Windowsでの大量のトラフィックフローと割り込み管理
プロセッサでのネットワークアダプタ割り込みからの負荷分散に関するトピックが本当に好きだったので、Windowsでこれを行う方法を説明することにしました。
免責事項:以前の投稿のいくつかのコメントから判断すると、最初の投稿を開始したときと同じように繰り返す必要があります。一般的に適用可能なレシピを提供しません(そして提供できません)。 これは、パフォーマンスに対して特に当てはまります。この場合、最小の不明な詳細が結果に壊滅的な影響を及ぼす可能性があります。 むしろ、テストと分析という推奨事項を示します。 私の著作の意味は、分析のためにできるだけ多くの情報を人々に提供することです。なぜなら、何かがどのように機能するかを理解すればするほど、ボトネクスを排除する方法を見つけやすくなるからです。
したがって、ネットワーク帯域幅のスケーラビリティ。 Windows Server 2003 SP2 +が必要です。 Receive Side Scalingをサポートするネットワークカード(過去5年間に発行されたサーバーネットワークカードまたは一般的には1Gb + NICが適切であると十分に自信を持って言うことができますが、RSSも100Mbで見ることができます)。 カードへのWindows Serverとドライバーのインストール...
すべて。 セットアップが完了しました。 RSSは、サポートされているすべてのバージョンのWindowsでデフォルトで有効になっています。
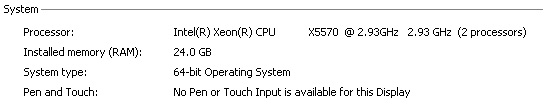
