構造化ストレージ方式は、これらすべての問題を処理します。 1980年代に登場しましたが、最近、データベースエンジンのストレージを構造化する方法としてこのメソッドの使用が増加していることがわかります。 ファイルシステムの最初の使用では、広範な配布を妨げるいくつかの欠陥がありますが、これから見るように、それらはDBMSにとってそれほど重要ではなく、構造化されたストレージログはデータベースに追加の利点をもたらします。
名前が示すように、構造化データストレージログシステムを編成する基盤はログです。つまり、すべてが順次データ記録によって行われます。 書き込む新しいデータがある場合は、ディスク上のデータの場所を見つけるのではなく、ログの最後に追加するだけです。 メタデータを処理することにより、データにインデックスが付けられます。メタデータの更新もジャーナルで発生します。 これは非効率に思えるかもしれませんが、インデックス構造はBツリーであり、原則として非常に幅が広いため、各レコードでインデックスノードの数を更新する必要があります。 簡単な例を見てみましょう。 データ項目を1つだけ含むログと、それを参照するノードのインデックスから始めます。
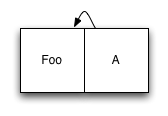
これまでのところ良い。 次に、2番目の要素を追加するとします。 ログの最後に新しいアイテムを追加し、ポインターの更新バージョンを追加します。
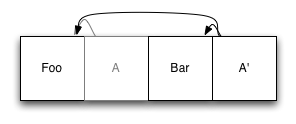
インデックス(A)を持つ元のエントリはまだファイル内にありますが、使用されなくなりました。Fooの元のコピーと新しいエントリバーを参照する新しいエントリA 'に置き換えられました。 ファイルシステムから読み取りたい場合、ルートノードのインデックスを見つけ、他のシステムと同じように使用します。
クイックルートインデックス検索。 単純なアプローチでは、ログの最後のブロックを見ることができます。これは、最後に記述するものが常にルートインデックスであるためです。 ただし、これは理想的ではありません。インデックスの読み取り時に、別のプロセスがログの中央を追加する可能性があるためです。 これを回避するには、現在のルートノードへのポインターを含む単一のブロック(ログの先頭など)を使用します。 ログを更新するたびに、最初のレコードを書き換えて、新しいルートノードを指すようにします。
次に、アイテムを更新するとどうなるかを見てみましょう。 Fooを変更したとしましょう:

雑誌の最後に、Fooの新しいコピーの録音を開始しました。 次に、ノードインデックスを再度更新し(この例のみ)、ログの最後に書き込みました。 繰り返しますが、Fooの古いコピーはログに残りますが、更新されたインデックスは単にそれを参照しなくなります。
このシステムは無期限に安定していないことをご存知でしょう。 ある時点で、古いデータがスペースを占有します。 ファイルシステムでは、これは古いデータを上書きするリングバッファと見なされます。 これが発生すると、有効なままのデータは単にログに追加されます。あたかもそれらが書き込まれたかのように、必要な古いコピーは上書きされません。
ファイルシステムでは、前述の欠点の1つはログヘッダーの適切なブロックではありません。 ディスクから完全な情報を取得すると、ファイルシステムはガベージコレクションに時間を費やし、ログヘッダーにデータを常に書き込む必要があります。 そして、80%に達すると、ファイルシステムは実質的に停止します。
データベースに構造化ストレージログを使用する場合、それは問題ではありません! データベースを固定長の複数のピースに分割した場合、スペースを返す必要がある場合、ピースを選択し、新しいデータで書き換えて、そのピースを削除できます。 この例の最初のセグメントは、少し自由に見え始めます。
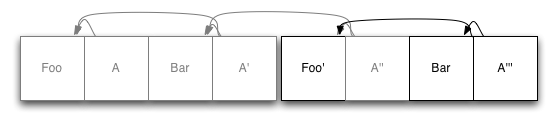
ここで行ったのは、既存のBarのコピーを取得してログの最後に書き込むことです。その後、上記のようにノードのインデックスを更新しました。 これを行った後、ジャーナルの最初のセグメントを安全に削除できます。
このアプローチには、ファイルシステムアプローチに比べていくつかの利点があります。 そもそも、古いセグメントを削除することに限定されず、中間セグメントがほとんど空の場合、単純にガベージを収集できます。 これは、長期間保存されているデータがいくつかあり、どのデータが何度も上書きされる場合に、データベースで特に役立ちます。 変更されていないデータの書き換えにあまり時間をかけたくありません。 また、ごみの収集に大きな柔軟性があります。
データベースに対するこのアプローチの利点はそれだけではありません。 トランザクションの一貫性を確保するために、データベースは通常、先行書き込みログ(WAL)を使用します。 データベースがディスクに保存されると、最初にすべての変更がWALに書き込まれ、次にディスクに書き込まれ、次に既存のデータベースファイルが更新されます。 これにより、事故後にWALに記録された変更を復元できます。 WALデータベースである構造化ストレージログを使用する場合、データを1回書き込むだけです。 復元するときは、最後に記録されたインデックスから始めてデータベースを開き、不足しているインデックスを検索します。
上記のリカバリスキームを使用して、記録の最適化を継続できます。 各レコードのインデックスノードの更新を書き込む代わりに、それらをメモリにキャッシュし、ディスクに定期的にのみ書き込むことができます。 リカバリエンジンは、通常のエントリと不完全なエントリを区別することを提案するまで、リカバリを処理します。
また、ジャーナルの新しいセグメントごとにデータベースをバックアップメディアに徐々にコピーすることもできます。
最後このシステムの主な利点は、データベース内のトランザクションの並列性とセマンティクスに関連しています。 トランザクションの一貫性を確保するために、ほとんどのデータベースは洗練されたロックシステムを使用して、どのプロセスがいつデータを更新できるかを制御します。 必要な一貫性のレベルに応じて、キーを取り出して読み取り時にデータが変わらないことを確認し、書き込み用のデータキーを書き込むことにより、読者を引き付けることができます。同時読み取り。
データの記録に関しては、 Optimistic Concurrencyを使用できます。 通常の読み取り-変更-書き込みサイクルでは、最初に上記の読み取り操作を実行します。 次に、変更を記録するために、データベースのレコードをロックし、最初のフェーズで読み取ったデータがないことを確認します。 データアドレスが最後に読み取ったときと同じである場合、インデックスを調べることでこれをすばやく行うことができます。 記録されていない場合は、変更を開始できます。 すべてが異なる場合は、戻って再び読み始めます。