मशीन लर्निंग पर हमारा लेख उन तकनीकों में से एक की व्याख्या करता है जिनका उपयोग खोज इंजन में तब किया जाता है जब पाठ को वाक्यों में सही ढंग से तोड़ने की आवश्यकता होती है। इस समस्या का समाधान मौलिक महत्व का है, उदाहरण के लिए, जब खोज इंजनों द्वारा स्निपेट्स का निर्माण किया जाता है या जब शब्द उपयोग संदर्भों के डेटाबेस का निर्माण होता है। अब यह तकनीक खोज सूचकांक Mail.Ru में सन्निहित है। विधि की सटीकता, हमारी टिप्पणियों के अनुसार, 99% से कम नहीं है।
हमारे लेख में यह कैसे काम करता है पढ़ें।
समस्या और मौजूदा समाधान
स्वचालित वर्ड प्रोसेसिंग सिस्टम विकसित करते समय, कार्य अक्सर पाठ को वाक्यों में सही ढंग से तोड़ने के कारण होता है। इसका समाधान मौलिक महत्व का है, उदाहरण के लिए, जब खोज इंजनों द्वारा स्निपेट्स का निर्माण किया जाता है या जब शब्द उपयोग संदर्भों के डेटाबेस का निर्माण होता है।
व्यवहार में, आपको पहले यह पता लगाना होगा कि क्या संकेत वाक्य का अंत है, फिर पाठ में उन स्थानों को निर्धारित करें जहां वाक्य विभक्त को छोड़ दिया गया था, उदाहरण के लिए, गलती से। महसूस करना (और गणना करना) दूसरा अधिक कठिन है, लेकिन, सौभाग्य से, यह तत्काल नहीं है, क्योंकि वाक्यों के निहित छोर स्पष्ट से कम सामान्य हैं।
वाक्यों के सिरों को डॉट्स, प्रश्न चिह्न और विस्मयादिबोधक, अंत-के-पैरा वर्ण, दीर्घवृत्त और, कुछ मामलों में, कॉलन द्वारा इंगित किया जा सकता है। मुख्य समस्या डॉट चरित्र द्वारा बनाई गई है, क्योंकि इसका उपयोग संक्षिप्त और शाब्दिक संकेतन में भी किया जाता है - दिनांक, सिफर, ईमेल पते, वेब पते, आदि।
यह निर्धारित करने के लिए कि इस संदर्भ में एक बिंदु एक वाक्य का अंत है, विभिन्न तरीकों को लागू किया जाता है, जिनमें से जटिलता परिणाम के लिए आवश्यकताओं पर निर्भर करती है। सबसे आम विधियां हैं जो नियमित अभिव्यक्तियों और मानक संक्षिप्त नाम तालिकाओं के उपयोग को शामिल करती हैं, जो काफी सरल मामलों में स्वीकार्य परिणाम देती हैं।
संक्षिप्त नाम तालिकाओं का मुख्य नुकसान यह है कि उन्हें गैर-मानक (कॉपीराइट) संक्षिप्तताओं के मामलों में लागू नहीं किया जा सकता है। इसके अलावा, वाक्य वाक्य के अंत में हो सकते हैं, और उनमें से कुछ, उदाहरण के लिए, "आदि", "और अन्य" अक्सर वाक्य के स्पष्ट अंत का संकेत देते हैं (वैसे, यह वाक्य एक अपवाद है)।
किसी संकेत के अंत के बारे में जानकारी संदर्भ में संग्रहीत है और कुछ नियमों के अनुसार प्रदर्शित की जाती है। केवल अपने स्वयं के अनुभव के आधार पर उन्हें तैयार करना इतना आसान नहीं है - विशेष रूप से इस तथ्य को ध्यान में रखते हुए कि उन्हें एक एल्गोरिथ्म के रूप में प्रस्तुत करने की आवश्यकता है।
लेकिन नियमों को प्राप्त करने के लिए जो 99% से अधिक सटीकता के साथ वाक्यों के सिरों के स्वचालित रूप से भेद करते हैं, फिर भी, यह संभव है।
हमारी विधि