2つのクアッドコアxeonを搭載したそれほど新しくないDellサーバーを使用します。
機内には2つのデュアルポート1Gbネットワークカードと1つの10Gbがありますが、10Gbスイッチが見つからなかったため、入手できませんでした。

これらのマップの興味深い点は、8つのキューでRSSをサポートしているにもかかわらず、 MSI-XもMSIもサポートしていないことです。 さらに、4つの利用可能なピンベースの割り込みラインのうち、各ネットワークポートに割り当てられるのは1つだけです(したがって、異なるプロセッサに割り込みを強制することはできなくなりました-これはこの構成のハードウェア制限です)。 10ギガバイトは32または64(片目)の割り込みベクトルを登録しましたが、それを使用することは運命ではありません。 ゲームを起動するタスクに対処するために、 ヒンズー教のクラフトはできますか?

念のため、RSSを確認してください(存在しない場合でも同様に目立ちます)。

最初に、RSSをオフにします(テスト後に同じウィンドウでオンにしました)

そして、負荷テストを実行します。
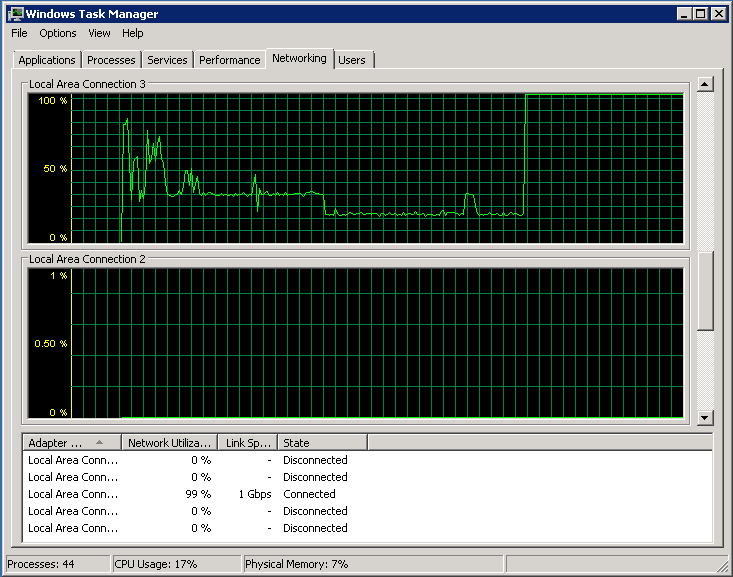
2つのコアが完全にロードされ、残りはすべてアイドル状態です
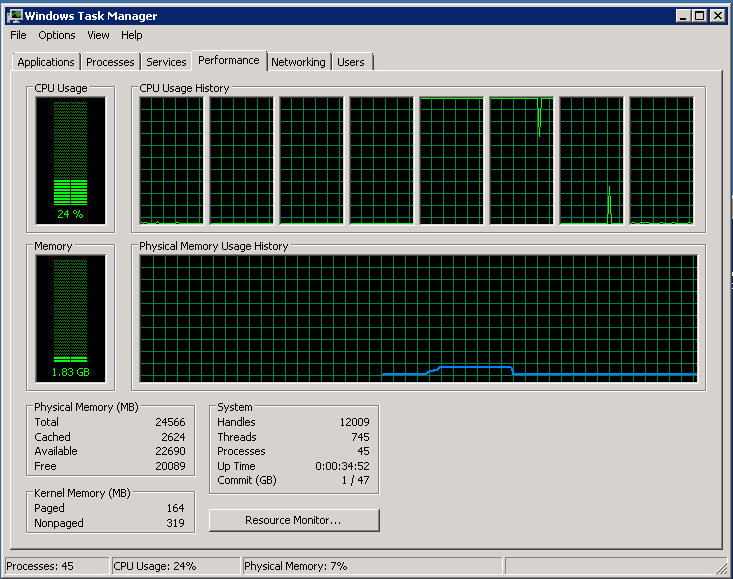
ネットワークは3番目にアップロードされます。
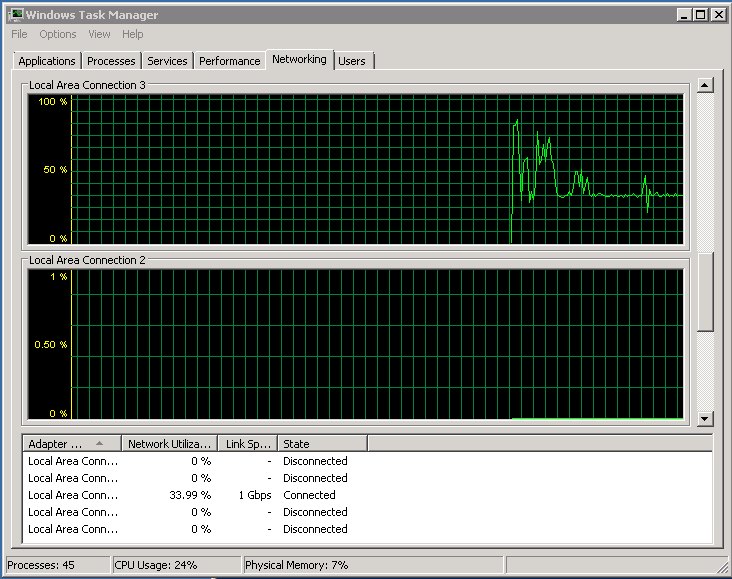
