既存のすべてのアルゴリズムは、2つの大きなクラスに分類できます。
- ロスレス圧縮アルゴリズム。
- 非可逆圧縮アルゴリズム。
ロスレス圧縮とは、圧縮アルゴリズムと逆のアルゴリズムがあり、元の画像を正確に復元できることを意味します。 非可逆圧縮アルゴリズムの場合、逆アルゴリズムは存在しません。 画像を復元するアルゴリズムは、元の画像と必ずしも同じではありません。 圧縮および回復アルゴリズムは、高度な圧縮を達成し、同時に視覚的な画像品質を維持するように選択されます。
ロスレス圧縮アルゴリズム
RLEアルゴリズム
RLEシリーズのすべてのアルゴリズムは、非常に単純なアイデアに基づいています。要素の繰り返しグループは、カップル(繰り返しの数、繰り返し要素)に置き換えられます。 ビットシーケンスの例として、このアルゴリズムを検討してください。 ゼロと1のグループは、このシーケンスで交互になります。 さらに、グループには多くの場合、複数の要素があります。 次に、シーケンス11111 000000 11111111 00は、次の一連の数字5 6 8 2に対応します。これらの数字は、繰り返しの数を示します(単位でカウントが開始されます)が、これらの数字もエンコードする必要があります。 繰り返し回数は0から7の範囲にあると仮定します(つまり、繰り返し回数をエンコードするには3ビットで十分です)。 次に、上記のシーケンスは次の数字のシーケンス5 6 7 0 1 2でエンコードされます。元のシーケンスをエンコードするには21ビットが必要であり、RLE圧縮形式ではこのシーケンスは18ビットであると計算するのは簡単です。
このアルゴリズムは非常に単純ですが、その有効性は比較的低いです。 さらに、場合によっては、このアルゴリズムを適用しても減少することはなく、シーケンスの長さが長くなります。 たとえば、次のシーケンス111 0000 11111111 00を考えます。対応するRLシーケンスは次のようになります。3 4 7 0 1 2.元のシーケンスの長さは17ビット、圧縮されたシーケンスの長さは18ビットです。
このアルゴリズムは、白黒画像に最も効果的です。 また、より複雑なアルゴリズムを圧縮する中間段階の1つとしてもよく使用されます。
単語アルゴリズム
語彙アルゴリズムの背後にある考え方は、ソースシーケンス内の要素のチェーンをエンコードすることです。 このエンコードでは、元のシーケンスに基づいて取得される特別な辞書が使用されます。
語彙アルゴリズムにはファミリーがありますが、開発者のLepel、Ziv、Welchにちなんで名付けられた最も一般的なLZWアルゴリズムを検討します。
このアルゴリズムの辞書は、アルゴリズムが機能するときにコーディングチェーンで満たされたテーブルです。 圧縮コードをデコードすると、辞書は自動的に復元されるため、圧縮コードと一緒に辞書を転送する必要はありません。
辞書は、すべてのシングルトンチェーンによって初期化されます。 辞書の最初の行は、エンコードするアルファベットです。 圧縮は、辞書にすでに記録されている最長のチェーンを検索します。 辞書にまだ書き込まれていないチェーンが検出されるたびに、そこに追加され、辞書に既に書き込まれているものに対応する圧縮コードが表示されます。 理論的には、辞書のサイズに制限はありませんが、実際にはこのサイズを制限することは理にかなっています。時間が経つにつれて、テキストに見られなくなったチェーンが会い始めます。 さらに、テーブルのサイズを2倍にすると、圧縮コードを保存するために余分なビットを割り当てる必要があります。 このような状況を防ぐために、すべてのシングルトンチェーンでテーブルの初期化を象徴する特別なコードが導入されています。
圧縮アルゴリズムの例を考えてみましょう。 文字列のカッコウカッコウを絞る 辞書が32の位置に対応すると仮定します。つまり、各コードは5ビットを占有します。 最初に、辞書は次のように入力されます。
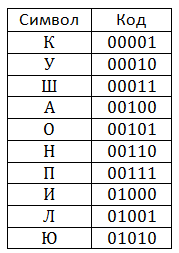
このテーブルは、情報を圧縮する側と展開する側の両方にあります。 次に、圧縮プロセスについて検討します。
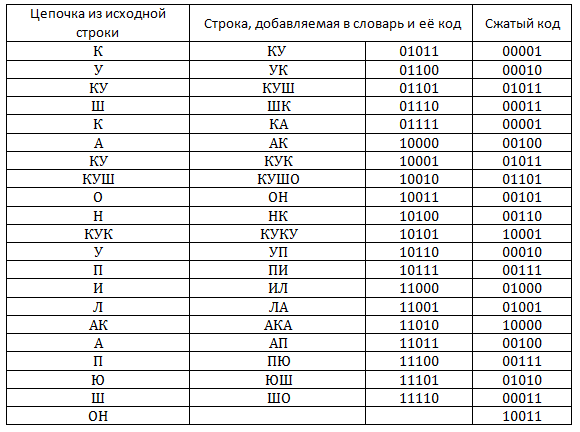
この表は、辞書に記入するプロセスを示しています。 結果の圧縮コードは105ビットかかり、ソーステキスト(1文字のエンコードに4ビットを使用する場合)は116ビットかかることを計算するのは簡単です。