जिस विधि को हमने Mail.Ru द्वारा खोज के लिए उपयोग करने का निर्णय लिया है, वह मूल नियमों (लगभग 40) का एक छोटा सा सेट बनाने के लिए है और फिर इन नियमों को लागू करने के परिणामों के आधार पर स्वचालित रूप से एक क्लासिफायरियर का निर्माण करना है।बुनियादी नियमों को दो प्रकारों में विभाजित किया जाता है - प्रतिस्थापन और संयोजन। उपादानों को नियमित अभिव्यक्तियों द्वारा परिभाषित किया जाता है और विशिष्ट, सरल संदर्भ संकेतों के लिए जाँच की जाती है, उदाहरण के लिए, "दाईं ओर रिक्त स्थान" या "बाईं ओर एक बड़ा अक्षर", आदि।
संयोजन बीजगणितीय निर्माण होते हैं जो क्रमपरिवर्तन से निर्मित होते हैं, उदाहरण के लिए, "बाईं ओर कैपिटल लेटर" + "राइट पर शीर्षक" (शीर्षक - एक कैपिटल लेटर से शुरू होने वाला शब्द)। बुनियादी नियमों में से प्रत्येक, जब एक विशिष्ट संदर्भ पर लागू होता है, तो दिए गए अंकों की संख्या, आमतौर पर 0, -1 या +1 देता है। अंतिम परिणाम की गणना वेक्टर से एक विशेष क्लासिफायरियर का उपयोग करके की जाती है।
इस दृष्टिकोण की एक अच्छी विशेषता यह है कि एक निर्णय लेने के लिए आपको सभी नियमों के मूल्यों की गणना करने की आवश्यकता नहीं है, लेकिन केवल उन लोगों की आवश्यकता है जिन्हें क्लासिफायर की आवश्यकता होगी। इसके अलावा, क्लासिफायर के लिए नियमों के महत्व के आधार पर, आप उन्हें बेहतर गुणवत्ता और प्रदर्शन प्राप्त कर सकते हैं।
सीखने के बारे में: निर्णय पेड़
बुनियादी नियमों का चयन मैन्युअल रूप से हुआ, विशेष रूप से विकसित घोषणात्मक भाषा का उपयोग करते हुए। क्लासिफायर बनाने के लिए, हमने "निर्णय पेड़ों" के आधार पर एक मशीन लर्निंग एल्गोरिदम का उपयोग किया।प्रशिक्षण को विभिन्न प्रकारों - वेब पेजों, कथा और औपचारिक ग्रंथों के दस्तावेजों पर क्रमिक रूप से किया गया। कुल मिलाकर, लगभग 10 हजार एपिसोड को संकेतों के विभाजन-विभाजकों की संख्या के अनुपात के साथ चुना गया था जो कि डिवाइडर नहीं हैं, 2 से 3 के रूप में। अंतिम पाने के लिए। 99% प्रतिशत सटीकता के लिए प्रशिक्षण के छह चरणों की आवश्यकता होती है।
प्रशिक्षण के पहले चरण के लिए, डेटा मैन्युअल रूप से तैयार किए गए थे: इस पर विचार करने के लिए लगभग 1000 एपिसोड लगे। प्रत्येक बाद के चरण में, एपिसोड को प्रशिक्षण सूची में जोड़ा गया जहां क्लासिफायर "गलत" या "संदेह" किया गया था।
सबसे महत्वपूर्ण नियम
जैसा कि पहले ही उल्लेख किया गया है, सीखने की प्रक्रिया में व्यक्तिगत नियमों का महत्व अपने आप निर्धारित होता है। एक निश्चित नियम के साथ आवश्यक जवाब के साथ प्राप्त किए गए स्कोर के सहसंबंध की डिग्री जितनी अधिक होगी, यह नियम सर्वेक्षण सूची में उतना ही अधिक होगा, और अधिक बार इसके कार्यान्वयन की जांच की जाएगी।प्रयोगों के परिणामस्वरूप, हमें पता चला कि सबसे महत्वपूर्ण नियमों में शामिल हैं:
• "विभाजक प्रकार", 3 नियम। बिंदु, प्रश्न चिह्न, और विस्मयादिबोधक बिंदु क्रमशः निर्धारित किए जाते हैं;