1つのプロセッサの50%が割り込み処理で詰まっており、同じプロセッサの別の20%がDPC処理です。 残りはtcpipスタックとトラフィックを送信するアプリケーションです。
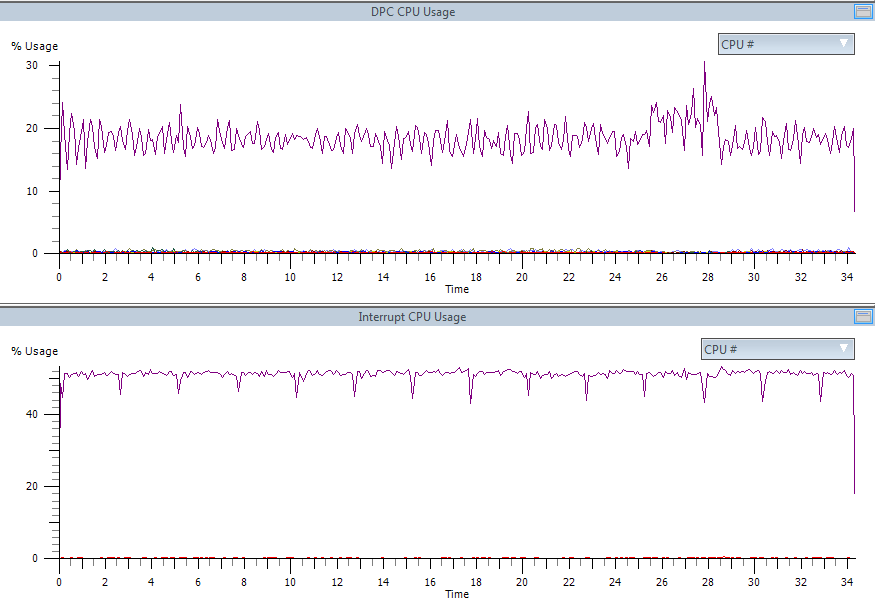
RSSをオンにします(上のスクリーンショット)。 CPU
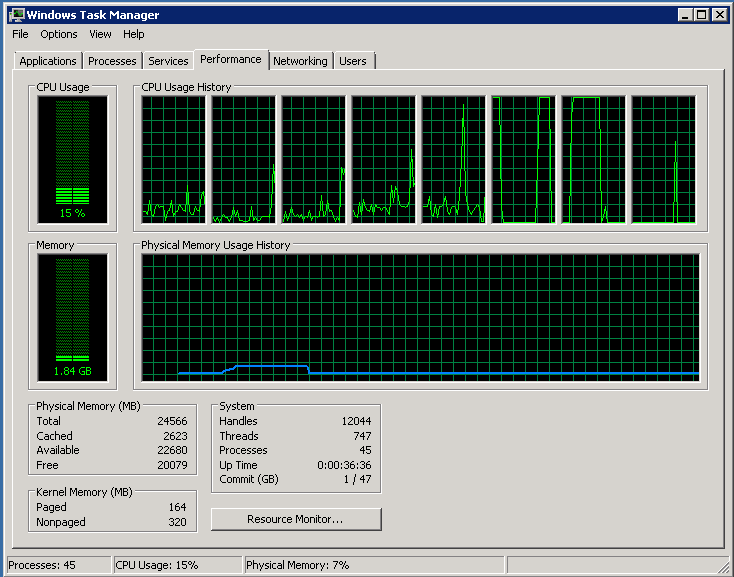
ネットワーク:
1つのプロセッサの3分の1が割り込みで詰まっていますが、DPCは完全に並列化されています。
一般に、この構成では、約3ギガビット(1つのネットワークインターフェイスカードから)を提供することが可能であり、その場合にのみボトルネックが発生します。
念のため、RSSにはあまり知られていませんが、Send Side Scalingがあります。 バッファのリストを送信する前にハッシュ値を設定すると、確立された間接テーブルに従って、送信完了後の割り込みが配信されます。
ここではRSSについて読むことができ、 ここではRSSの機能を説明する写真で優れたプレゼンテーションがあります。 興味深い場合は、RSSの仕組みを自分の言葉で説明することもできますが、私にとっては、ソースを読む方が良いでしょう。
Linux で RSSのようなものが表示されようとしている場合(Linuxで通常のハードウェアRSSをサポートすることについての言及は見つかりませんでした。 Linux上のTOEでは、すべてが公式に複雑です。 TOEサポートを実装するChelsio (ハイエンドネットワークカードのメーカーの1つ)からのパッチは拒否され、代わりに、ある種の完全にばかげた言い訳が始まりました (BSDとWindowsが長年にわたって通常のTOEサポートを持っていることに留意する価値がある) 。
