
Hello! My name is Dmitry Samsonov, I work as a leading system administrator at Odnoklassniki. We have more than 7 thousand physical servers, 11 thousand containers in our cloud and 200 applications, which in different configurations form 700 different clusters. The vast majority of servers are running CentOS 7.
FragmentSmack Vulnerability Information Released August 14, 2018
( CVE-2018-5391 ) and SegmentSmack ( CVE-2018-5390 ). These are vulnerabilities with a network attack vector and a fairly high rating (7.5), which threatens with denial of service (DoS) due to resource exhaustion (CPU). A fix in the kernel for FragmentSmack was not proposed at that time, moreover, it came out much later than the publication of information about the vulnerability. To eliminate SegmentSmack, it was proposed to update the kernel. The update package itself was released on the same day, all that remained was to install it.
No, we are not at all against the kernel update! However, there are nuances ...
How do we update the core on the prod
In general, nothing complicated:
- Download packages
- Install them on a number of servers (including servers hosting our cloud);
- Make sure nothing is broken;
- Make sure that all standard kernel settings are applied without errors;
- Wait a few days;
- Check server performance;
- Switch deployment of new servers to a new kernel;
- Update all servers by data centers (one data center at a time to minimize the effect for users in case of problems);
- Reboot all servers.
Repeat for all branches of the cores we have. At the moment this is:
- Stock CentOS 7 3.10 - for most ordinary servers;
- Vanilla 4.19 is for our one-cloud because we need BFQ, BBR, etc .;
- Elrepo kernel-ml 5.2 is for highly loaded distributors , because 4.19 used to behave unstably, and features need the same ones.
As you might have guessed, rebooting thousands of servers takes the most time. Since not all vulnerabilities are critical for all servers, we only restart those that are directly accessible from the Internet. In the cloud, so as not to limit flexibility, we do not bind externally accessible containers to individual servers with a new core, but reboot all hosts without exception. Fortunately, the procedure is easier there than with regular servers. For example, stateless containers may simply move to another server during reboot.
Nevertheless, there is still a lot of work, and it can take several weeks, and in case of any problems with the new version - up to several months. Attackers are well aware of this, so plan B is needed.
FragmentSmack / SegmentSmack. Workaround
Fortunately, for some vulnerabilities, such a plan "B" exists, and it is called Workaround. Most often, this is a change in the kernel / application settings, which can minimize the possible effect or completely eliminate the exploitation of vulnerabilities.
In the case of FragmentSmack / SegmentSmack , the following Workaround was proposed:
“ You can change the default values of 4MB and 3MB in net.ipv4.ipfrag_high_thresh and net.ipv4.ipfrag_low_thresh (and their analogs for ipv6 net.ipv6.ipfrag_high_thresh and net.ipv6.ipfrag_low_thresh) by 256 kB and 192 kB, respectively. Tests show a slight to a significant drop in CPU usage during an attack, depending on equipment, settings, and conditions. However, there may be some performance impact due to ipfrag_high_thresh = 262144 bytes, since only two 64K fragments can fit in the rebuild queue at a time. For example, there is a risk that applications working with large UDP packets will break . ”
The parameters themselves in the kernel documentation are described as follows:
ipfrag_high_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments.
ipfrag_low_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments before the kernel
begins to remove incomplete fragment queues to free up resources.
The kernel still accepts new fragments for defragmentation.
On production services, we don’t have large UDP. There is no fragmented traffic on the LAN; there is, but not significant, traffic on the WAN. Nothing bodes - you can roll Workaround!
FragmentSmack / SegmentSmack. First blood
The first problem we encountered was that cloud containers sometimes only partially applied new settings (only ipfrag_low_thresh), and sometimes they didn’t use them at all - they just crashed at the start. It was not possible to reproduce the problem stably (manually all the settings were applied without any difficulties). Understanding why the container crashes at the start is also not so simple: no errors were found. One thing was certain for sure: rolling back the settings solves the problem of dropping containers.
Why is it not enough to use Sysctl on the host? The container lives in its dedicated network Namespace, so at least part of the network Sysctl parameters in the container may differ from the host.
How exactly do the Sysctl settings in the container apply? Since we have unprivileged containers, changing any Sysctl settings by going into the container itself will fail - there simply will not be enough rights. At that time, our cloud used Docker (now Podman ) to launch containers. The docker via the API passed the parameters of the new container, including the necessary Sysctl settings.
