それでも、イテレータを使用してイテレータ++ではなく++イテレータを記述する場合に意味があるかどうかを判断することにしました。 この問題に対する私の関心は、芸術への愛からではなく、実際的な考慮から生じました。 エラーを検索する方向だけでなく、コードの最適化に関するヒントを発行する方向でも、PVS-Studioを長年開発したいと考えていました。 ++イテレータを記述する方がよいというメッセージを発行することは、最適化の観点から非常に適切です。
しかし、私たちの時代にこの推奨事項はどの程度関連していますか? たとえば、古代では、計算を繰り返さないことが勧められていました。 代わりに良い形と見なされました:
X = A + 10 + B; Y = A + 10 + C;
このように書く:
TMP = A + 10; X = TMP + B; Y = TMP + C;
今、そのようなささいな手動の最適化は無意味です。 コンパイラーは、このタスクを悪化させることはありません。 余分なコードの混乱のみ。
特につまらないものに注意してください。 はい、別々に計算するために、複数回使用される計算と長い式を繰り返さない方が良いです。 私が引用したような単純なケースを最適化することは意味がないと言います。
気が散ります。 アジェンダに関する質問は、アドバイスが接尾辞の代わりに接頭辞の増分を演算子に使用するかどうかです。 別の微妙さであなたの頭を詰まらせることは価値がありますか? おそらく、コンパイラは長い間、後置インクリメントを最適化できました。
初めに、議論中のトピックに精通していない人のための小さな理論があります。 残りは少し下にスクロールできます。
プレフィックス増分演算子は、オブジェクトの状態を変更し、既に変更された形式で自分自身を返します。 std :: vectorを操作するイテレータクラスのプレフィックス増分演算子は、次のようになります。
_Myt&演算子++()
{//プリインクリメント
++ _ Myptr;
return(* this);
}
後置インクリメントの場合、状況はより複雑です。 オブジェクトの状態は変更されますが、前の状態が返されます。 追加の一時オブジェクトが発生します。
_Myt演算子++(int)
{//ポストインクリメント
_Myt _Tmp = *これ;
++ *これ;
return(_Tmp);
}
イテレータの値のみを増やしたい場合は、プレフィックス形式が望ましいことがわかります。 したがって、プログラムのマイクロ最適化のヒントの1つは、「for(it = a.begin(); it!= A .end; it ++)。」 後者の場合、不必要な一時オブジェクトが作成され、パフォーマンスが低下します。
Scott Meyersの本「C ++の最も効果的な使用」で、これらすべてを詳細に読むことができます。 プログラムとプロジェクトを改善するための35の新しい推奨事項」(ルール6.インクリメント演算子とデクリメント演算子のプレフィックス形式を区別する)[1]。
理論は終わりました。 練習に移りましょう。 接尾辞の増分を接頭辞の増分で置き換えることはコードで意味がありますか?
size_t Foo(const std :: vector <size_t>&arr)
{
size_t sum = 0;
std :: vector <size_t> :: const_iterator it;
for(it = arr.begin(); it!= arr.end(); it ++)
sum + = * it;
戻り値;
}
私はあなたが哲学の分野に入ることができることを理解しています。 たとえば、コンテナはベクトルではなく、イテレータが非常に複雑で重いオブジェクトである別のクラスになる可能性があります。 イテレータをコピーするときは、データベースへの新しい接続を作成する必要があります。 したがって、常に++と記述する必要があります。
しかし、これは理論上です。 しかし、実際には、コードのどこかでこのようなループに遭遇した場合、++を++に置き換えることは理にかなっていますか? コンパイラに頼る方が良いのではないでしょうか。コンパイラがなくても、余分なイテレータが捨てられる可能性があると思いますか?
