これは何ですか
ロードされたツリーは、連想配列インターフェースを実装するデータ構造です。つまり、キーと値のペアを保存できます。 ほとんどの場合、文字列はキーとして機能しますが、バイトシーケンスとして表現できるデータ型(つまり、any)はキーとして使用できることに注意してください。
どのように機能しますか?
ロードされたツリーは、ノードにキーが保存されていないという点で通常のn項ツリーと異なります。 代わりに、1文字のラベルがノードに保存され、特定のノードに対応するキーは、ツリーのルートからこのノードへのパス、またはこのパスで検出されたノードのラベルで構成される文字列です。 この場合、ツリーのルートは明らかに空白キーに対応します。
図では、キーc、cap、car、cdr、go、if、is、itを含むロードされたツリーの例を見ることができます。
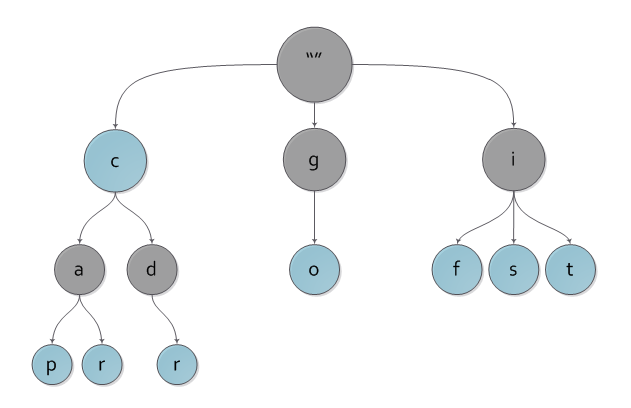
車のキーが強調表示された同じツリー。
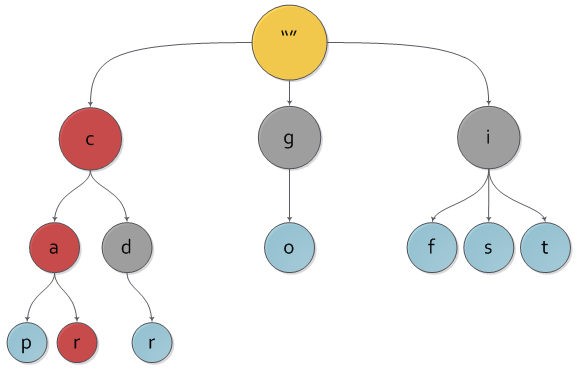
ツリー内のノードにはルートから一意のパスがあり、そのため何らかのキーがあるため、ツリーに「追加の」キーが含まれていることはすぐにわかります。 「余分な」キーの問題を回避するために、ブール特性がツリーの各ノードに追加され、ノードが実際に存在するか、他のノードへの道路に沿って中間であるかを示します。
基本操作
ロードされたツリーは連想配列のインターフェースを実装しているため、キーの挿入、削除、検索という3つの主要な操作を区別できます。 多くのツリーと同様に、ロードされたツリーには自己相似性のプロパティがあります。つまり、そのサブツリーのいずれもフルロードされたツリーです。 そのようなサブツリー内のすべてのキーには共通のプレフィックスがあることは簡単にわかります(「プレフィックスツリー」という名前の由来です)。これは、このツリーの特定の操作を区別できることを意味します-時間O(|プレフィックス|)
キー検索
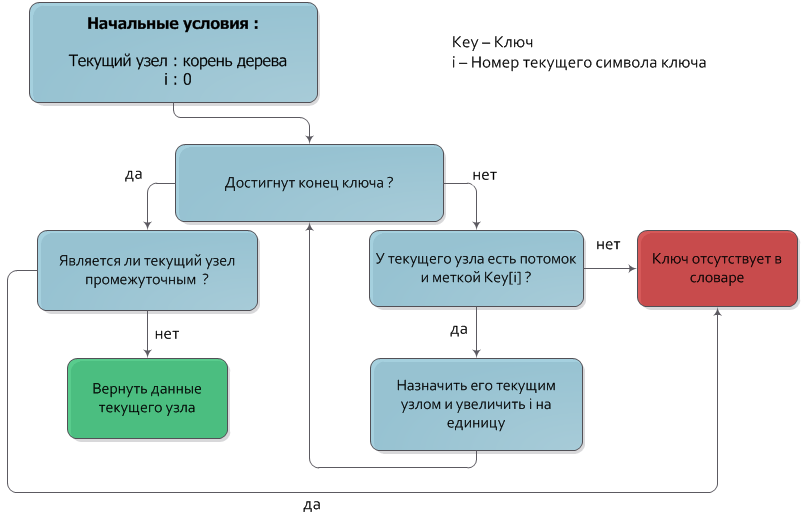
既に述べたように、ノードに対応するキーは、ルートからこのノードへのパスに含まれるノードのラベルの連結です。 このプロパティは、当然ながらキー検索アルゴリズムを意味します(ちなみに、アルゴリズムの追加と削除)。
キーを指定します。キーは、ツリーで見つける必要があります。 ラベルが次のキーシンボルと一致するノードに移動するたびに、ツリーのルートから下位レベルに移動します。 すべてのキーシンボルが処理された後、降下が停止したノードが目的のノードになります。 降下中にキーの次の文字に対応するラベルを持つノードがなかった場合、または降下が中間の頂点(重要ではない頂点)で停止した場合、目的のキーはツリーにありません。
このアルゴリズムの時間の複雑さは明らかにO(| Key |)です。
このアルゴリズムは、ブロック線図でより詳細に示されています。
挿入
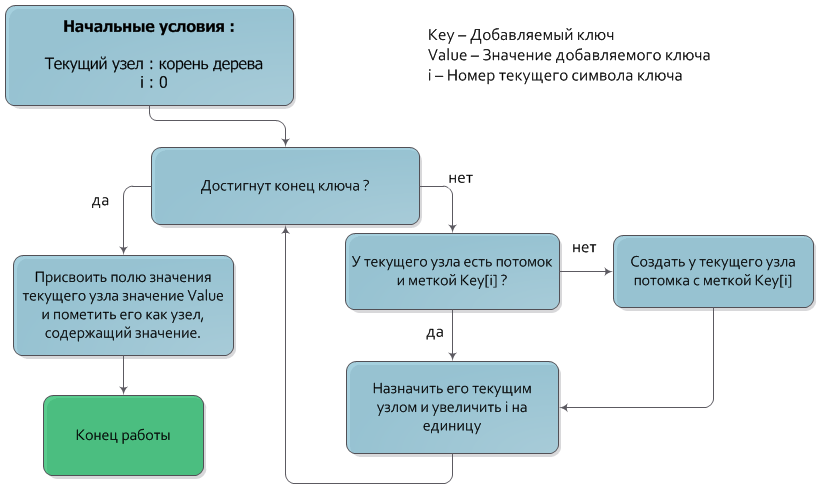
ツリーにキーを追加するアルゴリズムは、検索アルゴリズムに非常に似ています。
