情報をコーディングしたことがない人のために、特別な数式を使わずに、できるだけ簡単にすべてを記述しようとしました。
送信元から受信者にメッセージを送信すると、データ転送中にエラーが発生する場合があります(干渉、機器の誤作動など)。 エラーを検出して修正するには、エラー修正コーディングを使用します。 エラーが発生したかどうかを受信側が認識し、発生した場合はエラーを修正できるようにメッセージをエンコードします。
実際、コーディングは、追加の検証情報の初期情報への追加です。 エンコードの場合、送信側でエンコーダーが使用され、受信側でデコーダーが使用されて元のメッセージが受信されます。
コードの冗長性は、メッセージ内の検証情報の量です。 次の式で計算されます。
k /(i + k) 、ここでたとえば、3ビットを転送し、1チェックビットを追加します-冗長性は1 /(3 + 1)= 1/4(25%)になります。
kはチェックビットの数、
iは情報ビットの数です。
パリティコード
パリティは、送信されたデータパケットのエラーを検出するための非常に簡単な方法です。 このコードでは、データを回復できませんが、単一のエラーのみを検出できます。
各データパケットには1つのパリティビット 、またはいわゆるパリティビットがあります。 このビットは、データの書き込み(または送信)時に設定され、データの読み取り(受信)時に計算および比較されます。 これは 、パケット内のすべてのデータビットのモジュロ2の合計に等しくなります。 つまり、パッケージ内のユニット数は常に偶数になります。 このビットを変更すると(0から1など)、エラーが報告されます。
以下は、このコードのエンコーダーのブロック図です
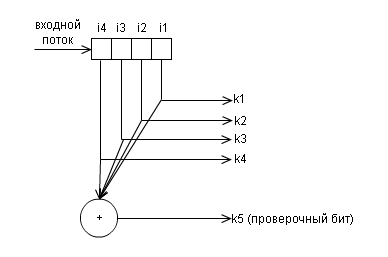
およびデコーダー
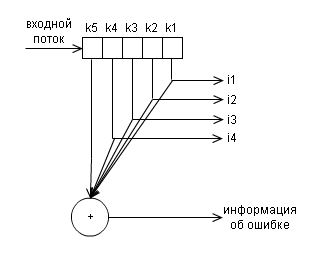
例:
初期データ:1111
エンコード後のデータ:1111 0 (1 + 1 + 1 + 1 = 0(mod 2))
受信データ:1 0 110(2番目のビットが変更されました)
ご覧のように、受信パケットのユニット数は奇数であるため、送信中にエラーが発生しました。
前述のように、このメソッドは単一のエラーを特定するためだけに役立ちます。 2ビットの状態が変化した場合、制御ビットの計算が記録されたビットと一致する可能性があります。 この場合、システムはエラーを検出せず、これは良くありません。 例:
初期データ:1111
エンコード後のデータ:1111 0 (1 + 1 + 1 + 1 = 0(mod 2))
受信データ:1 00 10(2および3ビットが変更されました)
受信データでは、ユニット数は偶数であるため、デコーダーはエラーを検出しません。
すべての不規則なエラーの約90%は1ビットで発生するため、ほとんどの状況ではパリティで十分です。
ハミングコード
前の部分で述べたように、 Richard Hammingはノイズに強いコーディングに多くのことをしました。 特に、彼は最小限の追加チェックビットで単一エラーの検出と修正を提供するコードを開発しました。 テスト文字の数ごとに、フォーム(k、i)の特別なマーキングが使用されます。ここで、kはメッセージ内の文字数、iはメッセージ内の情報文字の数です。 たとえば、コード(7、4)、(15、11)、(31、26)があります。 ハミングコードの各チェック文字は、データサブシーケンスのモジュロ2の合計を表します。 ブロックの情報ビットiの数が4である場合の例を見てみましょう。これはコード(7.4)で、チェック文字の数は3です。古典的に、これらの文字は昇順で2のべき乗に等しい位置にあります。
2 0 = 1の最初のチェックビット。
2 1 = 2の2番目のチェックビット。
2 2 = 4の3番目のチェックビット。
ただし、送信されたデータブロックの最後に配置することはできます(ただし、計算式は異なります)。
次に、これらのテスト文字を計算します。
r1 = i1 + i2 + i4
r2 = i1 + i3 + i4
