紙から電子メディアに情報を転送するタスクは、文書管理システムで発生するニーズのフレームワーク内だけでなく関連しています。 現代の情報技術により、人類が蓄積した情報リソースへのアクセスを大幅に簡素化することができます。ただし、それらは電子形式に変換されます。
最も簡単で最速の方法は、スキャナーでドキュメントをスキャンすることです。 作業の結果は、ドキュメントのデジタル画像、つまりグラフィックファイルです。 グラフィックと比較して、情報のテキスト表現がより望ましいです。 このオプションを使用すると、情報の保存と送信のコストを大幅に削減でき、電子文書の使用と分析に関するすべての可能なシナリオを実装できます。 したがって、実用的な観点から最も興味深いのは、紙媒体のテキスト電子文書への翻訳です。
ドキュメントページのラスターイメージが認識システムに入力されます。 認識アルゴリズムが機能するためには、入力画像が可能な限り最高の品質であることが望ましい。 画像のノイズが多く、鮮明でなく、コントラストが低い場合、認識アルゴリズムのタスクが複雑になります。
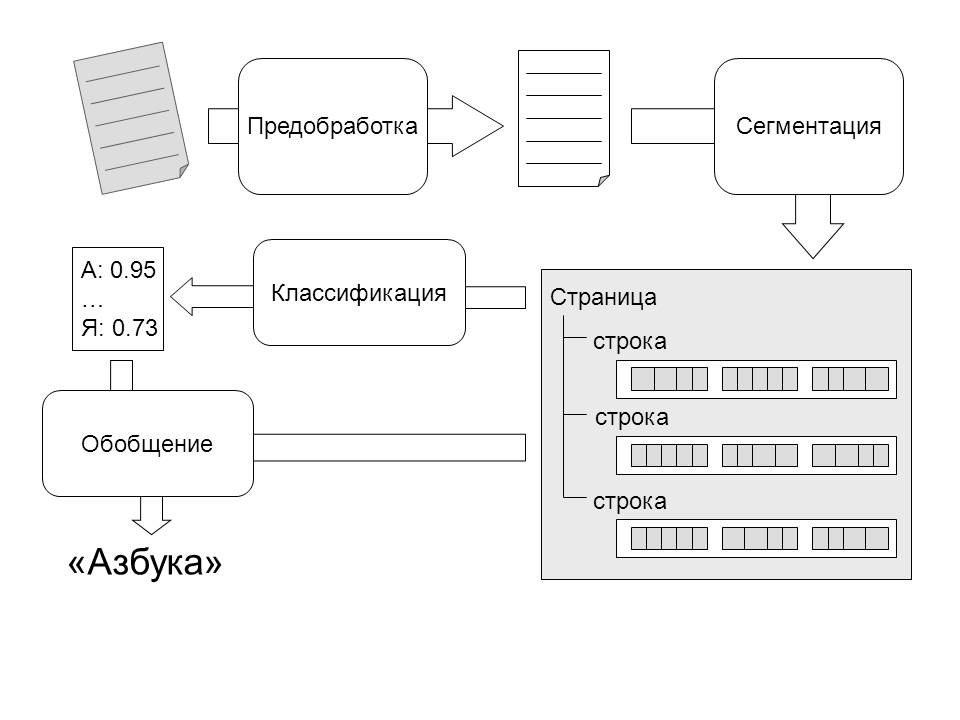
したがって、認識アルゴリズムによる画像処理の前に、画像品質を改善するために前処理されます。 これには、ノイズからの画像のフィルタリング、画像のシャープ化とコントラスト調整、システムで使用されるフォーマットへの変換(この場合、グレースケールの8ビット画像)が含まれます。
準備されたイメージは、セグメンテーションモジュールの入力に送られます。 このモジュールの目的は、テキストの構造単位(行、単語、および文字)を識別することです。 暗い領域間のギャップの分析に基づいて、線や単語などの高レベルの断片を強調表示できます。
残念ながら、このアプローチは個々の文字を強調するために適用することはできません。なぜなら、スタイルや歪みの特性により、隣接する文字の画像を1つの連結コンポーネントに結合できる(図1)またはその逆-1つの文字の画像を別々の連結コンポーネントに分割できる(図2)。 多くの場合、文字レベルのセグメンテーション問題を解決するために、複雑なヒューリスティックアルゴリズムが使用されます。

図1.複数の文字を1つの接続コンポーネントに結合します。

図2.スキャン品質が低いため、文字画像が関連のないコンポーネントに崩壊する。
このような処理の初期段階で文字の境界線を通過する最終決定を下すには、認識システムに十分な情報がないと考えています。 したがって、開発されたアルゴリズムの文字レベルでのセグメンテーションモジュールのタスクは、文字内の文字の可能な境界を見つけることであり、単語分割の最終決定は、個々の画像フラグメントの文字としての識別を考慮して、処理の最終段階で行われます。 このアプローチのもう1つの利点は、このようなケースを特別に処理することなく、いくつかの接続されたコンポーネントで構成されるレタースタイルを操作できることです。
セグメンテーションモジュールの結果はセグメンテーションツリー-組織がページ上のテキストの構造を反映するデータ構造です。 最上位はページオブジェクトに対応します。 文字列を記述するオブジェクトの配列が含まれています。 各行には、一連の単語オブジェクトが含まれます。 言葉はこの木の葉です。 単語を文字に分割するための可能な場所に関する情報は単語に保存されますが、文字の個別のオブジェクトは割り当てられません。 各ツリーオブジェクトには、画像内の対応するオブジェクトが占める領域に関する情報が格納されます。 この構造は、列、テーブルなど、他のレベルのパーティションをサポートするために簡単に拡張できます。
画像の識別された断片は分類器の入力に送られ、その出力は特定の文字のクラスに属する画像の可能性のベクトルです。 開発されたアルゴリズムは、ツリーの形に編成された複合アーキテクチャの分類器を使用します。ツリーのリーフは単純な分類器であり、内部ノードは下位レベルの結果を結合する操作に対応します(図3)。

