Tessnet2およびMODI
当然、最初は既製のソリューションを探しました。 Googleが最初に発行したのは、Tesseractライブラリ、またはむしろ.NETのラッパーであるTessnet2です。 残念ながら、詳細な調査により、それは私には適していないことが判明しました。 Tesseractの2番目のバージョンでは、かなりの数のメモリリークが発生しました。これは、Tessnet2を使用してプログラムを10分間実行した後、OutOfMemoryExceptionでアプリケーションがクラッシュしたため、私には不向きでした。 Tesseractのページでは、3番目のバージョンにはリークはないはずですが、Tesseract3の有効なラッパーも見つかりませんでした。
また、MODIツール(Microsoft Office Document Imaging)はファイルにしか認識されないため(認識のためにビットマップクラスのインスタンスを渡すことはできません)、私には向いていませんでした。
.NETの他の無料の文字認識ライブラリとそれらに関連する問題をGoogleで短時間検索した後、そのような場合に自分の小さなライブラリを作成する方が簡単だと判断しました。 さらに、このタスクは非常に興味深いものです。
私たちは何を持っています:
- シンボルはまったく歪んでいません。 つまり、captchaを使用してcaptchaを認識することはできません
- 認識可能な文字のセットは定数であり、各文字について、その画像を含むファイルがあります
- 認識する少数の文字。 文字が多いほど、認識される時間が長くなります
アイデア
結果として何を得たかったのですか? 画像、認識可能な文字のセットを含む特殊ファイルを転送できるメソッドを持つクラスを取得し、出力で認識された文字列を取得します。 このようなもの:
var playerStacks = new OCRReader(OCRFont.Load("MyFont.pft")), Color.Black, useForeColor: false);
var stackString = playerStacks.Recognize(imageToRecognition);
また、このようなフォントファイルを作成し、特定の画像で作成されたフォントを確認するためのユーティリティがあればいいと思いました。 ユーティリティは利便性のみを目的としています。 ユーティリティを使用して実行できるすべてのアクションは、コードでも実行できます。
実装
すべての機能は、OCRSymbol、OCRFont、およびOCRReaderの3つのクラスに分散されています。
OCRSymbol-シンボルを説明します。名前、幅、高さ、セット全体の最上位シンボルに対するシンボルの下方へのシフト、シンボルに特徴的なポイントのリスト、および背景を構成するポイントのリスト。
OCRFontは、BinaryFormaterを使用してシリアル化された文字セットです。
OCRReader-読み取り文字を1つずつ調整します。 また、読み取り戦略も設定します。 実際、このクラスのインスタンスを作成するときに、色を設定できます。 この色は、背景色(この色ではないすべての記号)として、または記号の色(この色ではないすべての背景)として使用されます。 これは、背景で複数の色が使用されている場合、またはシンボルが複数の色で描かれている場合に必要です。
シンボルが複数の色で描かれている場合(黒い背景、その他はすべてシンボルです)

背景がモノクロではない場合(背景は緑のグラデーションで、文字は白で描画されます)

認識アルゴリズムは非常に簡単です。 各キャラクターは、2つのユニバーサルリストによって記述されます。 最初-シンボルに存在する必要があるポイント(良好)、2番目-存在しない、つまり背景(悪い)。 次の文字と比較するとき、背景ポイントのリストが最初に渡されます。次のポイントをチェックするとき、認識されたイメージの対応するポイントが背景でない場合(OCRReaderの作成時に背景色が設定されます)、サイクルが終了し、次の文字との比較に進みます。 バックグラウンドポイントのリストが正常に渡された場合、同様にシンボルのポイントのリストを実行します。 不一致-次のシンボルとの比較に進みます。 すべてのチェックが成功した場合、シンボルが認識され、次のシンボルの認識に進むことができます。
追加のユーティリティ
文字ごとにポイントのリストを手動で記述したくなかったので、指定されたディレクトリからすべての画像ファイルを自動的にインポートし、ファイルの名前と指定された背景色でこれらのリストを作成するユーティリティを作成しました。 もちろん、ほとんどの場合、手動調整が望ましいでしょう。 画像内のすべてのピクセルが背景ポイントとシンボルポイントのリストに散らばっているので。 ほとんどの場合、この精度は必要ありません。 文字を一意に識別するには、各リストから10〜20ポイントを示すだけで十分です。 たとえば、私の例では、シンボル「6」の場合、次のピクセルのリストで十分でした(赤-背景、緑-シンボル、白-チェックなし)。 最初のスクリーンショット-シンボルはユーティリティによって説明され、2番目のスクリーンショットは手動編集後です。 それらは同じように認識されます。 さらに特徴的なポイントを作成することができます。

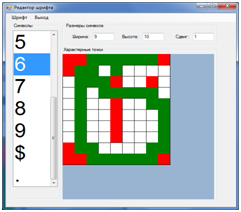
以前のユーティリティを使用して作成されたフォントファイルの動作を確認するユーティリティも作成されました。
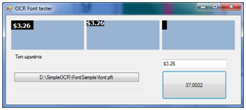
トリミング(文字の境界に合わせて画像をトリミング)を考慮して5文字を認識するには、37ミリ秒かかりました。 完全なアルファベットの場合、認識時間自体は長くなります。
ソースコード
レコグナイザークラスを備えたライブラリ、フォントファイルを作成および編集して画像を確認するユーティリティ、フォント画像の例、およびVisual Studio 2010のソースコードは、mediafire.comからダウンロードできます。
またはGitHub.comから
おわりに
Bitmap.Cloneメソッドの動作は非常に遅いため、AForge .NETライブラリを使用してエッジ周辺の画像をトリミングします。 私の仕事が私以外の誰かに役立つなら、私はうれしいです。