答えは奇妙になりますが、その理由はさらなる実験から明らかになります。
はい、++に置き換える必要があります。
はい、コンパイラは最適化を実行し、使用する増分に違いはありません。
「中間コンパイラ」を選択し、Visual Studio 2008のテストプロジェクトを作成しました。これには、++と++を使用して合計を計算する2つの関数があり、動作時間を測定します。 ここからプロジェクトをダウンロードできます。 速度が測定された関数のコード:
1)後置インクリメント。 イテレータ++。
std :: vector <size_t> :: const_iterator it; for(it = arr.begin(); it!= arr.end(); it ++) sum + = * it;
2)プレフィックスの増分。 ++イテレータ。
std :: vector <size_t> :: const_iterator it; for(it = arr.begin(); it!= arr.end(); ++ it) sum + = * it;
リリースバージョンの速度:
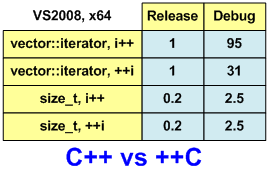
イテレータ++。 合計時間:0.87779
++イテレータ。 合計時間:0.87753
これは、コンパイラが後置インクリメントを最適化できるかどうかという質問に対する答えです。 たぶん。 実装(アセンブラコード)を見ると、両方の機能が同じ命令セットで実装されていることがわかります。
そして、質問に答えます。なぜ++から++に変更する価値があるのでしょうか。 デバッグバージョンの速度を測定しましょう。
イテレータ++。 合計時間:83.2849
++イテレータ。 合計時間:27.1557
90倍ではなく30倍遅くなるような方法でコードを書くのは理にかなっています。
もちろん、多くの場合、デバッグバージョンの速度はそれほど重要ではありません。 ただし、プログラムが時間内に重要なことを行う場合、そのようなスローダウンが重大になる可能性があります。 たとえば、単体テストに関して。 そのため、デバッグバージョンの速度を最適化することは理にかなっています。
さらに、インデックス作成に古き良きsize_tを使用するとどうなるかを実験しました。 もちろん、これはこのトピックには当てはまりません。 イテレータはインデックスと比較できず、これらはより高いレベルのエンティティであると理解しています。 しかし、好奇心から、次の機能の速度を記述して測定しました。
1)size_t型の古典的なインデックス。 i ++。
for(size_t i = 0; i!= arr.size(); i ++) sum + = arr [i];
2)size_t型の古典的なインデックス。 ++ i。
for(size_t i = 0; i!= arr.size(); ++ i) sum + = arr [i];
リリースバージョンの速度:
イテレータ++。 合計時間:0.18923
++イテレータ。 合計時間:0.18913
デバッグバージョンの速度:
イテレータ++。 合計時間:2.1519
++イテレータ。 合計時間:2.1493
予想どおり、i ++と++ iの速度は一致していました。
ご注意 size_tを使用したコードは、配列の境界を超えるチェックがないため、反復子よりも高速です。 イテレータループは、「#define _SECURE_SCL 0」と入力することにより、リリースバージョンで高速に作成できます。
速度測定の結果を簡単に評価できるように、それらを表形式で示します(図1)。 イテレータ++を使用したリリースバージョンの実行時間を単位として、結果を再計算しました。 簡単にするために、もう少し丸みを帯びた数字を使用します。
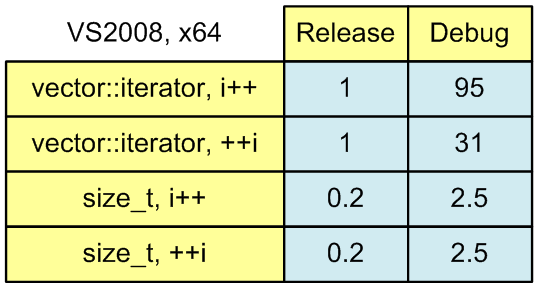
図1.合計計算アルゴリズムの動作時間。
誰もが自分で結論を出すことができます。 それらは解決されるタスクのタイプに依存します。 私自身のために、私は次のことをしました:
- 私はそのようなマイクロ最適化の賢明さを確信しました。 PVS-Studioでは 、前の状態が使用されていない場合、postfix iterator incrementを検索する価値があります。 一部のプログラマは、この機能が便利だと感じています。 そして、それが干渉する場合、残りは常に設定でこの診断を無効にすることができます。
- 私はいつも++を書きます。 以前にこれをやったことがあります。 しかし、彼は「念のため」にそれをしました。 デバッグバージョンを定期的に起動することが重要だからです。 もちろん、一般的に、++は実行時の影響が非常に小さくなります。 ただし、さまざまな場所でこのような小さな最適化を行わないと、手遅れになります。 プロファイラーはほとんど役に立ちません。 遅い場所は、コード全体で「薄い層で塗り付けられます」。
- PVS-Studioアナライザーは、std :: vector、std :: set、std :: stringクラスなどのさまざまな関数の内部でますます多くの時間を費やしていることに気付きます。 ますます多くの診断ルールが登場するにつれて、この時間はますます長くなり、STLを使用してそれらを記述するのが便利です。 それで、プログラムが文字列や配列などの独自の特化したクラスを持つとき、その恐ろしい時が来たかどうかを考えています。 しかし、それは私のことです...あなたは私に耳を傾けません! 私は皮肉なことを言います...シッ...
PS
今、誰かが早すぎる最適化は悪であると言うでしょう[2]。 最適化が必要な場合は、プロファイラーを使用してボトルネックを探す必要があります。 私はすべてを知っていること。 長い間、特定のボトルネックはありませんでした。 しかし、4時間以内にテストの完了を待つと、速度の20%でさえ勝つことはすでに良いと考え始めます。 また、この最適化は、イテレーター、構造のサイズ、場合によってはSTLまたはBoostの拒否などで構成されます。 一部の開発者は私をよく理解していると思います。
書誌リスト
- Meyers S. C ++の最も効果的な使用法。 プログラムとプロジェクトを改善するための35の新しい推奨事項:Per。 英語から -M .: DMK Press、2000 .-- 304 p。:病気 (「プログラマー向け」シリーズ)。 ISBN 5-94074-033-2。 BBK 32.973.26-018.1。
- エレナ・サガラエワ。 時期尚早の最適化。 http://alenacpp.blogspot.com/2006/08/blog-post.html
更新: 「 正しくベンチマークする方法(イテレーターを含む) 」の記事の後、プロジェクトコードを修正し、新しい測定を行い、記事をわずかに修正しました。 リリースバージョンに変更はありませんが、デバッグには大きな違いがあります。 ただし、これは記事の正確性、その内容、結論には影響しません。