• "रिक्त स्थान बाएं / दाएं"। विभाजक के दाईं और बाईं ओर व्हाट्सएप पात्रों की उपस्थिति निर्धारित करें;
• "विराम चिह्न प्रतीक दाएं / बाएं";
• "दाईं / बाईं ओर संख्या";
• "दाईं / बाईं तरफ अपरकेस / लोअरकेस अक्षर";
• "दाईं / बाईं तरफ ब्रैकेट खोलना / बंद करना";
• "मानक संक्षिप्त रूप";
• "सामान्य रूप के अज्ञात रूप xxx.-xx. xx। ”आदि।
क्लासिफायर एल्गोरिथ्म
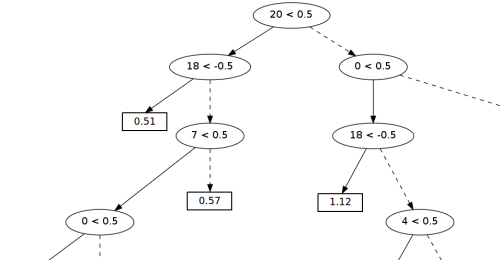
चित्र 1. निर्णय वृक्ष का एक टुकड़ा।
क्लासिफायरियर के आधार के रूप में, हमने "निर्णय पेड़ों" का उपयोग किया जो कि मशीन सीखने में व्यापक रूप से उपयोग किए जाते हैं। हमारे क्लासिफ़ायर से एक वास्तविक "पेड़" का एक उदाहरण चित्र 1 में दिखाया गया है (हम एक टुकड़ा देते हैं, क्योंकि पूरा "पेड़" बहुत बड़ा है)।
पेड़ के "नोड्स" में नियमों की जांच करने की शर्तें हैं। "20 <0.5" फॉर्म के एक रिकॉर्ड का मतलब है कि यदि नियम संख्या 20 में 0.5 अंक से कम स्कोर किया गया है, तो आपको बाएं सबट्री पर स्थानांतरित करने की आवश्यकता है, अन्यथा दाईं ओर।
संभावना का अनुमान है कि भाजक वाक्य का अंत है "पेड़ के पत्ते" (उच्च मूल्य, उच्च संभावना) में संग्रहीत किया जाता है। इस उदाहरण में, पेड़ निम्नलिखित नियमों के आधार पर निर्णय लेता है:
• नंबर 0 - विभाजक एक बिंदु है
• नंबर 4 - दाईं ओर रिक्त स्थान
• नंबर 7 - बाईं ओर एक पूंजी पत्र
• नंबर 18 - दीर्घवृत्त (पहले बिंदु के लिए +2, औसत के लिए +1, अंतिम के लिए -1)
• नंबर 20 - दाईं ओर शीर्षक (शीर्षक - एक पूंजी पत्र के साथ लिखा गया शब्द)।
दुर्भाग्य से, एक "पेड़" वर्गीकरण की स्वीकार्य गुणवत्ता प्रदान नहीं कर सकता है, इसलिए, हम एक वर्गीकरण के रूप में कई सौ अपेक्षाकृत सरल पेड़ों के संयोजन का उपयोग करते हैं।
प्रत्येक "ट्री" का निर्माण इस तरह से किया जाता है, ताकि क्लासिफायर के शेष "पेड़ों" की त्रुटि की अधिकतम क्षतिपूर्ति हो सके (यह दृष्टिकोण विशेष साहित्य में नाम बढ़ाने के तहत जाना जाता है)। इसके अतिरिक्त, एक पूरे के रूप में क्लासिफायर की गुणवत्ता में सुधार करने के लिए, हमने बूटस्ट्रैपिंग तकनीक का उपयोग किया, जहां प्रशिक्षण सेट का एक यादृच्छिक सबसेट "पेड़" से "पेड़" में बदलकर प्रत्येक "ट्री" का निर्माण करने के लिए उपयोग किया जाता है। इस प्रकार प्राप्त समग्र क्लासिफायर एक एकल "पेड़" की तुलना में काम की बेहतर गुणवत्ता को दर्शाता है।
वाक्यांशों के यादृच्छिक सेट के लिए मार्कअप प्रोग्राम आउटपुट का एक उदाहरण
Sn टैग के अंदर पूरे वाक्य हैं:< sn > "". </ sn >< sn > There is no silver bullet. </ sn >< sn > . . - . </ sn >< sn > . . . </ sn >< sn > Unix 01. 01. 1970. </ sn >< sn > . . 11.06.1999. </ sn >< sn > v.pupkin@nowhere.ru.com, - nowhere.ru.com/pupkin.html - , . </ sn >
* This source code was highlighted with Source Code Highlighter .
