Kinectのブレークスルーは、いくつかのコンポーネントを提供します。 その鉄はよく考えられており、手頃な価格でその機能を果たします。 しかし、鉄の深さを素早く測定することに驚いた後、彼(Kinect)が人体を追跡する方法に注意が必然的に引き付けられます。 この場合、ヒーローはかなり古典的なパターン認識技術ですが、優雅に実装されています。
体の位置を追跡するデバイスは以前から存在しています。 しかし、彼らの最大の問題は、ユーザーが単純な比較でアルゴリズムを認識する基準位置にいる必要があることです。 その後、身体の動きを追跡する追跡アルゴリズムが使用されます。 主なアイデア:最初のフレームで手として識別される領域がある場合、次のフレームでこの手は非常に遠くまで移動できません。つまり、単に近くの領域を識別しようとしているだけです。
理論的には追跡アルゴリズムは優れていますが、実際には何らかの理由で体の位置が失われると失敗します。 そして、たとえ短時間であっても、追跡対象者をブロックする他のオブジェクトにうまく対処できません。 さらに、複数の人を追跡することは困難です。 そして、そのような「トラック損失」があれば、かなり長い時間をかけて復元できます。
それでは、Microsoft Researchの人たちは、Kinectがはるかにうまく機能するというこの問題をどのように処理しましたか?
彼らは元の原則に戻り、追跡に依存しない身体認識システムを構築することに決めましたが、各ピクセルの局所分析に基づいて身体の部分を見つけます。 従来のパターン認識は、多くのパターンでトレーニングされた意思決定構造で機能します。 それを機能させるためには、通常、分類子に多数の属性値を提供します。これには、オブジェクトを認識するために必要な情報が含まれていると思われます。 多くの場合、有益な機能を選択するタスクは最も難しいタスクです。
選ばれた兆候は驚くかもしれません。なぜなら、それらは単純であり、身体の部分を特定するための情報提供の意味で明らかではないからです。 すべての記号は、単純な式から取得されます
f = d(x + u / d(x))-d(x + v / d(x))
ここで、 u、vは変位ベクトルのペア、 d(x)はピクセル深度、つまりKinectからxに投影される点までの距離です。 これは非常に単純な記号です。実際には、元のピクセルからuおよびvだけオフセットした2ピクセルの深さの違いにすぎません。 (uとvを変えることにより、一連の機能が得られます。作業自体(以下のリンク)では、すべてがより明確になります。-翻訳に注意してください。)
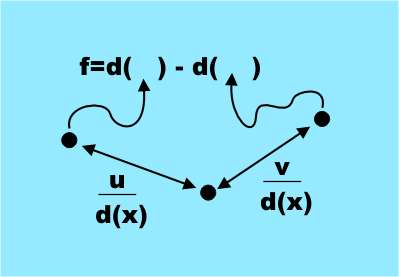
唯一の問題は、オフセットが元のピクセルの深さで正規化される、つまりd(x)で除算されることです。 これにより、変位は深度に依存せず、身体の目に見える寸法と相関します。
明らかに、これらの機能は、ピクセルの周囲の領域の3次元形状に関連する何かを測定します。 しかし、それらを区別するのに十分かどうか、たとえば、1足1足でも問題です。
チームが実行する次の段階は、「意思決定の森」と呼ばれる分類子、つまり一連の決定木の訓練です。 各ツリーは、以前に身体の対応する部分に結び付けられていた深い画像の特徴のセットで訓練されました。 つまり、画像のテストセットで身体の特定の部分の正しい分類を生成し始めるまで、木は再構築されました。 1000コアのクラスターで100万枚の画像につき3本の木だけを学習するのに約1日かかりました。
訓練された分類子は、ピクセルが身体の特定の部分に属する確率を与えます。 そして、アルゴリズムの次の段階では、各タイプの部分に対して最大の確率でエリアを選択するだけです。 たとえば、「足」分類器がこの領域で最大の確率を与えた場合、その領域は「足」として分類されます。 最後の段階は、体の特定の部分として識別された領域に対する関節の推定位置の計算です。 この図では、身体のさまざまな部分の確率の最大値が色付きの領域で示されています。
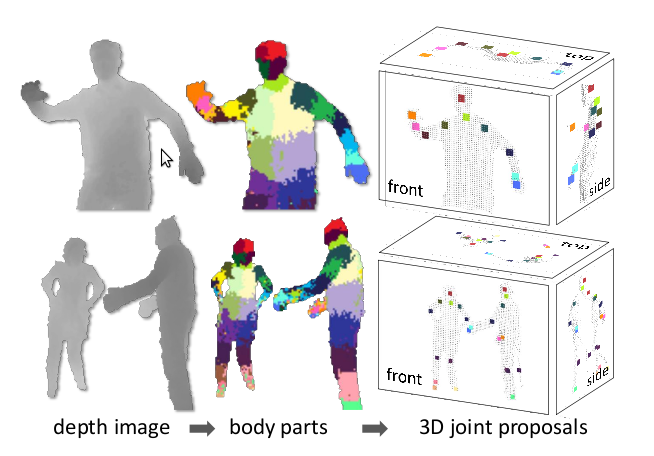
これをすべて計算するのは非常に簡単で、少なくとも3ピクセルの深度値があり、GPUを使用できることに注意してください。 したがって、システムは1秒あたり200フレームを処理でき、初期の基準ポーズは必要ありません。 各フレームは個別に分析され、トラッキングは行われないため、身体の画像が失われる問題はありません。 また、複数のボディを同時に処理できます。
これがどのように機能するかについて少し理解できたので、Microsoft Researchのビデオをご覧ください。
(代替ソース )
Kinectは大きな成果であり、かなり標準的な古典的なパターン認識に基づいていますが、正しく適用されています。 また、大規模なマルチコアコンピューティングパワーの可用性を考慮する必要があります。これにより、トレーニングセットを十分に大きくすることができました。 これは、何世紀にもわたって学習に費やすことができる認識方法の機能の1つですが、分類自体は非常に迅速に実行できます。 おそらく、パターン認識と機械学習の優れた作業に必要な計算能力が最終的にそれらを実用的にする「黄金時代」に突入しているのでしょう。
実際の公開 (Pdf、4.6 Mb)
PS
1.これは翻訳です。 Habrの包括的な知恵は、サンドボックスで最初に公開されたときにトピックの種類を変更するような些細なことではないため、適切に設計されていません。
ハリー・フェアヘッドとIプログラマーのオリジナル 。
2. Habrの包括的な知恵も急いで苦しむことはないので、私はすでにこのトピックが中程度に過ぎないと判断し、別の場所で公開しました。 だから誰かが彼を見たなら、誰にも言わないでください。 ただし、Habr向けであることを知っておいてください。 :)