एमएस SQL सर्वर 2000 में संग्रहीत प्रक्रियाओं को संकलित करते समय, संग्रहीत प्रक्रियाओं को प्रक्रियात्मक कैश में रखा जाता है, जो प्रदर्शन को बढ़ाने में मदद कर सकता है, जब वे संग्रहीत प्रक्रिया कोड के पार्सिंग, अनुकूलन और संकलन की आवश्यकता को समाप्त करके प्रदर्शन किया जाता है।
दूसरी ओर, विपरीत प्रभाव पड़ने वाले नुकसान को संग्रहीत प्रक्रिया के संकलित कोड के भंडारण में छिपाया जाता है।
तथ्य यह है कि जब एक संग्रहीत कार्यविधि को संकलित किया जाता है, तो उन संचालकों की निष्पादन योजना, जो प्रक्रिया कोड का संकलन करती है, क्रमशः संकलित होती है, यदि संकलित संग्रहीत कार्यविधि को कैश किया जाता है, तो इसका निष्पादन योजना भी कैश की जाती है, और इसलिए, संग्रहीत कार्यविधि को किसी विशिष्ट स्थिति और क्वेरी मापदंडों के लिए अनुकूलित नहीं किया जाएगा।
इसे प्रदर्शित करने के लिए एक छोटा सा प्रयोग करेंगे।
कदम 1 । एक डेटाबेस बनाना।
प्रयोग के लिए, एक अलग डेटाबेस बनाएँ।
DATABASE बनाइए test_sp_perf
ON (NAME = 'test_data', FILENAME = 'c: \ temp \ test_data', SIZE = 1, MAXSIZE = 10, FILEGROWTH = 1Mb)
लॉग ऑन (NAME = 'test_log', FILENAME = 'c: \ temp \ test_log', SIZE = 1, MAXSIZE = 10, FILEGROWTH = 1Mb)
कदम 2. एक तालिका बनाना।
बनाएँ तालिका sp_perf_test (column1 int, column2 char (5000))
चरण 3. परीक्षण लाइनों के साथ तालिका भरना। डुप्लीकेट पंक्तियों को जानबूझकर तालिका में जोड़ा जाता है। 1 से 10,000 तक की संख्या के साथ 10,000 रेखाएं और 50,000 की संख्या के साथ 10,000 रेखाएं।
DECLARE @i int
SET @ i = 1 है
WHILE (@i <10000)
शुरू
INSERT INTO sp_perf_test (column1, column2) VALUES (@ i, 'Test string #' + CAST (@i as char (8)))
INSERT INTO sp_perf_test (column1, column2) VALUES (50000, 'टेस्ट स्ट्रिंग #' + CAST (@i as char (8)))
SET @ i = @ i + 1
अंत
COUNT (*) से sp_perf_test चुनें
GO
STEP 4. नॉन-क्लस्टर्ड इंडेक्स बनाना। चूंकि निष्पादन योजना प्रक्रिया के साथ कैश की जाती है, इसलिए इंडेक्स का उपयोग सभी कॉल के लिए समान किया जाएगा।
NONCLUSTERED INDEX CL_perf_test पर sp_perf_test (column1) बनाएँ
GO
चरण 5. एक संग्रहीत कार्यविधि बनाना। प्रक्रिया केवल शर्त के साथ SELECT स्टेटमेंट को निष्पादित करती है।
निर्माण PROC proc1 (@ अपरम int)
के रूप में
स्तंभ 1 का चयन करें, स्तंभ 2 से sp_perf_test WHERE column1 = @ param
GO
चरण 6. संग्रहित प्रक्रिया शुरू करना। एक कमजोर प्रक्रिया शुरू करते समय, एक चयनात्मक पैरामीटर विशेष रूप से उपयोग किया जाता है। प्रक्रिया के परिणामस्वरूप, हमें 1 पंक्ति मिलती है। निष्पादन योजना गैर-संकुल सूचकांक के उपयोग को इंगित करती है, जैसा कि क्वेरी चयनात्मक है और यह स्ट्रिंग निकालने का सबसे अच्छा तरीका है एकल पंक्ति लाने के लिए अनुकूलित एक प्रक्रिया को प्रक्रियात्मक कैश में संग्रहीत किया जाता है।
EXEC proc1 1234
GO

चरण 7. एक गैर-चयनात्मक पैरामीटर के साथ संग्रहीत प्रक्रिया शुरू करना। 50,000 का मान एक पैरामीटर के रूप में उपयोग किया जाता है। ऐसे पहले कॉलम के बारे में 10,000 के साथ क्रमशः, गैर-क्लस्टर इंडेक्स और बुकमार्क लुकअप ऑपरेशन का उपयोग अक्षम है, लेकिन चूंकि निष्पादन योजना के साथ संकलित कोड प्रक्रियात्मक कैश में संग्रहीत है, इसलिए इसका उपयोग किया जाएगा। निष्पादन योजना यह दर्शाती है, साथ ही यह भी कि बुकमार्क लुकअप ऑपरेशन 9999 लाइनों के लिए किया गया था।
EXEC proc1 50,000
GO

STEP 8. पहले फ़ील्ड के साथ पंक्तियाँ 50,000 के बराबर लाएं। जब एक अलग क्वेरी निष्पादित करते हैं, तो क्वेरी को पहले कॉलम के एक विशिष्ट मान के साथ अनुकूलित और संकलित किया जाता है। नतीजतन, क्वेरी ऑप्टिमाइज़र निर्धारित करता है कि फ़ील्ड को कई बार डुप्लिकेट किया गया है और टेबल स्कैन ऑपरेशन का उपयोग करने का निर्णय लिया गया है, जो इस मामले में गैर-क्लस्टर इंडेक्स का उपयोग करने की तुलना में बहुत अधिक कुशल है।
स्तंभ 1 का चयन करें, कॉलम 2 से sp_perf_test WHERE column1 = 50000
GO
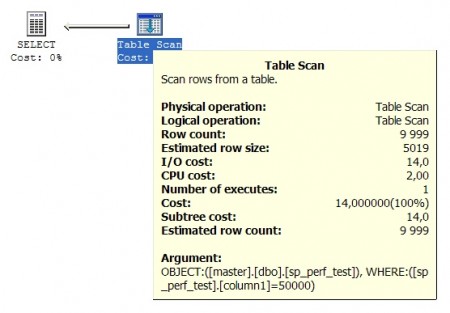
इस प्रकार, हम यह निष्कर्ष निकाल सकते हैं कि संग्रहीत प्रक्रियाओं का उपयोग करने से हमेशा क्वेरी प्रदर्शन में सुधार नहीं हो सकता है। आपको उन संग्रहीत प्रक्रियाओं के बारे में बहुत सावधान रहना चाहिए जो एक चर संख्या के साथ परिणामों के साथ काम करते हैं और विभिन्न निष्पादन योजनाओं का उपयोग करते हैं।
आप अपने MS SQL सर्वर पर प्रयोग को दोहराने के लिए स्क्रिप्ट का उपयोग कर सकते हैं।