図3.分類子のアーキテクチャ。
単純な分類器の作業は2つのステップで実行されます(図4)。 最初に、元の画像からサインが計算されます。 各特徴の値は、画像ピクセルのサブセットの明るさの関数です。 その結果、特徴値のベクトルが取得され、ニューラルネットワークの入力に供給されます。 各ネットワーク出力は、アルファベットの文字の1つに対応し、出力で取得された値は、ファジーセットへの文字の帰属レベルと見なされます。

図4.単純な分類子。
組み合わせアルゴリズムのタスクは、入力ファジーセットの形式で受信した情報を一般化し、それに基づいて認識可能な文字セットの出力ファジーサブセットを計算することです。 組み合わせアルゴリズムとして、ファジーセットの理論(tノルムやsノルムなど)の操作が使用されます。これは、最も自信のある専門家が選択したものです。
分類器の結果は、最高レベルで結合することにより得られるファジーセットです。
最後の段階で、最も妥当な単語の読み方を決定します。 これには、個々の文字を読む能力のレベル、文字間のセグメンテーション、およびロシア語での文字の組み合わせの頻度が使用されます。
開発したアルゴリズムの有効性を評価するために、2つの既存のOCRシステムと比較しました。 これは、無料のオープンソースシステムCuneiForm v12および商用システムABBYY FineReader 10 Professional Editionです。
残念ながら、認識システムの有効性を評価するために、通常は外国の専門家によって作成された文字セット、または著者によって収集されパブリックドメインに公開されていない文字セットを使用しました。 たとえば、ABBYY FineReaderアルゴリズムの効率を評価するとき、著者はデータベースCEDAR、NIST、CENPARMI、およびスキャンされたUSEプロファイルを使用しました。 これらのデータベースには英語や手書き文字が含まれているため、「印刷されたキリル文字を認識するアルゴリズムの開発」というトピックに関する研究の有効性を評価するために使用することはできません。
96 dpiと180 dpiの解像度のサンプルで比較が行われました。 Arial 14ptおよびTimes New Roman 14ptフォントの300語で構成されるテキストが比較に参加しました。 96 dpiの解像度のテキストは、グラフィックファイルとしてコンピューター上で直接作成されました。 180 dpiの解像度のテストでは、テキストはレーザープリンターで印刷され、指定された解像度でスキャンされました。 使用されるテキストの一部を図に示します。 5。

図5.認識システムのテストに使用されるテキストの断片。
96 dpiの比較結果を表1に示します。

表1. 96 dpiの解像度でのテキスト認識結果。
180 dpiの解像度のテキストの比較結果を表2に示します。

表2. 180 dpiの解像度でのテキスト認識結果。
96 dpiの最適な認識結果は、現在のシステム構成がTimes New Roman 14ptおよびArial 14ptフォントで96 dpiの解像度でトレーニングされているという事実によって説明できます。 このサイズのフォントをシステムに認識できるように訓練された単純な分類器を追加すると、このテキストの結果が向上することが期待できます。
合計で、1200ワードのうち、認識されました:
•アルゴリズムの開発:1180ワード(98.33%)。
•CuneiFormオープンソースシステム:597ワード(49.75%)。
•ABBYY FineReader商用システム:1200ワード(100%)。
提案されたアルゴリズムはこの品質でテキストを認識しますが、低解像度、大量のノイズが存在する場合、Cuneiformはテキスト認識に対応しません。
一般に、提案されたアルゴリズムはAbbyyのクラス最高の市販製品よりも劣っていますが、CuneiFormオープンソースシステムが認識できるよりも劣ったテキストを認識できると結論付けることができます。
使用された文献のリスト。
Kvasnikov V.P.、Dzyubanenko A.V. 要素ごとの変換によるデジタル画像の視覚的品質の向上// Aerospace Engineering and Technology 2009、8、pp。200-204
Arlazarov V.L.、Kuratov P.A.、Slavin O.A. 印刷されたテキストの行の認識//土。 ISA RAS「文書を操作する方法と手段」の議事録。 -M。:編集URSS、2000 .-- S. 31-51。
SPbUプロジェクトオープンソース:テキスト画像認識[電子リソース]-アクセスモード: ocr.apmath.spbu.ru
Bagrova I.A.、Gritsay A.A.、Sorokin S.V.、Ponomarev S.A.、Sytnik D.A.印刷されたキリル文字を認識するための記号の選択// Bulletin of Tver State University 2010、28、p。 59-73
言語変数の概念と近似推論への応用、情報科学、8、199-249; 9、43-80。
Melin P.、Urias J.、Solano D.、Soto M.、Lopez M.、Castillo O.、ニューラルネットワークによる音声認識、タイプ2ファジーロジックおよび遺伝的アルゴリズム。 エンジニアリングレター、13:2、2006。
Panfilov S. A.ソフトコンピューティングに基づく非線形動的システムの制御アルゴリズムをモデリングするための方法とソフトウェアパッケージ。 技術科学の候補者の学位のための論文。 Tver、2005年。