それで何ですか? TOEは、ハードウェアレベルでの完全なTCPIP実装です:配信確認、エラーの再送信、ウィンドウ制御など:DMA経由のネットワークカードは、メモリから直接データを取得し、パケットに切り取り、ヘッダーを添付し、(割り込みを使用して)最も極端な場合。
デフォルトでは、TOEは自動モードです。 チムニーオフロードの状態を見る:
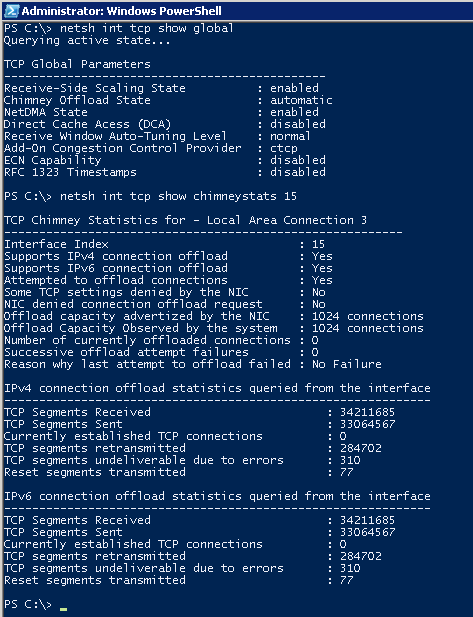
スクリーンショットはアクティブなテスト中に撮影されましたが、統計では、単一の接続がネットワークインターフェイスカードにアップロードされていないことが示されています(理由について)。 強制的に有効にします(そしてしばらくしてから統計情報をリクエストします):
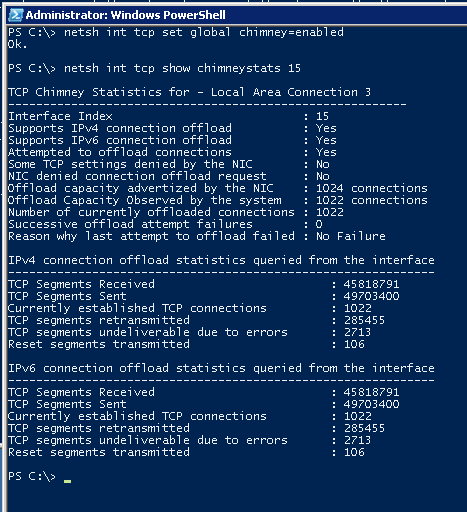
その理由は次のとおりです。このネットワークカードにダウンロードできる接続は1024のみです(実際には、システムは1022をダウンロードできました)。 かなり高価なリソースなので、すべてを連続してアンロードできます。 システムはヒューリスティックに、長時間続く接続の検出(httpを介した大きなファイルの取得/配置、ファイルサーバーへのファイルコンテンツの送信など)を試み、最初にそれらをアンロードします。
