歩行者検出
 歩行者検出は、主に無人車両の研究で使用されます。 歩行者検出の一般的な目標は、車両が人と衝突するのを防ぐことです。 最近、Habréで「 スマートカー 」に関するトピックがありました。 このようなシステムの作成は、非常に一般的な研究分野です( Darpaチャレンジ )。 私はスマートカーの同様のプロジェクトのために歩行者の認識に従事しています。 明らかに、歩行者検出の問題はソフトウェアであり、衝突回避はハードウェアです。 この記事では、ソフトウェアの部分のみに言及し、画像内の人物を検出する1つの方法と分類アルゴリズムについて簡単に説明します。
歩行者検出は、主に無人車両の研究で使用されます。 歩行者検出の一般的な目標は、車両が人と衝突するのを防ぐことです。 最近、Habréで「 スマートカー 」に関するトピックがありました。 このようなシステムの作成は、非常に一般的な研究分野です( Darpaチャレンジ )。 私はスマートカーの同様のプロジェクトのために歩行者の認識に従事しています。 明らかに、歩行者検出の問題はソフトウェアであり、衝突回避はハードウェアです。 この記事では、ソフトウェアの部分のみに言及し、画像内の人物を検出する1つの方法と分類アルゴリズムについて簡単に説明します。
はじめに
私の仕事では、赤外線カメラとLIDARの 2つのセンサーを使用しています。 人間の体温は通常、環境よりも高いです。 したがって、人の赤外線カメラからの画像は簡単にローカライズできます。 原則として、衣服で覆われていない体の部分、つまり頭と手は簡単に検出できます。 しかし、カメラだけの助けでは、オブジェクトのサイズを判断することは困難です。人がカメラからどれだけ離れているかを言うことは困難です。 ここで、LIDARが助けになります。 オブジェクトまでの距離を測定します。
LIDARが必要な理由 まずは写真を見てみましょう。 画像の前処理の全体的なアイデアは、関心のある領域のローカライズに帰着します。 画像全体がどのようなものかは気にしません。 私たちはいくつかの分野を強調し、さらにそれらと協力したいと思います。 理想的には、関心領域は人の画像全体をカバーする必要があります。 人間の頭は環境よりも暖かいことを知っているため、画像で簡単に見つけることができます。 次に、人のサイズを推定する必要があります。 ここで、LIDARからのデータが助けになります。 オブジェクトまでの距離、カメラの焦点距離、現実世界の座標でのオブジェクトのサイズがわかれば、オブジェクトのサイズをピクセル単位で簡単に計算できます。 平均的な人がそのような長方形に収まると信じて、2 x 1メートルの長方形に等しい実世界の座標でオブジェクトのサイズを決定しました。 しかし、画像の座標系では、関心領域のサイズはまだ異なります。 別のスケール変換、および最終的にすべての対象領域は、実世界の同じ領域をカバーするだけでなく、同じピクセル寸法も持ちます。
2つのセンサーのデータを結合する方法を考えてみましょう:画像内でホットな領域を見つけます(これが人の頭であると仮定します)、この領域の中心が位置する角度を計算し、この角度からLIDAR座標系に移動し、この角度からオブジェクトまでの距離を取得します。 ある座標系から別の座標系に角度を変換するには、センサーを較正する必要があります。 センサーの実際のキャリブレーションの代わりに、センサーの中心が水平面で一致する特定の場所が使用されます。
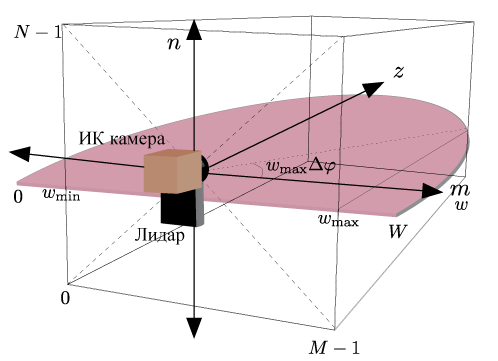
もちろん、テストマシンではすべてが少し異なります。 まず、上の図は静的センサーの位置を示しています。その位置は時間とともに変化しません。 次に、テストマシンでは、別のタイプのLIDAR(3次元)が使用されます。 車の屋根の中央に設置されています。 カメラは屋根の前に取り付けられています。 したがって、センサーの中心は、もはや一点にあると見なすことはできません。 この問題を解決するための2つのオプションがあります。1つのセンサーの座標系から別のセンサーの座標系へのデータの並列転送(センサー間の距離を測定した後)、または(自動的に)センサーを較正します。
関心のある領域を抽出する
パターン認識に使用される特徴の抽出とその分類には多くの時間がかかります。 Matlabaで6〜7個のオブジェクトを含む単一のフレームを処理するには、1分かかります。 リアルタイム指向のシステムでは、このような長い処理は受け入れられません。 速度は、検出された温かい物体の数に大きく影響され、人だけが温かい物体ではありません。 車、窓、信号機の部品も、一般的な温度背景に対して目立つことがあります。 このペーパーでは、情報処理の速度に重点を置いています。 間違いなく人間ではないオブジェクトの最大数をすぐに取り除く必要があります。 この場合、一人の実在の人物を見逃さないことをお勧めします。 残りのすべてのオブジェクトは、本格的な静的分類子を使用して分類できます。
画像内の高温領域は、「最大安定極値領域」と呼ばれる方法を使用して検出されます(英語版の最大安定極値領域のMECP [1])。 元の画像は、しきい値が変化するしきい値関数によって処理されます。 その結果、新しい一連の画像が作成され、そのサイズはさまざまなしきい値の数に対応します(たとえば、ピクセル値が0〜255のモノクロ画像の場合、256個の画像が得られます)。 シーケンスの最初の画像は完全に白になります。 黒の領域がさらに表示され、シーケンス内の最新の画像は完全に黒になります。 次の図は、アニメーションの形式でこのシーケンスを示しています。