r3 = i2 + i3 + i4
したがって、エンコードされたメッセージでは、次のものが得られます。
r1 r2 i1 r3 i2 i3 i4
原則として、このアルゴリズムの動作は、 ハミングコードの記事で詳細に分析されています。 アルゴリズムの操作の例なので、この記事で詳しく説明することには意味がありません。 代わりに、エンコーダーのブロック図を提供します。
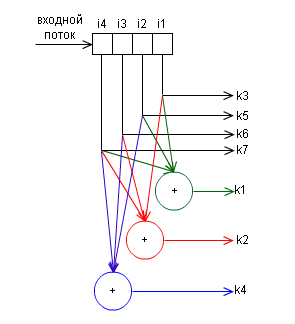
およびデコーダー
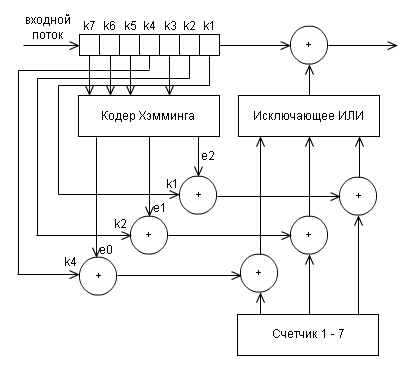
(多分非常に混乱しますが、うまく機能しませんでした)
e0、e1、e2は、デコーダーが受信したビットk1〜k7に応じた関数として定義されます。
e0 = k1 + k3 + k5 + k7 mod 2
e1 = k2 + k3 + k6 + k7 mod 2
e2 = k4 + k5 + k6 + k7 mod 2
これらの値のセットe2e1e0は、データ転送中にエラーが発生した位置のバイナリレコードです。 デコーダはこれらの値を計算し、それらがすべて0に等しくない場合(つまり、000がうまくいかない場合)、エラーは修正されます。
製品コード
通信チャネルでは、ノイズに起因する単一のエラーに加えて、インパルスノイズ、フェージング、または損失(デジタルビデオ録画)が原因でパケットエラーが発生することがよくあります。 同時に、数百、または数千の情報が連続して影響を受けます。 エラー修正コードがそのようなエラーに対処できないことは明らかです。 このようなエラーに対処するために、製品コードが使用されます。 このようなコードの動作原理を図に示します:

送信された情報は、外部および内部エンコーダーで2回エンコードされます。 バッファがそれらの間にインストールされ、その動作が図に示されています:
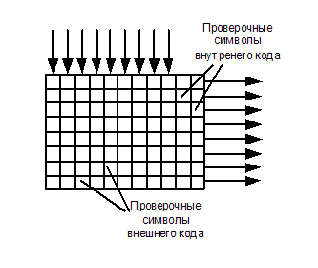
情報ワードは、外部と呼ばれる最初のエラー訂正エンコーダーを通過します。 彼と対応するデコーダは、エラー訂正コーディングシステムの端にあります。 ここでは、テスト文字が追加され、順番に列にバッファリングされ、行ごとに表示されます。 このプロセスは、 ミキシングまたはインターリーブと呼ばれます。
バッファから文字列が出力されると、内部コードのチェック文字が追加されます。 この順序で、情報は通信チャネルを介して送信されるか、どこかに記録されます。 内部コードと外部コードの両方が3つのチェック文字を持つハミングコードであることに同意しましょう。つまり、両方ともコードワードの1つのエラーで修正できます(図の「キューブ」の数は重要ではありません-これは単なる図です)。 受信側にはまったく同じメモリアレイ(バッファ)があり、そこに情報が1行ずつ入力され、列に表示されます。 パケットエラーが発生すると(図の3行目と4行目の交差)、外部コードのコードワードの小さな部分に分散され、修正できます。
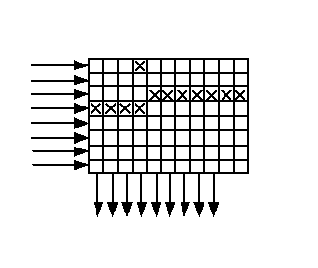
外部コードの目的は明確です-パケットエラーの修正。 なぜ内部コードが必要なのですか? 図では、バッチに加えて、単一のエラーが示されています(4番目の列、一番上の行)。 4列目にあるコードワードには2つのエラーが含まれていますが、修正することはできません。 外部コードは、1つのエラーを修正するように設計されています。 この状況から抜け出すには、この単一のエラーを修正する内部コードが必要です。 受信したデータは最初に内部デコーダーを通過し、そこで単一のエラーが修正されます。次に、行ごとにバッファーに書き込まれ、列に表示され、パケットエラーが修正される外部デコーダーに送られます。
製品コードを繰り返し使用すると、わずかな冗長性が追加され、エラー修正コードの能力が繰り返し向上します。
PS:卒業プロジェクトを書いていた3年前に、このトピックに密接に対処しました。 すべての修正、コメント、提案-プライベートメッセージでお願いします