In the course of enumerating the versions, it turned out that the Docker API did not throw all the errors (at least in version 1.10). When trying to start the container through “docker run”, we finally saw at least something:
write /proc/sys/net/ipv4/ipfrag_high_thresh: invalid argument docker: Error response from daemon: Cannot start container <...>: [9] System error: could not synchronise with container process.
The parameter value is not valid. But why? And why is it not valid only sometimes? It turned out that Docker did not guarantee the application of Sysctl parameters (the latest tested version was 1.13.1), so sometimes ipfrag_high_thresh tried to set to 256K when ipfrag_low_thresh was still 3M, i.e. the upper bound was lower than the lower one, which led to an error.
At that time, we already used our own mechanism for re-configuring the container after start (freezing the container via cgroup freezer and executing commands in the container namespace via ip netns ), and we also added Sysctl parameters to this part. The problem was solved.
FragmentSmack / SegmentSmack. First blood 2
Before we could figure out how to use Workaround in the cloud, the first rare complaints from users began to arrive. At that time, several weeks passed since the start of Workaround on the first servers. The initial investigation showed that complaints were received about individual services, and not all servers of these services. The problem has regained an extremely vague character.
First of all, of course, we tried to roll back the Sysctl settings, but this did not give any effect. Various manipulations with the server and application settings also did not help. Reboot helped. Reboot for Linux is just as unnatural as it was a normal condition for working with Windows in the old days. Nevertheless, it helped, and we wrote off everything to a “glitch in the kernel” when applying the new settings in Sysctl. How frivolous it was ...
Three weeks later, the problem recurred. The configuration of these servers was quite simple: Nginx in proxy / balancer mode. The traffic is a bit. New introductory: the number of 504 errors ( Gateway Timeout ) is increasing every day on clients. The graph shows the number of 504 errors per day for this service:
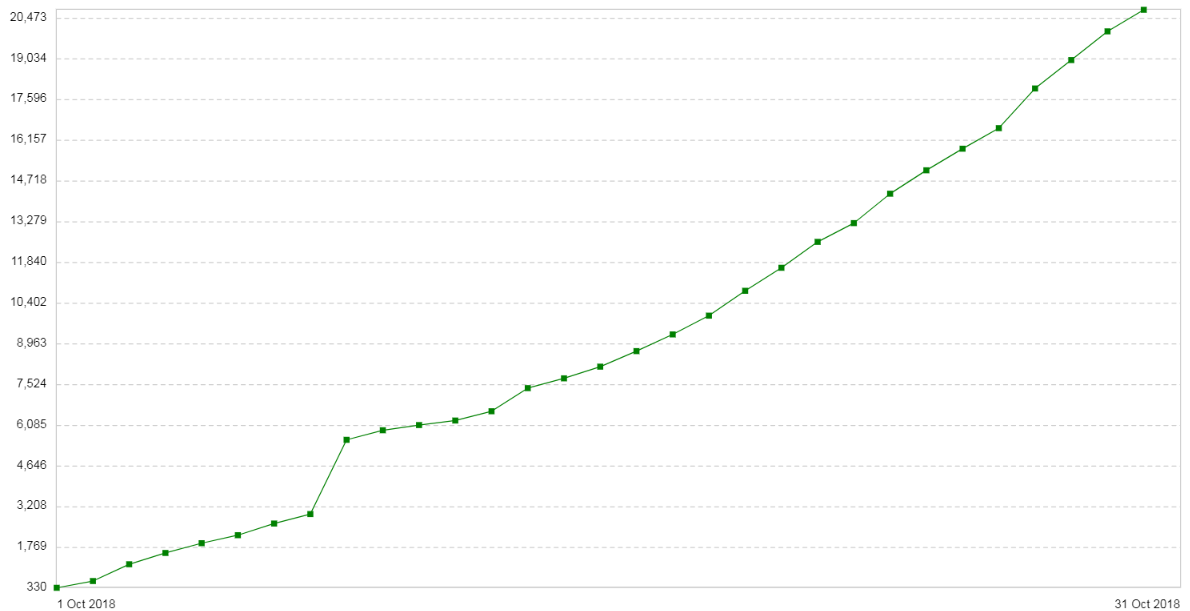
All errors are about the same backend - about the one that is in the cloud. The graph of memory consumption for packet fragments on this backend was as follows:
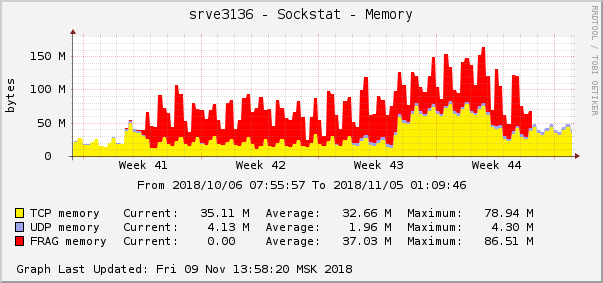
This is one of the most striking manifestations of the problem on the graphics of the operating system. In the cloud, just at the same time, another network problem was fixed with QoS (Traffic Control) settings. On the graph of memory consumption for packet fragments, it looked exactly the same:
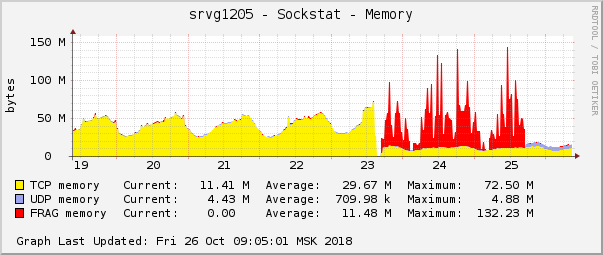
The assumption was simple: if they look the same on the graphs, then they have the same reason. Moreover, any problems with this type of memory are extremely rare.
