリケーションには微妙な点があります。
そして今、このすべての素晴らしさを効率的にダウンロードしてプログラムしてみてください!
このタスクは簡単ではありませんが、非常に興味深いものです。
次に何かが来ますか?
情報源
並列計算インターネットの基礎スーパーコンピューター技術大学
parallels.ruのFlynnの分類
マルチプロセッサ、そのメモリ組織、およびIntelとAMDによる実装
コンピューティングシステムのパフォーマンスを向上させる方法としてのマルチコア
ウィキペディアとインターネット
PSこのテキストは、高性能コンピューティングの分野のテクノロジーに関する情報を整理して整理する試みとして生まれました。 不正確およびエラーが発生する可能性があります。コメントとコメントに非常に感謝します。