Learning with a teacher and learning without a teacher is not all. Everyone knows that. Start with OpenAI Gym.

Are you going to defeat the world chess champion, backgammon or go?
There is a way that will allow you to do this - reinforcement training.
What is reinforcement learning?
Reinforced learning is learning to make consistent decisions in the environment with the maximum reward received that is given for each action.
There is no teacher in him, only a signal of reward from the environment. Time matters, and actions affect subsequent data. Such conditions create difficulties for learning with or without a teacher.

In the example below, the mouse tries to find as much food as it can and avoids electric shocks when possible.

A mouse can be brave and can get a discharge to get to a place with lots of cheese. It will be better than just standing still and not receiving anything.
The mouse does not want to make the best decisions in each specific situation. This would require great mental outlay from her, and it would not be universal.
Reinforced learning provides some magic sets of methods that allow our mouse to learn how to avoid electroshock and get as much food as possible.
The mouse is an agent. A maze with walls, cheese and stun guns is the environment . The mouse can move left, right, up, down - these are actions .
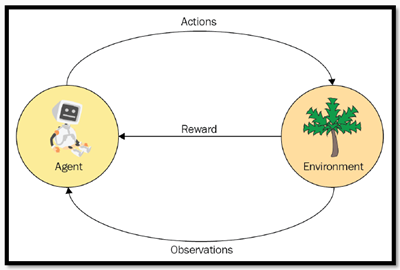
The mouse wants cheese, not an electric shock. Cheese is a reward . The mouse can inspect the environment - these are observations .
Ice reinforcement training
Let's leave the mouse in the maze and move on to the ice. "Winter came. You and your friends were throwing frisbee in the park when you suddenly threw frisbee in the middle of the lake. Basically, the water in the lake was frozen, but there were a few holes where the ice melted. ( source )

“If you step on one of the holes, you will fall into ice water. In addition, there is a huge shortage of frisbee in the world, so it is absolutely necessary that you go around the lake and find a drive. ”( Source )
How do you feel in a similar situation?
This is a challenge for reinforcement learning. The agent controls the character’s movements in the grid world. Some grid tiles are passable, while others cause the character to fall into the water. The agent receives a reward for finding a passable path to the goal.
We can simulate such an environment using OpenAI Gym - a toolkit for developing and comparing learning algorithms with reinforcements. It provides access to a standardized set of environments, such as in our example, which is called Frozen Lake . This is a text environment that can be created with a couple of lines of code.
import gym from gym.envs.registration import register # load 4x4 environment if 'FrozenLakeNotSlippery-v0' in gym.envs.registry.env_specs: del gym.envs.registry.env_specs['FrozenLakeNotSlippery-v0'] register(id='FrozenLakeNotSlippery-v0', entry_point='gym.envs.toy_text:FrozenLakeEnv', kwargs={'map_name' : '4x4', 'is_slippery': False}, max_episode_steps=100, reward_threshold=0.8196 ) # load 16x16 environment if 'FrozenLake8x8NotSlippery-v0' in gym.envs.registry.env_specs: del gym.envs.registry.env_specs['FrozenLake8x8NotSlippery-v0'] register( id='FrozenLake8x8NotSlippery-v0', entry_point='gym.envs.toy_text:FrozenLakeEnv', kwargs={'map_name' : '8x8', 'is_slippery': False}, max_episode_steps=100, reward_threshold=0.8196 )
Now we need a structure that will allow us to systematically approach the problems of learning with reinforcement.
Markov decision making process
In our example, the agent controls the character’s movement on the grid world, and this environment is called a fully observable environment.
Since the future tile does not depend on past tiles, taking into account the current tile
(we are dealing with a sequence of random states, that is, with the Markov property ), so we are dealing with the so-called Markov process .
The current state encapsulates everything that is needed to decide what the next move will be; nothing is needed to remember.
On each next cell (that is, a situation), the agent chooses with some probability the action that leads to the next cell, that is, the situation, and the environment responds to the agent with observation and reward.
We add the reward function and the discount coefficient to the Markov process, and we get the so-called Markov reward process . Adding a set of actions, we get the Markov decision making process ( MDP ). The components of MDP are described in more detail below.
condition
A state is a part of the environment, a numerical representation of what the agent observes at a certain point in time in the environment, the state of the lake grid. S is the starting point, G is the target, F is the solid ice on which the agent can stand, and H is the hole into which the agent will fall if it steps on it. We have 16 states in a 4 by 4 grid environment, or 64 states in an 8 by 8 environment. Below we will draw an example of a 4 by 4 environment using OpenAI Gym.
def view_states_frozen_lake(env = gym.make('FrozenLakeNotSlippery-v0')): print(env.observation_space) print() env.env.s=random.randint(0,env.observation_space.n-1) env.render() view_states_frozen_lake()
Actions
The agent has 4 possible actions, which are represented in the environment as 0, 1, 2, 3 for left, right, bottom, top, respectively.
def view_actions_frozen_lake(env = gym.make('FrozenLakeNotSlippery-v0')): print(env.action_space) print("Possible actions: [0..%a]" % (env.action_space.n-1)) view_actions_frozen_lake()