実際、デコードプロセスはコードの直接復号化に短縮され、エンコード中と同様にテーブルが初期化されることが重要です。 次に、デコードアルゴリズムを検討します。

i番目のステップで辞書に追加された行は、i + 1でのみ完全に決定できます。 明らかに、i番目の行はi + 1行の最初の文字で終了する必要があります。 T.O. 辞書を復元する方法を見つけました。 興味深いのは、cScScという形式のシーケンスがエンコードされている場合です。ここで、cは1文字、Sは文字列で、単語cSはすでに辞書にあります。 一見すると、デコーダーはこの状況を解決できないように見えるかもしれませんが、実際には、このタイプのすべての行は常に同じ文字で終わるはずです。
統計エンコーディングアルゴリズム
このシリーズのアルゴリズムは、最も頻繁なシーケンス要素に最も短い圧縮コードを提供します。 つまり 同じ長さのシーケンスは、さまざまな長さの圧縮コードによってエンコードされます。 さらに、シーケンスが頻繁に発生するほど、対応する圧縮コードは短くなります。
ハフマンアルゴリズム
ハフマンアルゴリズムを使用すると、プレフィックスコードを作成できます。 プレフィックスコードをバイナリツリーのパスと見なすことができます。ノードから左の息子に渡すことは、コードの0と右の息子に対応します。1。ツリーの葉をエンコード文字でマークすると、プレフィックスコードの表現がバイナリツリーとして取得されます。
ハフマン木を構築し、ハフマンコードを取得するためのアルゴリズムを説明します。
- 入力アルファベットの文字は、空きノードのリストを形成します。 各シートには、シンボルの出現頻度に等しい重みがあります
- 最小の重みを持つ2つのフリーツリーノードが選択されます
- 親は、総重量に等しい重量で作成されます
- 空きノードのリストに親が追加され、その2つの子がこのリストから削除されます。
- 親を離れる1つのアークはビット1にマッピングされ、もう1つのアークはビット0にマッピングされます
- 2番目から始まる手順は、空きノードのリストに空きノードが1つだけ残るまで繰り返されます。 ツリーのルートと見なされます。
このアルゴリズムを使用すると、文字の出現頻度を考慮して、特定のアルファベットのハフマンコードを取得できます。
算術コーディング
算術コーディングアルゴリズムは、要素のチェーンを分数でエンコードします。 この場合、要素の頻度分布が考慮されます。 現時点では、算術符号化アルゴリズムは特許によって保護されているため、主要なアイデアのみを検討します。
アルファベットをそれぞれN個の文字a1、...、aN、およびその出現頻度p1、...、pNで構成します。 半区間[0; 1)をN個の互いに素な半区間に分割します。 各半区間は要素aiに対応し、半区間の長さは周波数piに比例します。
コーディング部分は次のように構築されます。ネストされた間隔のシステムは、元のパーティション内の要素の位置に対応して、後続の各半間隔が前の場所を取るように構築されます。 すべての間隔が互いに入れ子になった後、結果の半間隔から任意の数を取ることができます。 この番号をバイナリコードで記述すると、圧縮コードになります。
デコード-既知の確率分布に従って分数をデコードします。 明らかに、デコードのために、頻度テーブルを保存する必要があります。
算術コーディングは非常に効率的です。 その助けを借りて得られたコードは、理論的な限界に近づいています。 これは、特許の有効期限が切れると、算術コーディングがますます一般的になることを示唆しています。
非可逆圧縮アルゴリズム
多くの非常に効率的なロスレス圧縮アルゴリズムにもかかわらず、これらのアルゴリズムは十分な程度の圧縮を提供しない(およびできない)ことが明らかになります。
(画像に適用される)非可逆圧縮は、人間の視覚の特性に基づいています。 JPEG画像圧縮アルゴリズムの背後にある基本的なアイデアについて説明します。
JPEG圧縮アルゴリズム
JPEGは現在、最も一般的な非可逆画像圧縮方式の1つです。 このアルゴリズムの基礎となる基本的な手順を説明します。 ピクセルあたり24ビットの色深度の画像が圧縮アルゴリズムに入力されると仮定します(画像はRGBカラーモデルで表示されます)。
YCbCr色空間に変換する
YCbCrカラーモデルでは、画像を輝度成分(Y)と2つの色差成分(Cb、Cr)として表示します。 人間の目は色よりも明るさの影響を受けやすいため、JPEGアルゴリズムは輝度成分(Y)に最小限の変更を加え、色差成分に大きな変更を加えることができます。 転送は、次の式に従って実行されます。
