Intel Core 2 CPUサイクル分析
アプリケーションのパフォーマンスを改善するために分析する場合、利用可能な最も強力な手法は、CPUサイクルの詳細な分析です。 従来の命令完了の分析は、命令の並べ替え(Out of Order、OOO)を使用するアーキテクチャについて語る場合には役立ちそうにありません。その主なタスクは、完了するまで命令を実行し続けることです。
サイクルの使用の計算に基づく方法論を開発するには、OOO実行メカニズムの基本を理解する必要があります。 非常に簡略化されたブロック図を図1に示します。
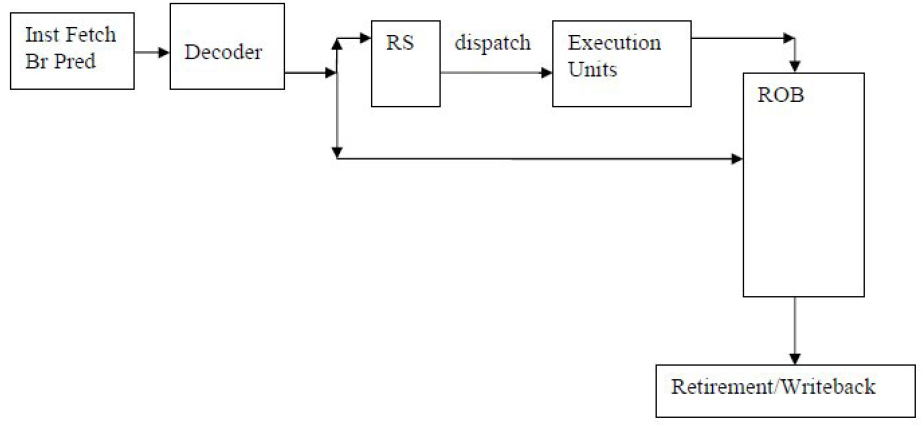
命令がマイクロオペレーション(uops)でデコードされた後、必要なリソースが利用可能であればそれらは渡されます。
これ(とりわけ):
可視レジスターでの状態の完了と遅延記録は、正しい実行ブランチにある命令とマイクロオペレーションに対してのみ実行されます。 誤って予測された分岐の命令とマイクロオペレーションは、遷移予測エラーが検出されるとすぐにリセットされ、正しい分岐がロードされます。 実行ブランチの正しい命令の完了は、次の2つの条件に従って発生する可能性があります。
このような仕組みにより、プログラムの可視状態は、命令の正常な実行の状態と常に一致します。
この設計の「魔法」は、たとえば、メモリからのデータの到着を待機することによって最も古い命令がブロックされた場合、オペランドが利用可能な後続の独立した命令を操作デバイスに送信し、ROBに保存して完了を待機できることです。 以前のすべての作業が完了すると、彼らは混雑します。
パフォーマンス分析の観点からの困難は、システム内の命令の完了がバッチで発生することです。つまり、一部のサイクルは完全な命令を生成せず、一部は大量のフローを伴うことです。 したがって、完了ブロックで別のサイクルで発生することは非常に有益ではなく、実際に何が起こるかを理解するには、時間と関係の平均値を使用する必要があります。 新たな問題は、リレーションシップがパフォーマンスメトリックとして使用される場合、アプリケーションの最適化プロセスが分子と分母の両方を必然的に変更し、進捗状況に疑問を投げかけることです。 サイクルを最適化する場合は、命令実行の標準インジケータである「命令あたりのサイクル、CPI」を考慮してください。
高いCPIはパフォーマンスの低下の兆候と見なされ、低い値は良好なパフォーマンスの兆候と見なされます。 最適化プロセス中にサイクルがベクトル化される場合、つまりコンパイル中にストリーミングSIMD拡張機能(SSE)セットから命令が生成される場合、完了した命令の数は大幅に(2回以上)減少します。 ただし、この最適化は、実行を停止する最終レベルキャッシュへの呼び出しの失敗などに影響しないため、アカウントに費やされるサイクル数が同じ程度に減少することはほとんどありません。 最終的に、サイクルのベクトル化は、CPIの数の増加のみを保証します。 実際、CPIを削減するには、完了した命令の数を増やす必要があります!