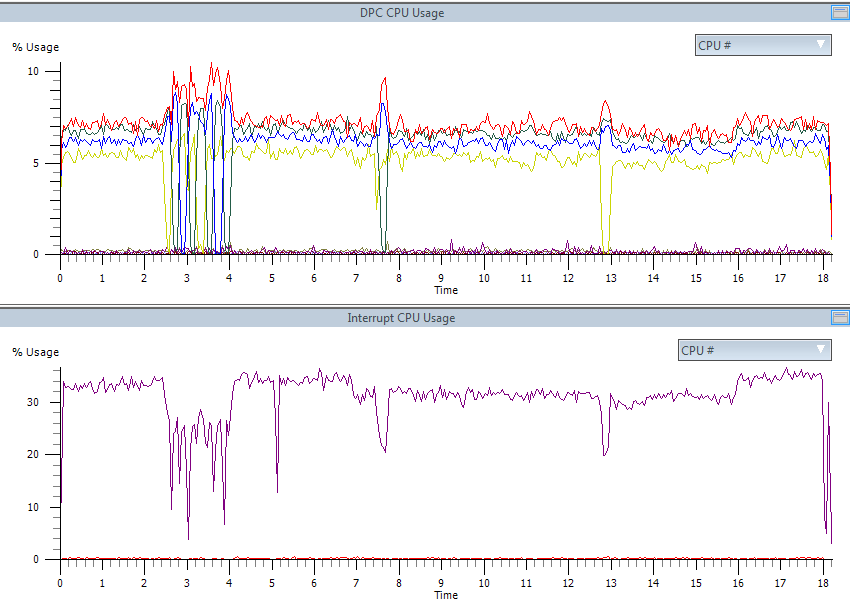
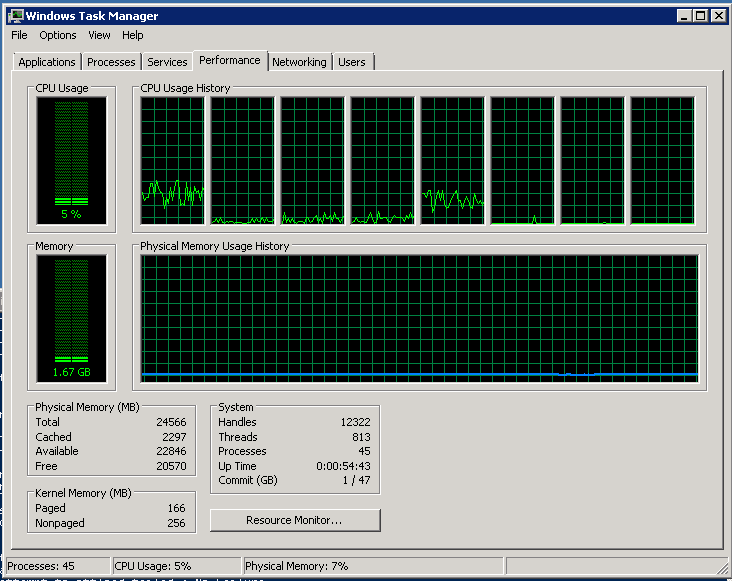
しかし、まだ何が起こったのか見てください。 プロセッサーは3回アンロードされました。
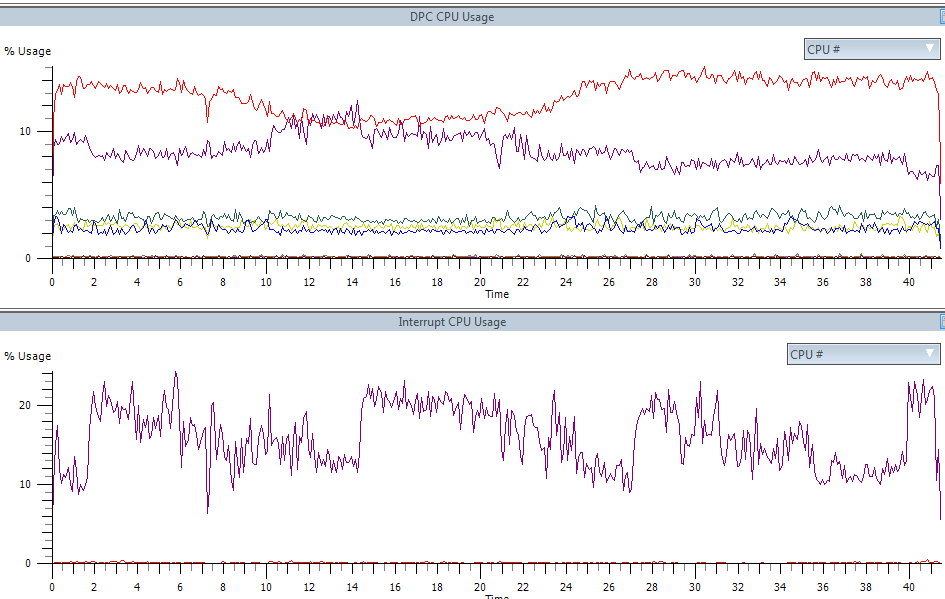
ISRとDPCの両方の数(および費やされた時間)は非常に減少しました。
免責事項:以前の投稿のいくつかのコメントから判断すると、最初の投稿を開始したときと同じように繰り返す必要があります。一般的に適用可能なレシピを提供しません(そして提供できません)。 これは、パフォーマンスに対して特に当てはまります。この場合、最小の不明な詳細が結果に壊滅的な影響を及ぼす可能性があります。 むしろ、テストと分析という推奨事項を示します。 私の著作の意味は、分析のためにできるだけ多くの情報を人々に提供することです。なぜなら、何かがどのように機能するかを理解すればするほど、ボトネクスを排除する方法を見つけやすくなるからです。
したがって、ネットワーク帯域幅のスケーラビリティ。 Windows Server 2003 SP2 +が必要です。 Receive Side Scalingをサポートするネットワークカード(過去5年間に発行されたサーバーネットワークカードまたは一般的には1Gb + NICが適切であると十分に自信を持って言うことができますが、RSSも100Mbで見ることができます)。 カードへのWindows Serverとドライバーのインストール...