The essence of the fixed problem was that in QoS we used the fq packet sheduler with default settings. By default, for one connection, it allows you to add 100 packets to the queue, and some connections in a situation of channel shortage began to clog the queue to failure. In this case, the packets drop. In tc statistics (tc -s qdisc), this can be seen as follows:
qdisc fq 2c6c: parent 1:2c6c limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 454701676345 bytes 491683359 pkt (dropped 464545, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
1024 flows (1021 inactive, 0 throttled)
0 gc, 0 highprio, 0 throttled, 464545 flows_plimit
“464545 flows_plimit” - these are the packets dropped due to exceeding the limit of the queue of one connection, and “dropped 464545” is the sum of all dropped packets of this sheduler. After increasing the length of the queue to 1 thousand and restarting the containers, the problem ceased to appear. You can sit back in a chair and have a smoothie.
FragmentSmack / SegmentSmack. Last blood
Firstly, a few months after the announcement of vulnerabilities in the kernel, finally a fix for FragmentSmack appeared (I recall that with the announcement in August a fix was released only for SegmentSmack), which gave us the chance to abandon Workaround, which caused us quite a bit of trouble. We already managed to transfer some of the servers to the new kernel during this time, and now we had to start from the beginning. Why did we update the kernel without waiting for the FragmentSmack fix? The fact is that the process of protecting against these vulnerabilities coincided (and merged) with the process of updating CentOS itself (which takes even more time than updating only the kernel). In addition, SegmentSmack is a more dangerous vulnerability, and a fix for it appeared immediately, so the point was in any case. However, we could not simply update the kernel on CentOS, because the FragmentSmack vulnerability, which appeared during CentOS 7.5, was fixed only in version 7.6, so we had to stop the upgrade to 7.5 and start all over again with the upgrade to 7.6. And so it is.
Secondly, rare user complaints about problems have returned to us. Now we already know for sure that all of them are connected with the download of files from clients to some of our servers. And through these servers there was a very small number of uploads from the total mass.
As we remember from the story above, the rollback of Sysctl did not help. Reboot helped, but temporarily.
Suspicions with Sysctl were not lifted, but this time it was required to collect as much information as possible. Also, there was an extreme lack of the ability to reproduce the problem with the client’s upload in order to more precisely examine what was happening.
Analysis of all available statistics and logs did not bring us closer to understanding what was happening. There was an acute lack of the ability to reproduce the problem in order to “feel” a particular connection. Finally, the developers on the special version of the application managed to achieve stable reproduction of problems on the test device when connected via Wi-Fi. This was a breakthrough in the investigation. The client connected to Nginx, it proxied to the backend, which was our Java application.