画像内の白い領域は極値の領域です。 極値のこの領域またはその領域が画像のシーケンスにどれだけ存在していたかを分析できます。 これを行うには、別のしきい値関数を使用できます。 たとえば、値が10の場合、極値領域がシーケンスの10を超えるイメージに存在する場合、この領域は最も安定した極値領域と呼ばれます。
最も安定した関心領域を見つけたら、それらをもう少しフィルタリングします。アスペクト比を確認し、カメラから遠く離れたオブジェクトを破棄し、重複領域を処理します。

ソース画像 | 
極値の最も安定した領域 |

興味のある分野 | 
フィルタリングされた関心領域 |
分散
オブジェクトを分類するためのメトリックとして、「分散」が使用されます[2]。 このメトリックの計算にはほとんど時間がかかりません。また、その値は照明条件に依存しません。 それは式によって考慮されます
 。 元の作業では、分散はオブジェクトの輪郭に沿って計算されます。 関心領域から輪郭を取得するには、ガウスフィルターとSobel演算子を順番に適用します。 画像が特定のクラスに属するかどうかの決定は、しきい値関数を使用して行われます。 人の画像は、車や建物の一部の画像よりも分散値が低くなります。
。 元の作業では、分散はオブジェクトの輪郭に沿って計算されます。 関心領域から輪郭を取得するには、ガウスフィルターとSobel演算子を順番に適用します。 画像が特定のクラスに属するかどうかの決定は、しきい値関数を使用して行われます。 人の画像は、車や建物の一部の画像よりも分散値が低くなります。

おわりに
写真のアルゴリズムの結果:
 |  |
 |  |
テストコンピュータには、周波数が3 GHzのIntelコア2デュオプロセッサ、6 MBキャッシュ、および2 GB RAMが搭載されています。 テストはMatlabシステムで実行されました。 1フレームの平均処理時間は64ミリ秒です。 これは、システムが1秒で約16フレームを処理できることを意味します。 もちろん、これは毎分1フレームよりも優れています。
次の質問が自然に発生します。分類の分散はどの程度信頼できるか、本格的な分類器を使用する場合、1つのフレームでの作業に費やす時間はどのように増加しますか。 これらの質問にはまだ答えがありません。 今、私はちょうどそれに取り組んでいます。 結果が出ます-お知らせします!
文学
[1] J. Matas、O。Chum、M。Urban、およびT. Pajdla、「最大限に安定した極値領域からの堅牢で広いベースラインステレオ」、British Machine Vision Conference、2002、pp。 384–396。
[2] ALヒロノブ、AJリプトン、H。フジヨシ、およびRSパティル、「リアルタイムビデオからのターゲットの分類と追跡の移動」、コンピュータービジョンの応用、1998年。WACV'98。 Proceedings。、第4回IEEEワークショップ、1998年10月、pp。 8-14。
All Articles