追加するキーと値のペアが与えられたとします。 キー検索アルゴリズムの場合と同様に、ツリーのルートから下位レベルに移動し、そのたびにラベルがキーの次の文字に一致するノードに移動します。 キーのすべてのシンボルが処理された後、下降が停止したノードは、値が割り当てられるノードになります(もちろん、ノードは値を持つものとしてマークされる必要があります)。 降下中にキーの次の文字に対応するラベルを持つノードがない場合、目的のラベルを持つ新しい中間ノードを作成し、現在のノードの子孫として指定する必要があります。
キーを追加する時間の複雑さはO(|キー|)です。
フローチャートのアルゴリズム図:
削除する
キーの削除も非常に簡単です。
ツリーから削除する必要があるキーを指定します。 このキーを検索します。 キーがディクショナリに存在する場合、そのキーが対応するノードを知っているので、単に中間キーとしてマークし、以降の検索で「非表示」にすることができます。
その後、「切断された」ノードからルートに上昇し、リーフであるすべてのノードを同時に削除できますが、この場合のメモリ節約は重要ではありません。ノードがリーフであるかどうかを効果的に判断するには、追加のノード特性を導入する必要があります。
削除アルゴリズムの一時的な評価はすでにO(| Key |)に慣れています。
リソース要件
メモリ/ CPU時間消費の観点から読み込まれたツリーは、ハッシュテーブルとバランスツリーよりも劣らず、これらのパラメーターでそれらを上回ることがあります。
CPU時間
挿入、削除、および検索操作の複雑さはO(|キー|)です。 バランスの取れたツリーはこれらの操作をO(ln(n))で実行しますが、漸近的な動作により、キーを比較するのに必要な時間が隠されます。 ハッシュテーブルの場合、状況は似ています-アクセス時間がO(1 + a)であっても、ハッシュを取得するにはO(| Key |)が必要です(もちろん、事前に計算されていない場合)。
ロードされたツリー、ハッシュテーブル、赤黒ツリーのパフォーマンスを比較したチャートは、 英語版ウィキペディアで見ることができます。
記憶
メモリの消費において、ロードされたツリーは、多くの場合、ハッシュテーブルとバランスツリーよりも優れています。 これは、ロードされたツリーの多くのキーに同じプレフィックスがあり、それらのキーが使用するメモリがあるためです。 また、平衡型ツリーとは異なり、ロードされたツリーでは、各ノードにキーを保存する必要はありません。
最適化
ロードされたツリーの最適化には、主に2つのタイプがあります。
- 圧縮 圧縮されたロードされたツリーは、単一の非中間ノードにつながる中間ノードを削除することにより、通常のものから取得されます。 たとえば、a、b、cとラベル付けされた中間ノードのチェーンは、 abcとラベル付けされた1つのノードに置き換えられます。
- パトリシア 。 パトリシアを含むツリーは、1つの子を持つ中間ノードを削除することにより、圧縮された(または通常の)ツリーから取得されます。
なぜこれがすべて必要なのですか?
実際には、ロードされたツリーのスコープは非常に大きく、連想配列インターフェースの実装が必要な場所であればどこでも使用できます。 特にロードされたツリーは、辞書、スペルチェッカー、およびその他のT9を実装するのに便利です。つまり、特定のプレフィックスを持つキーのセットをすばやく取得する必要があるタスクで便利です。 また、ロードされたツリーは、その作業でよく知られているAho-Korasikアルゴリズムを使用します。
それだけです。 読者がこの素晴らしいデータ構造について知りたいと思ったことを願っています。このデータ構造は、Habréで言及されることはめったにありません。