要するに、XapianはC ++で書かれたテキスト情報のインデックス作成ツールであり、インデックス化された情報のデータベースを検索する機能を備えています。 動作するためにインストールされたサーバーを必要としません;そのライブラリは十分です。 何百万ものドキュメントで測定される膨大な量の情報(1.5Tbまで検証済み)を処理できます。 これは、SphinxとApache Luceneの競合製品です。
これらの3つの製品の中から、.Netから使用できる能力が選ばれました。
まず、.Net用のXapian dll 'kiをダウンロードする必要があります 。
次に、C ++でコンパイルされたラッピングdllにアクセスしようとすると、別の補助DLL- Zlib1.dllが例外なしでスローされます。
実際には仕事のために、これが必要なすべてです。 プロジェクトを作成できます。 XapianCSharp.dllがすぐにリファレンスに追加されます。 _XapianSharp.dllおよびzlib1.dllをプロジェクトに(コンテンツとして)追加し、出力ディレクトリにコピーを常にコピーとしてマークします。
作業をテストするために2つの関数を作成します。
.... using Xapian; .... // , // string xapianBase="H:\\XapianDB\\xap.db"; .... // // private void IndexFolder(string path) { try { if (Directory.Exists(path)) { string[] files=Directory.GetFiles(tbIndexFolder.Text); using (WritableDatabase database=new WritableDatabase(xapianBase, Xapian.Xapian.DB_CREATE_OR_OPEN)) { using (TermGenerator indexer=new TermGenerator()) { using (Stem stemmer=new Xapian.Stem("russian")) { indexer.SetStemmer(stemmer); foreach (string file in files) { using (Document doc=new Document()) { // , doc.SetData(file); indexer.SetDocument(doc); // indexer.IndexText(File.ReadAllText(file, Encoding.GetEncoding(1251))); // database.AddDocument(doc); } } } } } } } catch (Exception ex) { Write("Exception: "+ex.ToString()); } } private void Search(string searchText) { try { // using (Database database=new Database(xapianBase)) { using (Enquire enquire=new Enquire(database)) { using (QueryParser qp=new QueryParser()) { using (Stem stemmer=new Stem("russian")) { Write(stemmer.GetDescription()); qp.SetStemmer(stemmer); qp.SetDatabase(database); qp.SetStemmingStrategy(QueryParser.stem_strategy.STEM_SOME); using (Query query=qp.ParseQuery(searchText)) { Write("Parsed query is: "+query.GetDescription()); enquire.SetQuery(query); // // 100 MSet matches=enquire.GetMSet(0, 100); Write(String.Format("{0} results found.", matches.GetMatchesEstimated())); Write(String.Format("Matches 1-{0}:", matches.Size())); // MSetIterator m=matches.Begin(); // while (m!=matches.End()) { Write(String.Format("{0}: {1}% docid={2} [{3}]\n", m.GetRank()+1, m.GetPercent(), m.GetDocId(), m.GetDocument().GetData())); ++m; } } } } } } } catch (Exception ex) { Write("Exception: "+ex.ToString()); } }
Write関数を好みに合わせて作成します。
テキストファイルを含むディレクトリを作成するか、既存のディレクトリを使用して、IndexFolder(directory_name)を呼び出し、ファイルのインデックスが作成されるまで待ちます。 また、検索用のキーワードを含む文字列をスペースで区切って渡すSearchを呼び出すことができます。
テスト。
鉄の構成:
Intel Pentium III 996Mhz
ラム256Mb
インデックスファイルの数:641489
インデックスファイル:2,38Gb
ファイルのインデックス作成時間:1週間以上(ハードウェアを思い出してください。4xCoreでは、操作に数時間かかる可能性が高く、それに応じてスワップによりパフォーマンスが低下する場合があります)
インデックス負荷
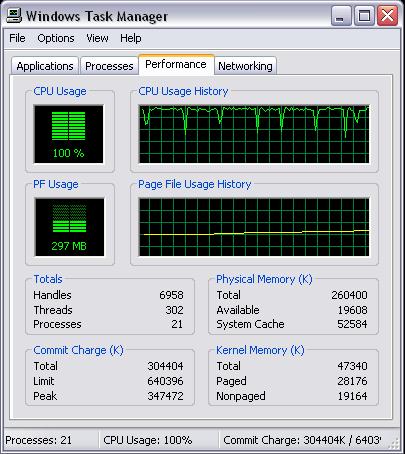
テーブル平均検索時間
| 単語数 | 検索する | 時間 |
| 1 | 1 | 1883ミリ秒 |
| 1 | 2 | 28ミリ秒 |
| 1 | 3 | 31ミリ秒 |
| 2 | 1 | 175ミリ秒 |
| 2 | 2 | 36ミリ秒 |
| 2 | 3 | 41ミリ秒 |
| 3 | 1 | 1074ミリ秒。 |
| 3 | 2 | 35ミリ秒 |
| 3 | 3 | 37ミリ秒 |
指標は非常に楽観的で、特にこのような弱い車にとっては楽観的です。
ソース:
codeprojectに関する記事
公式サイト