プログラミング言語とマークアップ言語のソースコードの分析
..正規表現に任意のHTMLの解析を要求することは、Paris Hiltonにオペレーティングシステムの記述を要求することに似ていることは事実です。
Nemerleの最近のバージョンには、文法がPEGクラスに属する言語を解析するためのライブラリが含まれています。
PEGとは何ですか?
パーサーを作成する他のツールとは異なり、PEGは文法を記述するのではなく、その分析の戦略を記述しますが、実際には構文解析の戦略の記述は文法の記述です。 PEGを使用して記述されたパーサーには、テキストの長さから線形時間でこのクラスの文法を満たすテキストを解析するアルゴリズム( packrat )があります。
この方法で記述されたパーサーを使用して解析できる言語のクラスは、一般的なプログラミング言語(C#など)およびマークアップ言語をカバーするのに十分な広さです。 明らかに、正規表現のすべての機能をカバーしています。
RegExpがあるときに何かが必要なのはなぜですか?
正規表現を操作するためのライブラリは、ほぼすべてのプログラミング言語の標準ライブラリのセットに含まれています。 このウォーキングアクセシビリティのため、適切な場所(通常の文法の解析)とそうでない場所(htmlおよびその他の再帰構造の解析)で使用されます。
stackoverflowからの引用:
..正規表現に任意のHTMLの解析を要求することは、Paris Hiltonにオペレーティングシステムの記述を要求することに似ていることは事実です。
もう1つの極端な例は、yaccやantlrなどのパーサージェネレーターです。 提供されている文法に従ってパーサーを生成するタスクに対処しますが、実際には、プログラマーがパーサーを使用するよりも自分でパーサーを作成する方が「簡単」です。 この理由は、おそらく、これらのツールを使用するのが難しいことです。また、eDSLである正規表現とは異なり、これらを使用するにはコード生成が必要であり、コード生成が不便です。
マクロは、NemerleでPEG文法パーサーを生成します。 したがって、コード生成は消滅し、不規則な文法での作業はeDSLでの作業に変わります。正規表現の段階的な可用性が、パーサーの生成機能に追加されます。 NemerleでPEGを使用する例を見てみましょう
TeX言語の数学的マークアップの分析
例としてTeX数学マークアップ文法を使用したPEG文法を考えてみましょう。 この写真のソースを分析します
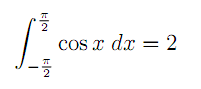
ここにいる
\int_{-\frac{\pi}{2}}^{\frac{\pi}{2}} \cos x \; dx = 2
コマンド(\ int、\ pi、\ cos)、エスケープシーケンス(\;)、ネストされたブラケット構造({.. {..} ..})およびその他すべてで構成されていることがわかります。
まず、このテキストが解析される構造を定義します。
public variant WordTexAst { | Command { name : string } // | Escape { symbol : string } // escape | Group { data : WordTexAst.Sequence } // | Data { data : string } // | Sequence { words : list[WordTexAst]} }
他のプログラミング言語では、代数データ型またはラベル付きユニオンとも呼ばれるオプションを使用しました。
言語パーサーを作成するには、クラスを宣言し、このクラスの属性で言語解析戦略を記述し、解析された情報からツリーを構築する関数を各解析ルールに関連付ける必要があります。 属性から始めましょう
[PegGrammar(ast, grammar { commandName = ['a'..'z','A'..'Z']+; escapeLetter = ';' / ','; letter = ['a'..'z','A'..'Z','0'..'9'] / '^' / '_' / '=' / ' ' / '-' / '+' / '/' / '(' / ')' / '[' / ']'; command : WordTexAst = '\\' commandName; escape : WordTexAst = '\\' escapeLetter; group : WordTexAst = '{' ast '}'; data : WordTexAst = letter+; word : WordTexAst = command / escape / group / data; ast : WordTexAst.Sequence = word+; })]
マクロの最初のパラメーターは、解析を開始するルールです。 次に-Backus-Naurの形式に非常に似ている文法(戦略)の説明。 左の列-定義されているルール、その後-ルールによって解析された構造のタイプ。 最初の3つのケースでは、これらのルールは残りのルールの定数として機能するため、省略されます。 等号の後に、解析されたテキストの構造が記述されます。これは、スペースで区切られた定数やその他の規則によって指定できます。 構造を記述するために、たとえば「+」などの特殊文字を使用できます-ルールを1回以上適用します。「a / b」は解析ルール「a」を適用し、それが機能しない場合は解析ルールは「b」です。 最初の解析ルールが正常に適用された場合、この「or」演算子は可換ではないことが重要です。その場合、代替は考慮されません。
属性に加えて、パーサークラスにいくつかのメソッドを追加する必要があります-解析ルールごとに1つです。 引数の数とその型は、右側の部分(等号の後)でこの規則によって使用される規則に準拠する必要があります。
完全なサンプルパーサーコード:
[PegGrammar(ast, grammar { commandName = ['a'..'z','A'..'Z']+; escapeLetter = ';' / ','; letter = ['a'..'z','A'..'Z','0'..'9'] / '^' / '_' / '=' / ' ' / '-' / '+' / '/' / '(' / ')' / '[' / ']'; command : WordTexAst = '\\' commandName; escape : WordTexAst = '\\' escapeLetter; group : WordTexAst = '{' ast '}'; data : WordTexAst = letter+; word : WordTexAst = command / escape / group / data; ast : WordTexAst.Sequence = word+; })] public class TexParser { private escape(_ : NToken, symbol : NToken) : WordTexAst { WordTexAst.Escape(GetText(symbol)) } private command(_ : NToken, commandName : NToken) : WordTexAst { WordTexAst.Command(GetText(commandName)) } private group(_ : NToken, ast : WordTexAst.Sequence, _ : NToken) : WordTexAst { WordTexAst.Group(ast) } private data(arg : NToken) : WordTexAst { WordTexAst.Data(GetText(arg)) } private word(arg : WordTexAst) : WordTexAst { arg } private ast(data : List[WordTexAst]) : WordTexAst.Sequence { WordTexAst.Sequence(data.ToList()) } }
NTokenタイプはまだ説明されていません。 これは、「定数」ルールを満たす解析済みテキスト内のサブストリングに対応するクラスです。 GetTextメソッドを使用して、このクラスのオブジェクトを文字列に変換できます。
パーサーの使用を示すために残っています:
def parser = TexParser(); def text = @"\int_{-\frac{\pi}{2}}^{\frac{\pi}{2}} \cos x \; dx = 2"; def (pos,ast) = parser.TryParse(text); when (pos == text.Length) Console.WriteLine("success");
TryParseメソッドはテキストを解析し、posには解析された文字数が含まれます。文字列が完全に解析される場合、posは文字列の長さと等しくなり、プレフィックスのみが解析される場合、posにはプレフィックスの長さが含まれます。
おわりに
この記事では、PEG文法パーサーを構築するためのeDSLについて説明します。 再帰的言語のパーサーの構築に加えて、正規表現が複雑すぎて処理できない場合に、通常の文法を解析するために使用できます。
このeDSLはマクロとして実装され、コンパイル段階で効果的な解析アルゴリズムに拡張されます。 生成されたdllは、あらゆる.net言語で使用できます。 したがって、このライブラリの使用は1つの言語に限定されません。
参照資料
現在のNemerleバージョン
rsdn.ruのフォーラム(ロシア語)
Googleグループ(英語)
All Articles