Webページのメインコンテンツをプログラムで取得する
情報ノイズからWebページを消去するタスクは、情報検索の緊急のタスクの1つです。 その本質は、情報ノイズをクリアし、メインコンテンツのみを取得することです。
例を考えてみましょう:
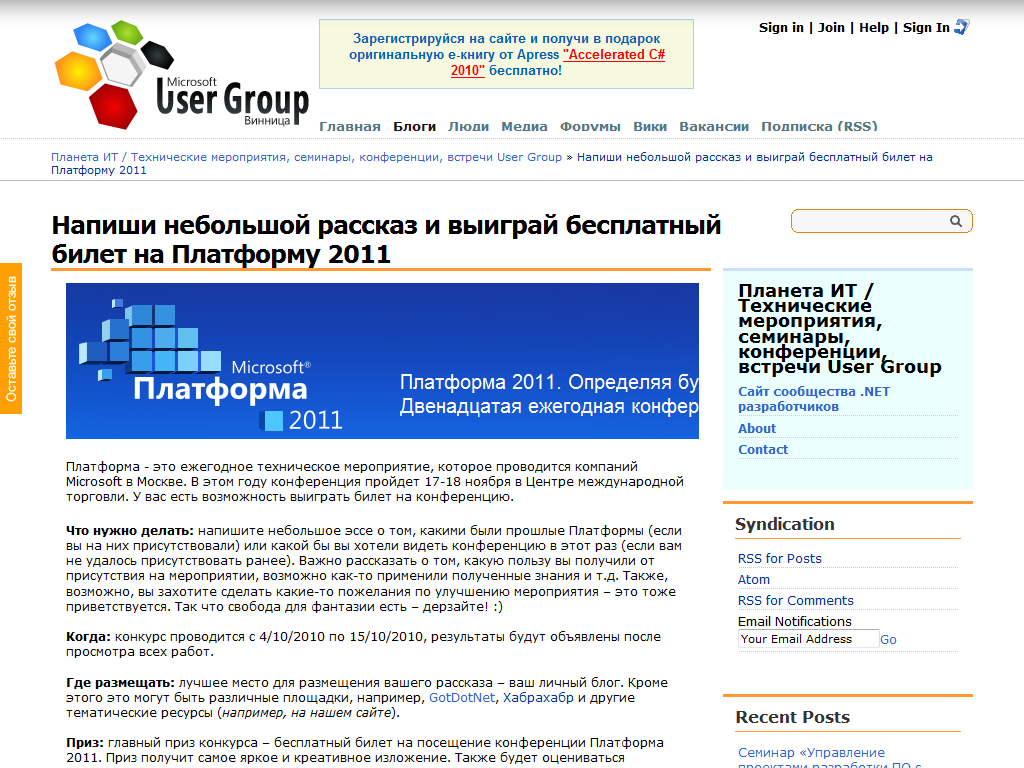
メインコンテンツは、ページのこの部分と見なすことができます。

適用できる場所:
ソリューションの説明に進む前に、既存のソリューションについて簡単に説明します。 HTML5の出現により、仕様が新しいセマンティック要素を暗示しているため、メインコンテンツを見つける問題はなくなるはずです。 それらをより詳細に検討しましょう。
現在、次のセマンティック要素が想定されています。

現在、この方法を使用すると、次のような問題に直面しています。
ウェブサイト: http : //lab.arc90.com/experiments/readability/
可読性はArc90 Labの開発であり、Webページを読みやすい形式にするための小さなブックマークをインストールできます。 可読性は、そのメトリックを使用してDOMモデルを分析し、「有用な」コンテンツを識別します。
