Linux用のKBookOCR。 初期段階のLinux用FineReaderキラー
エントリー
おそらく、私たち一人一人は、物質のアナログの積極的なデジタル化を伴う人生のある期間を経験したのでしょう。 私は、非デジタルソースからのテキストを扱う必要があることを意味します。 これは、スキャンの問題だけでなく、残念ながら最終消費者に届く多くの資料がまったく使用可能な形式ではありません。 そして、私たち一人一人は、私たちの活動に資料を使用することなく、すべてのコンテンツがグラフィカルに提示されたdjvuまたはpdf形式の本の販売業者について、お世辞を思い浮かべることが非常に多いと思います。
Windowsユーザーの場合、FineReaderを使用するオプションがあります。これにより、すべての結果を伴う認識プロセスを簡単に実行できます。
Linux-問題の解決策
しかし、財務を許容可能なレベルに維持しながら、より高度なオペレーティングシステムを使用できる人はどうでしょうか。 もちろん、テキストを認識するためのコンソールユーティリティのプロジェクトがあります。 最も開発されたオープンテクノロジーの1つに基づいて、OCRは、同じサーバーと通信するためのWebインターフェイスを備えたOCR用サーバーを展開するための配布キット全体を作成しました。 しかし、私は最終消費者がそのような恐ろしい決定に興味があるとは思わない。 そして、テクノロジー自体は多くのディストリビューションで、一般的な形式では動作しないコンソールアプリケーションの形式で実装されています。そのほとんどの場合、テキスト(djvu、pdf)を「切り取る」必要がありますが、グラフィックファイルを使用すると、使用プロセスが複雑になります。
もちろん、この状況とLinuxはあらゆるものを最適化することを好むため、BookOCRプロジェクトの登場に至りました。その創設者は、まだHabréに所属していない素晴らしい人mr-protosです。 さらに、BookOCRの作成に関する彼の記事:
BookOCR
mr-protosは、適度に単純なbashスクリプトbookocr.shを作成しました。
bookocr.tar.xz ( dropboxでホスト)
彼の仕事のアルゴリズム:
1.ファイル拡張子(.djvuまたは.pdfを確認します。別の拡張子の場合、スクリプトは警告を出します);
2.さらに認識できるように、ファイルを.pngにページごとに変換します。 (結果は一時フォルダー〜/ .tmp_pdfまたは〜/ .tmp_djvuに追加されます);
3. OCRを使用した変換済みページの認識。
4.ページ分割されたテキストファイルを1つに結合します。
5.一時フォルダーを削除します。
スクリプトの使用:
bookocr.sh <path_to_pdf_or_djvu>
注:完成したファイルは、ソースと同じディレクトリに作成されます
システムでスクリプトを機能させるには、次のパッケージをインストールする必要があります。
- くさび形
- ゴーストスクリプト
- djvulibre-bin
- libtiff-tools
- libnotify-bin
認識されるテキストの品質は、主に元のファイルの品質とcuneiformパッケージの動作に依存します。
KBookOCR
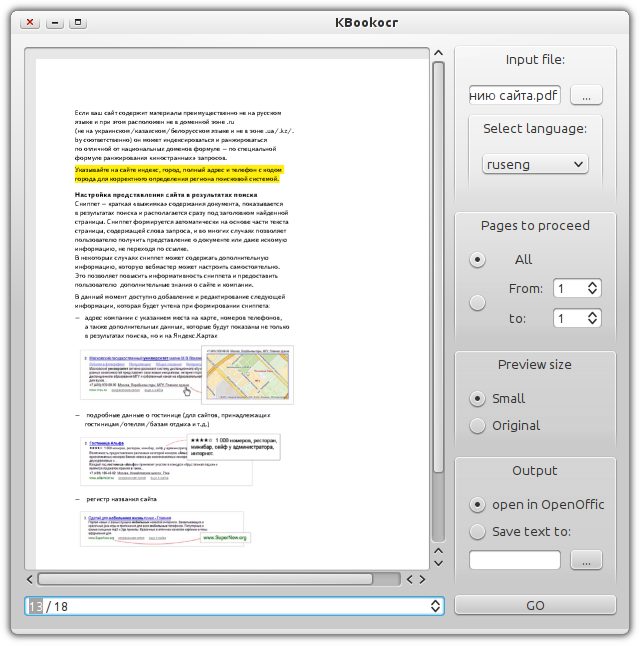
もちろん、このプロジェクトはもう1つの野心的なアイデアの推進力であり、BookOCRの著者とともに、謙虚な僕b0noIによって命を吹き込まれました 。 アイデアは、視覚的に美しいデザイン(少なくともこれが望ましい)を好む視覚美人による使用に適したシステムを実装し、FineReaderを同様に便利で審美的に美しい方法で実行できるLinuxベースのプロジェクトを最大限に作成することでした。
開発のために、Qtライブラリが選択されました。 一方で、このプロジェクトはBookOCRプロジェクトのアドオンですが、それほど単純ではありません。 統合では元のスクリプトに大幅な変更を加える必要があったためです。 djvuファイルのプレビューを実装する際に特別な問題がありました。これは、pdf用のpopplerプロジェクトが存在する場合、指定された場合にはプレビューをサードパーティのbashユーティリティで実装する必要があるためです。 そのため、KbookOCRをKbookOCR自体とともにインストールすると、BookOCRだけでなく、プレビューで使用される画像を取得するために使用されるコンソールユーティリティもインストールされます。
プロジェクトの現状
すでに、プロジェクトは完成した最初のバージョンの段階に到達しており、積極的な公開テストを受けています( Ubuntu deb x86のダウンロード)。 FineReaderの最初の公開およびオープンソースキラーは何ができますか?:
- 認識される必要があるドキュメントをプレビューします(ページをスクロールします)。
- 認識言語を指定します。 現在、ドキュメントには言語認識はありませんが、そうする予定です。 また、デュアルドキュメント認識言語を指定する方法もありません(rus / engを除く)。
- プレビューのサイズを変更します。 2つのオプションが利用可能です-元のサイズまたは縮小。
- 特定の範囲またはドキュメント全体で認識できます。
- 認識されたドキュメントを保存します。 2つのオプションが利用可能です-結果を通常のテキストファイルに保存するか、OpenOffice Writerで結果を開きます。
ロードマップ
残念ながら、リリース日が不明な次のバージョンでは、以下を実装および追加する予定です。
- スキャナーでの作業;
- ドキュメントの言語を自動検出します。
- より柔軟なプレビュー。 ページのサムネイルの描画、および表示スケールのより柔軟な表示。
- 認識範囲のより柔軟な指示。
非常に遠い将来、認識ゾーン、ゾーンのタイプを指定し、テキストだけでなく、オリジナルに従ってドキュメントをフォーマットするためのオプションも検討されています。
あとがき
KbookOCRはデュエットの最も新しい子孫ですが、このプログラムは私たちにとって最初で唯一の創造物ではありません。 次のシリーズでは、Linux向けの最初の共同プロジェクトであるポッドキャスト用KbashPodについて説明します。
UPD:
バージョン1.2への更新:
- スキャナーのサポート(scanimage経由);
- 結果をhtml、rtf形式で出力します(cuneiform経由)。
- テキスト整形処理(楔形文字経由);
- ダイナミックズームプレビュー。
参照資料
BookOCR
bookocr.tar.xz
KBookOCR 1.2
kde-apps.orgのKBookOCR
著者
mr-protos
b0noI
All Articles