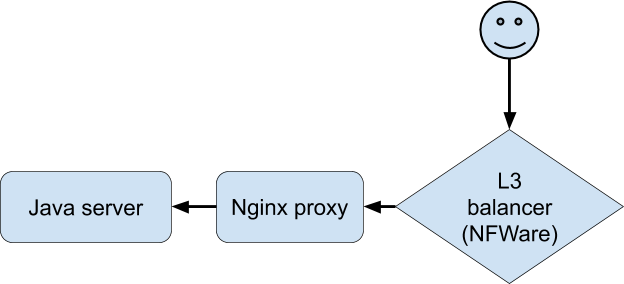
The dialog with problems was as follows (fixed on the Nginx proxy side):
- Client: request for information on downloading a file.
- Java server: answer.
- Client: POST with file.
- Java server: error.
At the same time, the Java server writes to the log that 0 bytes of data were received from the client, and the Nginx proxy that the request took more than 30 seconds (30 seconds is the timeout of the client application). Why timeout and why 0 bytes? From the point of view of HTTP, everything works as it should, but the POST with the file seems to disappear from the network. And it disappears between the client and Nginx. It's time to arm yourself with Tcpdump! But first you need to understand the network configuration. The nginx proxy is behind the N3ware L3 balancer. Tunneling is used to deliver packets from the L3 balancer to the server, which adds its headers to the packets:

At the same time, the network comes to this server in the form of Vlan-tagged traffic, which also adds its fields to packets:

And this traffic can be fragmented (the very small percentage of incoming fragmented traffic that we talked about when assessing risks from Workaround), which also changes the content of the headers:
Once again: packets are encapsulated by a Vlan tag, encapsulated by a tunnel, fragmented. To better understand how this happens, let's trace the packet route from the client to the Nginx proxy.
- The package gets to the L3-balancer. For correct routing inside the data center, the packet is encapsulated in the tunnel and sent to the network card.
- Since the packet + tunnel headers do not fit into the MTU, the packet is cut into fragments and sent to the network.
- The switch after the L3-balancer when receiving the package adds a Vlan tag to it and sends it further.
- The switch before the Nginx proxy sees (according to the port settings) that the server is expecting a Vlan-encapsulated packet, so it sends it as it is, without removing the Vlan tag.
- Linux receives fragments of individual packages and glues them into one large package.
- Then the package gets to the Vlan-interface, where the first layer is removed from it - Vlan-encapsulation.
- Linux then sends it to the Tunnel interface, where another layer is removed from it - Tunnel encapsulation.
The difficulty is to pass all this as parameters to tcpdump.
Let's start from the end: are there any clean (without extra headers) IP packets from clients with vlan and tunnel encapsulation removed?
tcpdump host <ip >
No, there were no such packages on the server. Therefore, the problem should be earlier. Are there packages with only Vlan encapsulation removed?
tcpdump ip[32:4]=0xx390x2xx
0xx390x2xx is the client IP address in hex format.
32: 4 - address and length of the field in which SCR IP is written in the Tunnel packet.
The address of the field had to be selected by brute force, as they write about 40, 44, 50, 54 on the Internet, but there was no IP address there. You can also look at one of the packets in hex (the -xx or -XX parameter in tcpdump) and calculate what address the IP is known to.
Are there any packet fragments without Vlan and Tunnel encapsulation removed?
tcpdump ((ip[6:2] > 0) and (not ip[6] = 64))
This magic will show us all the fragments, including the last. Probably, the same can be filtered by IP, but I did not try, since there are not very many such packets, and the ones I needed were easily found in the general stream. Here they are:
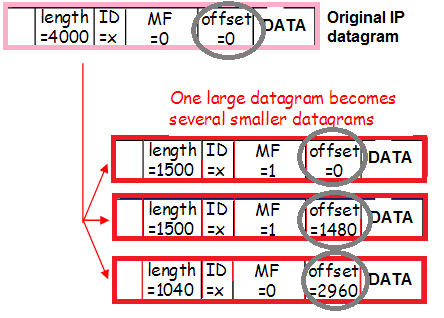
14:02:58.471063 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 1516: (tos 0x0, ttl 63, id 53652, offset 0 , flags [+], proto IPIP (4), length 1500)
11.11.11.11 > 22.22.22.22: truncated-ip - 20 bytes missing! (tos 0x0, ttl 50, id 57750, offset 0, flags [DF], proto TCP (6), length 1500)
33.33.33.33.33333 > 44.44.44.44.80: Flags [.], seq 0:1448, ack 1, win 343, options [nop,nop,TS val 11660691 ecr 2998165860], length 1448
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 05dc d194 2000 3f09 d5fb 0a66 387d E.......?....f8}
0x0020: 1x67 7899 4500 06xx e198 4000 3206 6xx4 .faEE.....@.2.m.