すべて。 セットアップが完了しました。 RSSは、サポートされているすべてのバージョンのWindowsでデフォルトで有効になっています。
テスト中
2つのクアッドコアxeonを搭載したそれほど新しくないDellサーバーを使用します。
機内には2つのデュアルポート1Gbネットワークカードと1つの10Gbがありますが、10Gbスイッチが見つからなかったため、入手できませんでした。
これらのマップの興味深い点は、8つのキューでRSSをサポートしているにもかかわらず、 MSI-XもMSIもサポートしていないことです。 さらに、4つの利用可能なピンベースの割り込みラインのうち、各ネットワークポートに割り当てられるのは1つだけです(したがって、異なるプロセッサに割り込みを強制することはできなくなりました-これはこの構成のハードウェア制限です)。 10ギガバイトは32または64(片目)の割り込みベクトルを登録しましたが、それを使用することは運命ではありません。 ゲームを起動するタスクに対処するために、 ヒンズー教のクラフトはできますか?
念のため、RSSを確認してください(存在しない場合でも同様に目立ちます)。
最初に、RSSをオフにします(テスト後に同じウィンドウでオンにしました)
そして、負荷テストを実行します。
2つのコアが完全にロードされ、残りはすべてアイドル状態です
ネットワークは3番目にアップロードされます。
1つのプロセッサの50%が割り込み処理で詰まっており、同じプロセッサの別の20%がDPC処理です。 残りはtcpipスタックとトラフィックを送信するアプリケーションです。
RSSをオンにします(上のスクリーンショット)。 CPU
ネットワーク:
1つのプロセッサの3分の1が割り込みで詰まっていますが、DPCは完全に並列化されています。
一般に、この構成では、約3ギガビット(1つのネットワークインターフェイスカードから)を提供することが可能であり、その場合にのみボトルネックが発生します。
念のため、RSSにはあまり知られていませんが、Send Side Scalingがあります。 バッファのリストを送信する前にハッシュ値を設定すると、確立された間接テーブルに従って、送信完了後の割り込みが配信されます。
ここではRSSについて読むことができ、 ここではRSSの機能を説明する写真で優れたプレゼンテーションがあります。 興味深い場合は、RSSの仕組みを自分の言葉で説明することもできますが、私にとっては、ソースを読む方が良いでしょう。
TCPオフロードエンジン
Linux で RSSのようなものが表示されようとしている場合(Linuxで通常のハードウェアRSSをサポートすることについての言及は見つかりませんでした。 Linux上のTOEでは、すべてが公式に複雑です。 TOEサポートを実装するChelsio (ハイエンドネットワークカードのメーカーの1つ)からのパッチは拒否され、代わりに、ある種の完全にばかげた言い訳が始まりました (BSDとWindowsが長年にわたって通常のTOEサポートを持っていることに留意する価値がある) 。
それで何ですか? TOEは、ハードウェアレベルでの完全なTCPIP実装です:配信確認、エラーの再送信、ウィンドウ制御など:DMA経由のネットワークカードは、メモリから直接データを取得し、パケットに切り取り、ヘッダーを添付し、(割り込みを使用して)最も極端な場合。
デフォルトでは、TOEは自動モードです。 チムニーオフロードの状態を見る:
スクリーンショットはアクティブなテスト中に撮影されましたが、統計では、単一の接続がネットワークインターフェイスカードにアップロードされていないことが示されています(理由について)。 強制的に有効にします(そしてしばらくしてから統計情報をリクエストします):
その理由は次のとおりです。このネットワークカードにダウンロードできる接続は1024のみです(実際には、システムは1022をダウンロードできました)。 かなり高価なリソースなので、すべてを連続してアンロードできます。 システムはヒューリスティックに、長時間続く接続の検出(httpを介した大きなファイルの取得/配置、ファイルサーバーへのファイルコンテンツの送信など)を試み、最初にそれらをアンロードします。
しかし、まだ何が起こったのか見てください。 プロセッサーは3回アンロードされました。
ISRとDPCの両方の数(および費やされた時間)は非常に減少しました。
All Articles