中央処理装置の寿命のイベント数の関係に基づくメトリックに焦点を合わせる代わりに、目的の作業の実行に消費されるサイクル数の削減に単に焦点を合わせることができます。
サイクルの使用の分析によりタスクが簡素化され、開発者はサイクルをカウントすることでコンポーネントを消費するコンポーネントの個々の寄与を減らすことができます。 この場合、主な指標はサイクルのみであり、アプリケーション最適化プロセスは常に主な指標を下げます。
次:
PDF形式の記事全文
サイクルの使用の計算に基づく方法論を開発するには、OOO実行メカニズムの基本を理解する必要があります。 非常に簡略化されたブロック図を図1に示します。
命令がマイクロオペレーション(uops)でデコードされた後、必要なリソースが利用可能であればそれらは渡されます。
これ(とりわけ):
- マイクロステーションがオペランドの出現を待つリザベーションステーション(RS)のスペース。
- マイクロオペレーションが完了のためにキューを待機するリオーダーバッファ(ROB)のスペース。
- メモリーの操作(ロードおよびアンロード)に関連するマイクロ操作の場合、十分な量のロードおよびアンロードバッファー。
可視レジスターでの状態の完了と遅延記録は、正しい実行ブランチにある命令とマイクロオペレーションに対してのみ実行されます。 誤って予測された分岐の命令とマイクロオペレーションは、遷移予測エラーが検出されるとすぐにリセットされ、正しい分岐がロードされます。 実行ブランチの正しい命令の完了は、次の2つの条件に従って発生する可能性があります。
- この命令に関連するすべてのマイクロオペレーションが完了しているため、命令全体を完了できます。
- 正しく予測されたブランチ内の以前のすべての命令とそれらのマイクロオペレーションが完了しました。
このような仕組みにより、プログラムの可視状態は、命令の正常な実行の状態と常に一致します。
この設計の「魔法」は、たとえば、メモリからのデータの到着を待機することによって最も古い命令がブロックされた場合、オペランドが利用可能な後続の独立した命令を操作デバイスに送信し、ROBに保存して完了を待機できることです。 以前のすべての作業が完了すると、彼らは混雑します。
パフォーマンス分析の観点からの困難は、システム内の命令の完了がバッチで発生することです。つまり、一部のサイクルは完全な命令を生成せず、一部は大量のフローを伴うことです。 したがって、完了ブロックで別のサイクルで発生することは非常に有益ではなく、実際に何が起こるかを理解するには、時間と関係の平均値を使用する必要があります。 新たな問題は、リレーションシップがパフォーマンスメトリックとして使用される場合、アプリケーションの最適化プロセスが分子と分母の両方を必然的に変更し、進捗状況に疑問を投げかけることです。 サイクルを最適化する場合は、命令実行の標準インジケータである「命令あたりのサイクル、CPI」を考慮してください。
高いCPIはパフォーマンスの低下の兆候と見なされ、低い値は良好なパフォーマンスの兆候と見なされます。 最適化プロセス中にサイクルがベクトル化される場合、つまりコンパイル中にストリーミングSIMD拡張機能(SSE)セットから命令が生成される場合、完了した命令の数は大幅に(2回以上)減少します。 ただし、この最適化は、実行を停止する最終レベルキャッシュへの呼び出しの失敗などに影響しないため、アカウントに費やされるサイクル数が同じ程度に減少することはほとんどありません。 最終的に、サイクルのベクトル化は、CPIの数の増加のみを保証します。 実際、CPIを削減するには、完了した命令の数を増やす必要があります!
中央処理装置の寿命のイベント数の関係に基づくメトリックに焦点を合わせる代わりに、目的の作業の実行に消費されるサイクル数の削減に単に焦点を合わせることができます。
サイクルの使用の分析によりタスクが簡素化され、開発者はサイクルをカウントすることでコンポーネントを消費するコンポーネントの個々の寄与を減らすことができます。 この場合、主な指標はサイクルのみであり、アプリケーション最適化プロセスは常に主な指標を下げます。
次:
- パフォーマンスベースの分析
- ダウンタイムの分解
- 遷移予測エラーとインテリジェントな実行
- 問題のあるパフォーマンスイベントの発生の結果の評価
- アプリケーション分析
- コードの最適化に関する重要な注意事項
- 命令レベルの並行性
PDF形式の記事全文
All Articles