तालिका क्लासिफायर द्वारा बनाई गई रेटिंग को दर्शाती है। कटऑफ थ्रेशोल्ड (0.64 के बराबर) को प्रशिक्षण नमूने से प्राप्त अनुमानों के लिए सबसे कम वर्गों की विधि द्वारा चुना गया था। थ्रेशोल्ड शिफ्ट को प्रशिक्षण नमूने की विषमता द्वारा समझाया जाता है कि जब कोई विभाजक होता है और कब नहीं होता है।
| समाधान: | संदर्भ (अलग चरित्र केंद्र में है): | मूल्यांकन: |
| हां | `उस दिन" अच्छा था। " कोई चांदी का बल्ब नहीं है ' | 1,000 |
| हां | `कोई चांदी की गोली नहीं है। ए.एस. पुश्किन - महान पी ' | 0.734 |
| नहीं | `पुनः कोई चांदी की गोली नहीं है। ए.एस. पुश्किन - महान रस | -0.002 |
| नहीं | `कोई चांदी की गोली नहीं है। ए.एस. पुश्किन - महान रूसी ' | 0003 |
| हां | ʻIn एक महान रूसी कवि हैं। F. M. Dostoevsky में रहते थे ' | 0.972 |
| नहीं | `- एक महान रूसी कवि। एफ। एम। दोस्तोवस्की में रहते थे | -0.002 |
| नहीं | `महान रूसी कवि। एफ। एम। दोस्तोवस्की खुद नहीं रहते थे ' | 0003 |
| हां | `रूस के लिए सरल समय। यूनिक्स युग की शुरुआत की गिनती है ' | 1,000 |
| नहीं | यूनिक्स युग का `01 माना जाता है। 01. 1970. वसीली पुपकिन ' | 0460 |
| नहीं | `ओहि यूनिक्स को 01. 01. 1970 माना जाता है। वसीली पुपकिन था ' | 0.489 |
| हां | `ix को 01. 01. 1970 माना जाता है। वसीली पुपकिन को नियुक्त किया गया था ' | 0,500 |
| नहीं | `ली पुपकिन नियुक्त किया गया था और। के बारे में। महाप्रबंधक | 0.184 |
| नहीं | `पुपकिन नियुक्त किया गया था और। के बारे में। महाप्रबंधक 1 ' | 0050 |
| नहीं | `महाप्रबंधक 06/11/1999। उनका मेल adr ' | -0.001 |
| नहीं | `06/11/1999 के प्रबंधक। उनका डाक पता है ' | -0.001 |
| हां | `` 06/11/1999 को प्रबंधक। उनका मेलिंग पता v.pup है ' | 0,500 |
| नहीं | `999। उसका मेलिंग पता v.pupkin@nowhere.ru.com है, चाहे | -0.055 |
| नहीं | `v.pupkin@nowhere.ru.com पता, व्यक्तिगत पृष्ठ ' | 0,000 |
| नहीं | `v.pupkin@nowhere.ru.com पता, निजी पेज यहाँ ' | 0,001 |
| नहीं | `का यहाँ - nowhere.ru.com/pupkin.html - अब ' | 0,000 |
| नहीं | `यहाँ - nowhere.ru.com/pupkin.html - अब ' | -0.001 |
| नहीं | `p: //nowhere.ru.com/pupkin.html - अब सभी जानते हैं, ' | -0.001 |
| हां | `पता करें कि उससे कैसे संपर्क करें। ' | 0.972 |
हमारे बारे में क्या?
फिलहाल, वाक्यों में ग्रंथों को सही ढंग से तोड़ने के लिए मशीन सीखने की तकनीक हमारे खोज इंजन इंडेक्स में एम्बेडेड है। यह कार्यान्वयन Search@mail.Ru में स्निपेट्स की गुणवत्ता में सुधार करने का वादा करता है, और उस संदर्भ को और अधिक सटीक रूप से निर्धारित करने में भी मदद करेगा जिसमें शब्द का उपयोग किया जाता है - जो बदले में खोज परिणामों की प्रासंगिकता बढ़ाएगा।
एक्सट्रा करिकुलर रीडिंग
मशीन लर्निंग एल्गोरिदम की गहरी समझ के लिए, हम पुस्तक टी। हस्ती, आर। तिब्शीरानी, जेएचफ्रीडमैन "सांख्यिकीय शिक्षा के तत्व" की सिफारिश करते हैं, जो ऑन-लाइन उपलब्ध है।निष्ठा से,
टीम खोजें। Mail.Ru