0x0030: b291 x9xx x345 2541 83b9 0050 9740 0x04 .......A...P.@..
0x0040: 6444 4939 8010 0257 8c3c 0000 0101 080x dDI9...W.\......
0x0050: 00b1 ed93 b2b4 6964 xxd8 ffe1 006a 4578 ......ad.....j Ex
0x0060: 6966 0000 4x4d 002a 0500 0008 0004 0100 if ..MM.*........
14:02:58.471103 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 62: (tos 0x0, ttl 63, id 53652, offset 1480 , flags [none], proto IPIP (4), length 40)
11.11.11.11 > 22.22.22.22: ip-proto-4
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 0028 d194 00b9 3f04 faf6 2x76 385x E..(....?....f8}
0x0020: 1x76 6545 xxxx 1x11 2d2c 0c21 8016 8e43 .faE...D-,.!...C
0x0030: x978 e91d x9b0 d608 0000 0000 0000 7c31 .x............|Q
0x0040: 881d c4b6 0000 0000 0000 0000 0000 ..............
These are two fragments of one package (the same ID 53652) with a photograph (the word Exif is visible in the first package). Due to the fact that there are packages at this level, but not glued in dumps, the problem is clearly with the assembly. Finally, there is documentary evidence of this!
The packet decoder did not reveal any problems that prevented the assembly. Tried here: hpd.gasmi.net . At first, when trying to cram something there, the decoder does not like the packet format. It turned out that there were some extra two octets between Srcmac and Ethertype (not related to fragment information). After removing them, the decoder worked. However, he showed no problems.
Say what you like, except for those very Sysctl nothing more was found. It remained to find a way to identify problematic servers in order to understand the scale and decide on further actions. Quickly enough I found the right counter:
netstat -s | grep "packet reassembles failed”
It is in snmpd under OID = 1.3.6.1.2.1.4.31.1.1.16.1 ( ipSystemStatsReasmFails ).
"The number of failures detected by the IP re-assembly algorithm (for whatever reason: timed out, errors, etc.)."
Among the group of servers on which the problem was studied, on two this counter increased faster, on two - slower, and on two did not increase at all. A comparison of the dynamics of this counter with the dynamics of HTTP errors on the Java server revealed a correlation. That is, the counter could be monitored.
Having a reliable indicator of problems is very important so that you can accurately determine whether Sysctl rollback helps, since from the previous story we know that it’s impossible to understand immediately from the application. This indicator would allow to identify all the problem areas in the production before users discover it.
After the Sysctl rollback, the monitoring errors stopped, so the cause of the problems was proved, as well as the fact that the rollback helps.
We rolled back the fragmentation settings on other servers, where a new monitoring caught fire, and somewhere we allocated even more memory for the fragments than before by default (this was udp-statistics, the partial loss of which was not noticeable against the general background).
The most important questions
Why do packages fragment on our L3 balancer? Most packages that arrive from users to the balancers are SYN and ACK. The sizes of these bags are small. But since the share of such packages is very large, against their background we did not notice the presence of large packages that began to fragment.
The reason was the broken advmss configuration script on servers with Vlan interfaces (there were very few servers with tagged traffic in production at that time). Advmss allows you to convey to the client information that the packets in our direction should be smaller so that after gluing the tunnel headers to them they do not have to be fragmented.
Why didn't Sysctl rollback help, but reboot help? Sysctl rollback changed the amount of memory available for gluing packages. At the same time, apparently the very fact of memory overflow for fragments led to inhibition of the connections, which led to the fact that the fragments were delayed in the queue for a long time. That is, the process is looping.
Rebut nullified the memory and everything was in order.
Could Workaround be dispensed with? Yes, but there is a great risk of leaving users without a service in the event of an attack. Of course, the use of Workaround as a result led to various problems, including the inhibition of one of the services by users, but nevertheless, we believe that the actions were justified.
Many thanks to Andrei Timofeev ( atimofeyev ) for helping with the investigation, and to Alexei Krenev ( devicex ) for the titanic work of updating Centos and kernels on the servers. The process, which in this case had to be started several times from the beginning, because of which it dragged on for many months.