State transition model
The state transition model describes how the state of the environment changes when an agent takes action based on his current state.
The model is usually described by the transition probability, which is expressed as a square transition matrix of size N x N, where N is the number of states of our model. The illustration below is an example of such a matrix for weather conditions.
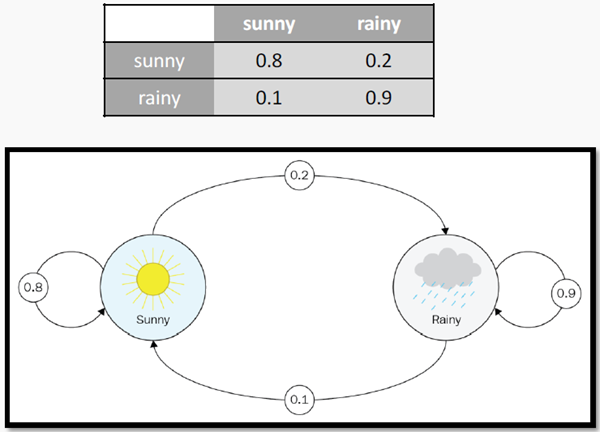
In the Frozen Lake environment, we assume that the lake is not slippery. If we go right, then we definitely go right. Therefore, all probabilities are equal.
“Left” moves the agent 1 cell to the left or leaves it in the same position if the agent is at the left border.
“Right” moves it 1 cell to the right or leaves it in the same position if the agent is at the right border.
“Up” moves the agent 1 cell up, or the agent remains in the same place if it is at the upper boundary.
“Down” moves the agent 1 cell down, or it stays in the same place if it is at the lower boundary.
Remuneration
In each state F, the agent receives 0 rewards; in state H, he receives -1, since, having passed into this state, the agent dies. And when the agent reaches the goal, he receives a +1 reward.
Due to the fact that both models, the transition model and the reward model, are deterministic functions, this makes the environment deterministic. \
Discount
The discount is an optional parameter that controls the importance of future rewards. It is measured in the range from 0 to 1. The purpose of this parameter is to prevent the total reward from going to infinity.
The discount also models the behavior of the agent when the agent prefers immediate rewards to rewards that may be received in the future.
Value
The value of the fortune is the expected long-term income with a discount for the fortune.
Policy (π)
The strategy that the agent uses to select the next action is called a policy. Among all available policies, the optimal one is that which maximizes the amount of remuneration received or expected during the episode.
Episode
The episode begins when the agent appears on the starting cell, and ends when the agent either falls into the hole or reaches the target cell.
Let's visualize it all
After reviewing all the concepts involved in the Markov decision-making process, we can now model several random actions in a 16x16 environment using OpenAI Gym. Each time, the agent selects a random action and performs it. The system calculates the reward and displays the new state of the environment.
def simulate_frozen_lake(env = gym.make('FrozenLakeNotSlippery-v0'), nb_trials=10): rew_tot=0 obs= env.reset() env.render() for _ in range(nb_trials+1): action = env.action_space.sample() # select a random action obs, rew, done, info = env.step(action) # perform the action rew_tot = rew_tot + rew # calculate the total reward env.render() # display the environment print("Reward: %r" % rew_tot) # print the total reward simulate_frozen_lake(env = gym.make('FrozenLake8x8NotSlippery-v0'))

Conclusion
In this article, we briefly discussed the basic concepts of reinforcement learning. Our example provided an introduction to the OpenAI Gym toolkit, which makes it easy to experiment with pre-built environments.
In the next part, we will present how to design and implement policies that will allow the agent to take a set of actions in order to achieve the goal and receive an award such as defeating a world champion.
Thanks for attention.