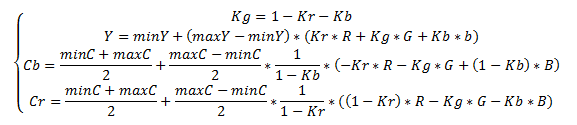
KrとKbの選択は、機器によって異なります。 通常、Kb = 0.114、Kr = 0.299 最近では、Kb = 0.0722、Kr = 0.2126も使用されており、これは最新のディスプレイデバイスの特性をよりよく反映しています。
色成分のサブサンプリング
YCbCr色空間への変換後、離散化が実行されます。 次の3つのサンプリング方法のいずれかが可能です。
4
- :4:4-ダウンサンプリングなし。
- 4:2:2-色成分は1を介して水平方向に変化します。
- 4:2:0-色成分は水平方向に1行で変化し、垂直方向では線に沿って変化します。
2番目または3番目の方法を使用する場合、それぞれ情報の1/3または1/2を取り除きます。 明らかに、失う情報が多いほど、最終画像の歪みが強くなります。
離散コサイン変換
画像はコンポーネント8 * 8ピクセルに分割され、DCTが各コンポーネントに適用されます。 これにより、コードのエネルギー圧縮が行われます。 変換はコンポーネントに個別に適用されます。
量子化
人は、実際には高周波成分の変化に気付かないため、高周波の原因となる係数をより低い精度で保存できます。 このため、DCTの結果として得られた行列の成分ごとの乗算(および丸め)が量子化行列で使用されます。 この段階で、圧縮率を調整することもできます(量子化マトリックスの成分がゼロに近づくほど、最終マトリックスの範囲が狭くなります)。
ジグザグマトリックスバイパス
ジグザグマトリックスバイパスは、図に示すバイパスの特別な方向です。

さらに、ほとんどの実際の画像では、非ゼロの係数は最初に行き、ゼロは最後に近づきます。
RLEエンコーディング
特別なタイプのRLEコーディングが使用されます。数値のペアが出力され、ペアの最初の数値はゼロの数をエンコードし、2番目はゼロのシーケンスの後の値です。 つまり シーケンス0 0 15 42 0 0 0 44のコードは次のようになります(2; 15)(0; 42)(3; 44)。
ハフマンコーディング
上記のハフマンアルゴリズムが使用されます。 エンコード時には、事前定義されたテーブルが使用されます。
デコードアルゴリズムは、実行された変換を逆にすることにあります。
アルゴリズムの利点には、高度な圧縮(5回以上)、比較的低い複雑さ(特別なプロセッサ命令を考慮に入れたもの)、および特許の清浄度が含まれます。 欠点は、人間の目に見えるアーティファクトです。
フラクタル圧縮
フラクタル圧縮は比較的新しい分野です。 フラクタルは、自己相似性の特性を持つ複雑な幾何学図形です。 フラクタル圧縮アルゴリズムは現在活発に開発されていますが、それらの基礎となるアイデアは次の一連のアクションで説明できます。
圧縮プロセス:
- 画像の重複しない領域(ドメイン)への分離。 一連のドメインがイメージ全体をカバーする必要があります。
- ランクエリアの選択。 ランク付けされた領域はオーバーラップする場合があり、画像全体をカバーすることはできません。
- フラクタル変換:各ドメインに対して、アフィン変換後にドメインを最も正確に近似するランク領域が選択されます。
- アフィン変換パラメーターの圧縮と保存。 このファイルには、ドメインの位置とランキング領域に関する情報、およびアフィン変換の圧縮係数が含まれています。
イメージの回復手順:
- 同じサイズのAとBの2つの画像を作成します。領域のサイズと内容は関係ありません。
- イメージBは、圧縮プロセスの最初の段階と同じ方法でドメインに分割されます。 領域Bの各ドメインに対して、画像Aのランク領域の対応するアフィン変換が実行されます。これは、圧縮ファイルの係数によって記述されます。 結果はエリアBに配置されます。変換後、完全に新しい画像が取得されます。
- データを領域Bから領域Aに変換します。このステップはステップ3を繰り返し、画像AとBのみが反転されます。
- 画像AとBが区別できなくなるまで、手順3と4を繰り返します。
結果の画像の精度は、アフィニティ変換の精度に依存します。
フラクタル圧縮アルゴリズムの複雑さは、整数演算と特殊なかなり複雑な方法を使用して丸め誤差を減らすことです。
フラクタル圧縮の特徴は、その顕著な非対称性です。 圧縮と回復のアルゴリズムは大きく異なります(圧縮にはさらに多くの計算が必要です)。