可読性の使用例:

現在、さまざまなブラウザ用のプラグインがあり、Safariではこの機能はSafari Readerと呼ばれています。 インターネットで作業する人にとってはこれで十分でしょうが、このツールを使用して独自のスクリプトを作成したい人はどうでしょうか。 実際、それについては後で詳しく説明します。
私の以前の記事の多くは、この問題の研究に捧げられてきました。特に、そのような出版物を読むことを提案します。
SmartBrowserの新しいバージョンが近日中にサイトで利用可能になります。 正しく認識されたWebページの割合は増加しましたが、モデルとアルゴリズムは実験と研究の結果として簡素化されました。
現在、SmartBrowserは次のようになっています。
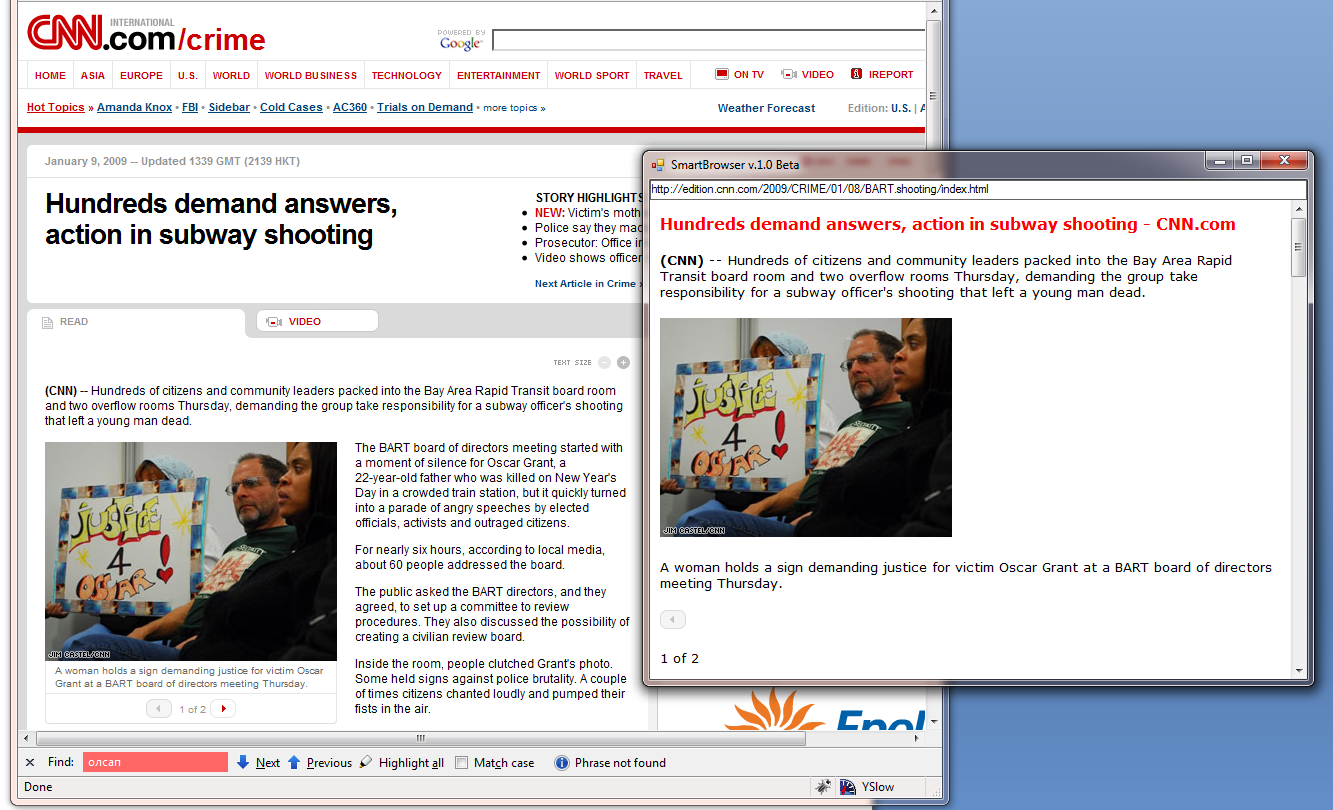
動作中のSmartBrowserの操作を検討してください。 Webページの処理は次のようになります。
すべてのロジックは、開発済みのデータ抽出SDKライブラリのMainContentExtractorクラスにカプセル化されています(現時点では、この機能はまだサイトで利用できません)。
その結果、多くの有名なサイトで次の結果が得られました。
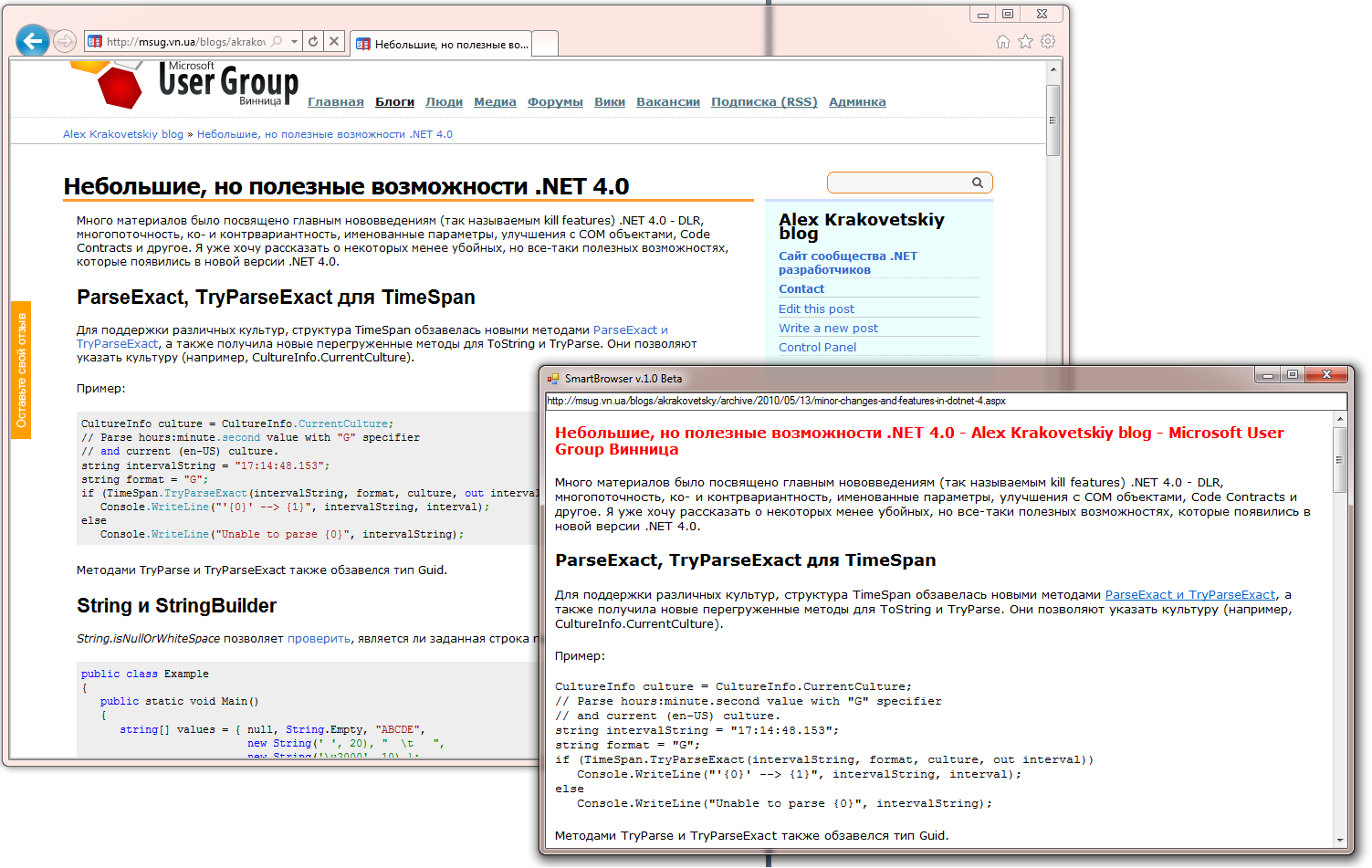
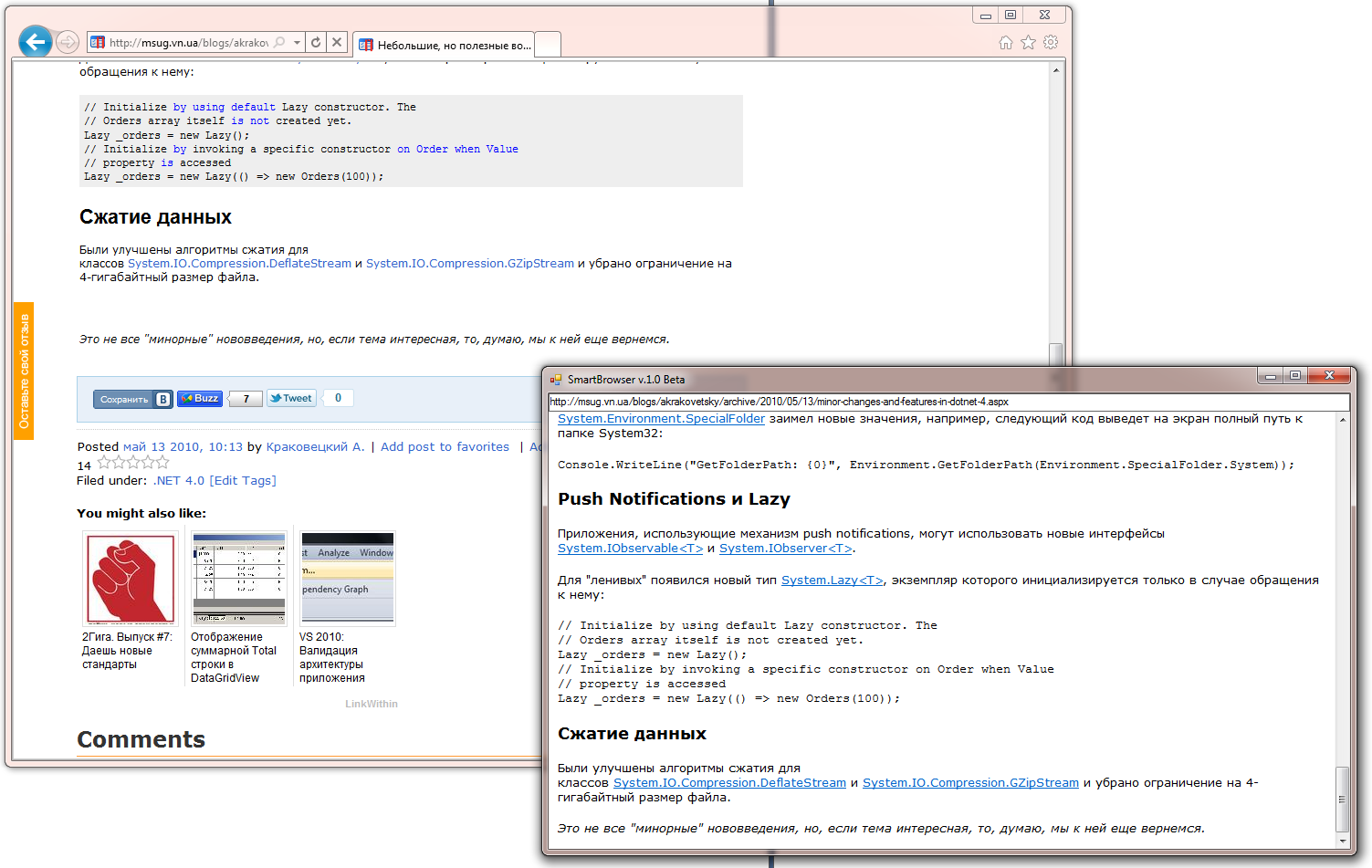

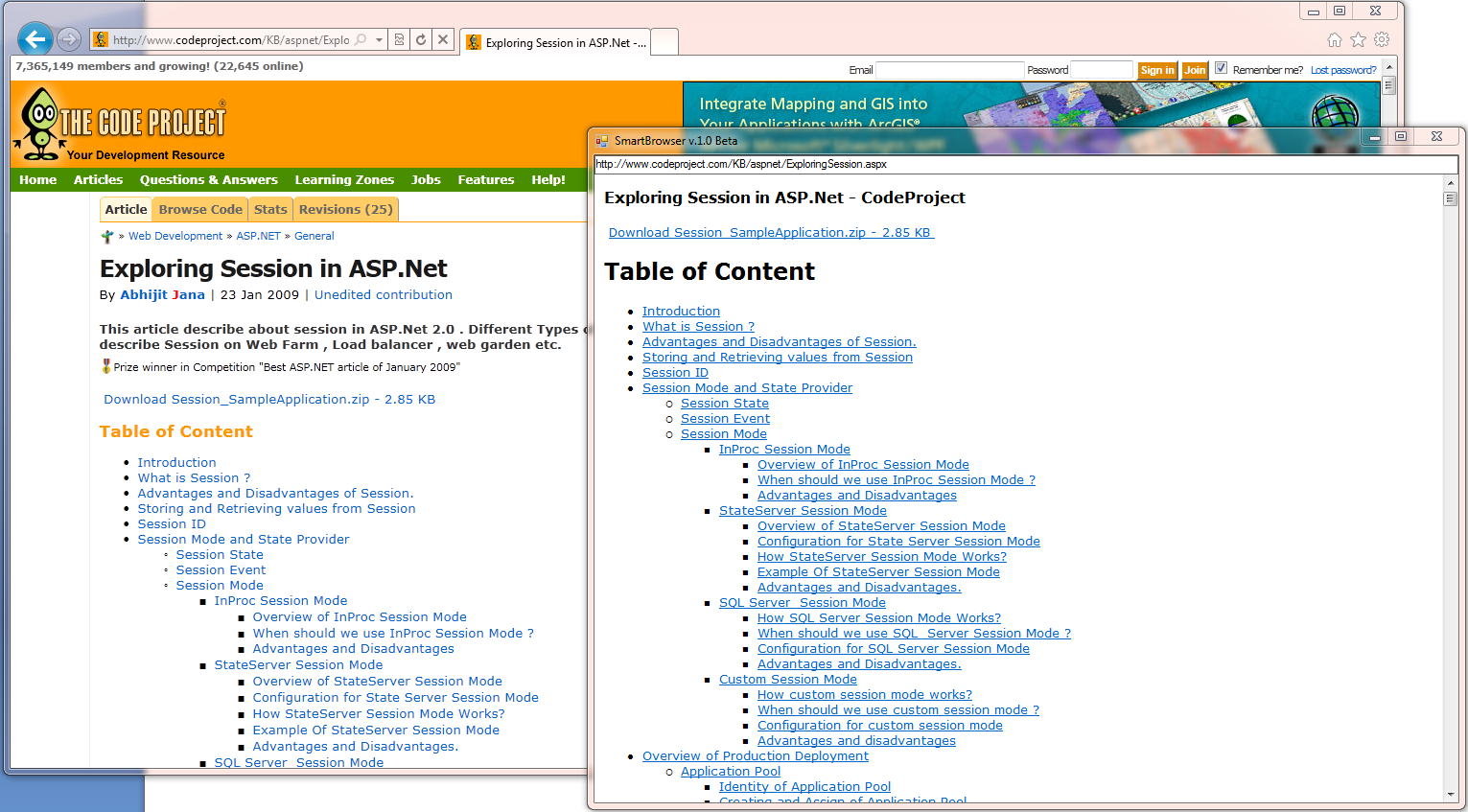

現時点では、たとえばハブラーなど、一部のサイトに問題があります。 そのため、研究開発は現在進行中ですが、近い将来、何らかの安定したアセンブリについて話せるようになることを願っています。
ご清聴ありがとうございました。
例を考えてみましょう:
メインコンテンツは、ページのこの部分と見なすことができます。
適用できる場所:
- 何らかの理由で他の方法が適切でない場合のコンテンツ配信サービス(たとえば、RSSフィードがない、または紹介だけがある)。
- さまざまなソースから情報を収集するシステム
- トラフィックを最小限に抑えることが重要なモバイルアプリケーション
- データマイニング、BIシステム
ソリューションの説明に進む前に、既存のソリューションについて簡単に説明します。 HTML5の出現により、仕様が新しいセマンティック要素を暗示しているため、メインコンテンツを見つける問題はなくなるはずです。 それらをより詳細に検討しましょう。
HTML5セマンティック要素
現在、次のセマンティック要素が想定されています。
- セクション-要素はテーマブロックをグループ化します。 セクション要素はネストできます
- header-セクション、テーブルなどのタイトルが含まれています
- フッター-Webページのフッター。通常、このブロックには、サイト、連絡先、著作権に関する情報が含まれます
- nav-ナビゲーションブロック、リンクのリスト、関連トピック
- 記事-メインコンテンツ
- 脇-メインブロックではなく、通常はページの両側にあります
現在、この方法を使用すると、次のような問題に直面しています。
- HTML5仕様はドラフトステータスです
- IEは現在これらのタグをサポートしていません
- すべての開発者は、統一されたWebページレイアウトルールに従う必要があります
- 不正なSEOオプティマイザーをキャンセルした人はいませんでした
読みやすさ
ウェブサイト: http : //lab.arc90.com/experiments/readability/
可読性はArc90 Labの開発であり、Webページを読みやすい形式にするための小さなブックマークをインストールできます。 可読性は、そのメトリックを使用してDOMモデルを分析し、「有用な」コンテンツを識別します。
可読性の使用例:
現在、さまざまなブラウザ用のプラグインがあり、Safariではこの機能はSafari Readerと呼ばれています。 インターネットで作業する人にとってはこれで十分でしょうが、このツールを使用して独自のスクリプトを作成したい人はどうでしょうか。 実際、それについては後で詳しく説明します。
情報ブロックの重要性に関する研究
私の以前の記事の多くは、この問題の研究に捧げられてきました。特に、そのような出版物を読むことを提案します。
- 情報ノイズからWebページを消去します
- SmartBrowserを使用したWebページのコンテンツ分析
- Webページのメインコンテンツを決定するためのSeoRank基準
- 情報の取得、検索結果を表示する最適な方法の発見などについて
SmartBrowserの新しいバージョンが近日中にサイトで利用可能になります。 正しく認識されたWebページの割合は増加しましたが、モデルとアルゴリズムは実験と研究の結果として簡素化されました。
現在、SmartBrowserは次のようになっています。
動作中のSmartBrowserの操作を検討してください。 Webページの処理は次のようになります。
MainContentExtractor r = new MainContentExtractor(new Uri(tbUrl.Text.Trim()));
var html = r.GetContent();
webBrowser1.DocumentText = r.getTitle().InnerText + html;
すべてのロジックは、開発済みのデータ抽出SDKライブラリのMainContentExtractorクラスにカプセル化されています(現時点では、この機能はまだサイトで利用できません)。
その結果、多くの有名なサイトで次の結果が得られました。
現時点では、たとえばハブラーなど、一部のサイトに問題があります。 そのため、研究開発は現在進行中ですが、近い将来、何らかの安定したアセンブリについて話せるようになることを願っています。
ご清聴ありがとうございました。
All Articles