Neural networks without a teacher are translated from languages for which there is no parallel corpus of texts.
Machine translation using neural networks has come a long way from the time of the first scientific research on this topic until the moment when Google announced the full translation of the Google Translate service into in-depth training .
As is known, at the core of the neural translator is the mechanism of bidirectional recurrent neural networks (Bidirectional Recurrent Neural Networks), built on matrix calculations, which allows you to build much more complex probabilistic models than statistical machine translators. However, it has always been thought that neural translation, like statistical, requires parallel text corpus in two languages for learning. A neural network is trained on these shells, taking the human translation as a reference.
As it turned out now, neural networks are able to master a new language for translation, even without a parallel corpus of texts! On the site of the preprints arXiv.org two works on this topic were published at once .
“Imagine that you give a person a lot of Chinese books and a lot of Arabic books - there’s no one among them - and this person learns to translate from Chinese into Arabic. It seems impossible, right? But we showed that a computer is capable of such a thing, ” says Mikel Artetxe, a computer scientist at the University of the Basque Country in San Sebastian (Spain).
Most of the neural networks of machine translation are trained “with the teacher”, in the role of which a parallel corpus of texts, translated by man, just acts. In the process of learning, roughly speaking, the neural network makes an assumption, verifies with the standard, and makes the necessary settings in its systems, then learns further. The problem is that for some languages in the world there are not a large number of parallel texts, so they are not available for traditional machine translation neural networks.
Two new models offer a new approach: learning the neural network of machine translation without a teacher . The system itself tries to create a kind of parallel corpus of texts, performing the clustering of words around each other. The fact is that in most languages of the world there are the same meanings, which simply correspond to different words. So, all these meanings are grouped into the same clusters, that is, the same meanings-words are grouped around the same meanings-words, almost independently of the language (see the article “The Google Translate Neural Network Composed of a Single Base of Meanings of Human Words ”) .
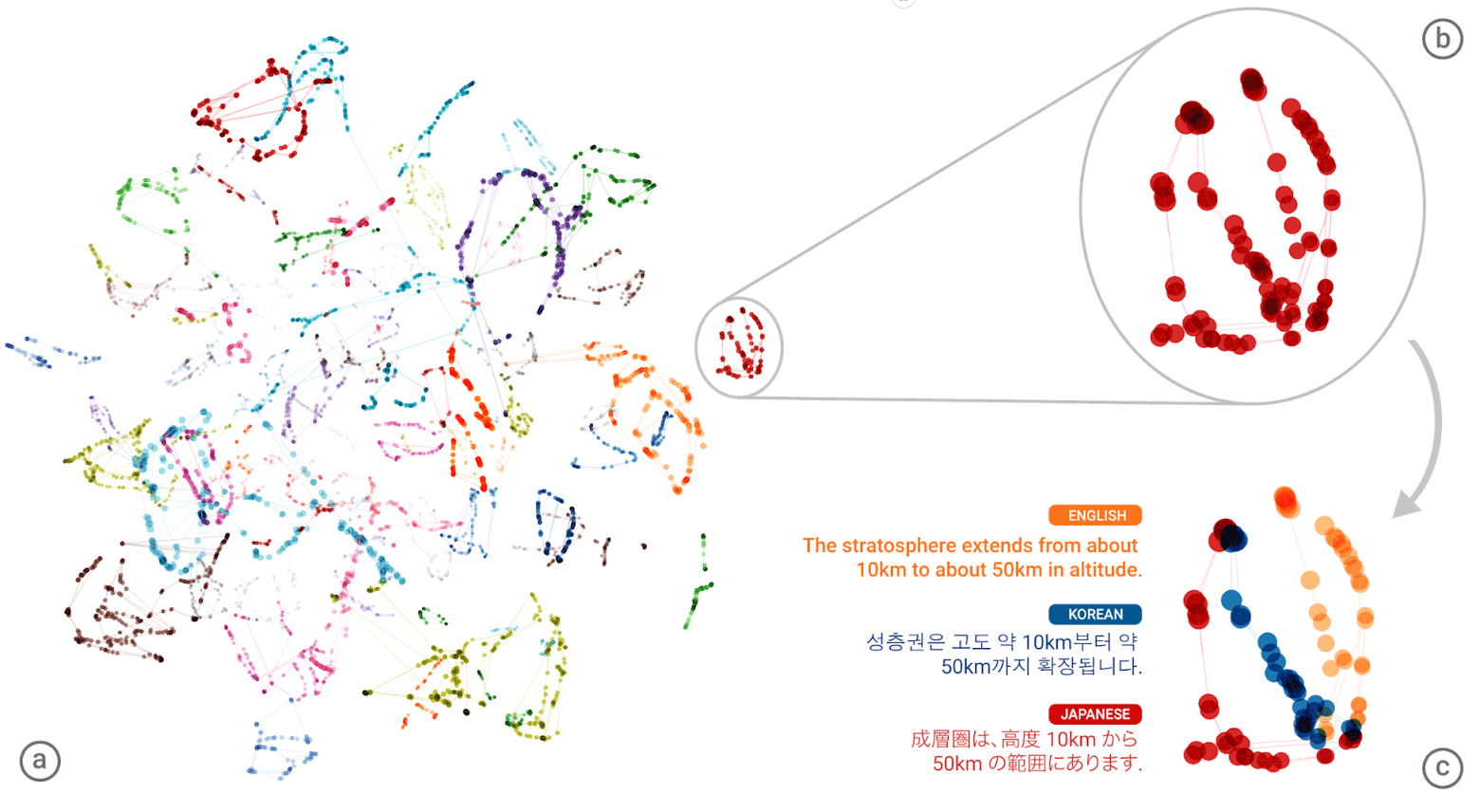
The “universal language” of the Google Neural Machine Translation Neural Network (GNMT). In the left illustration, different colors show clusters of the meanings of each word, on the lower right - the meanings of the word obtained for it from different human languages: English, Korean and Japanese.
Having created a giant "atlas" for each language, then the system tries to impose one such atlas on another - and here you are, you have a kind of parallel text corpus ready!
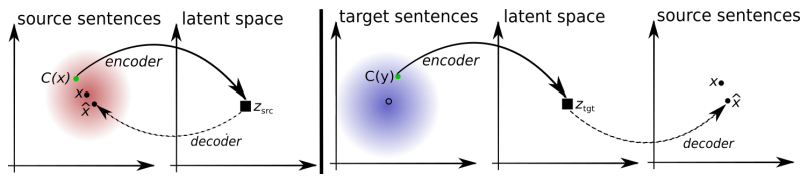
You can compare the schemas of the two proposed learning architectures without a teacher.
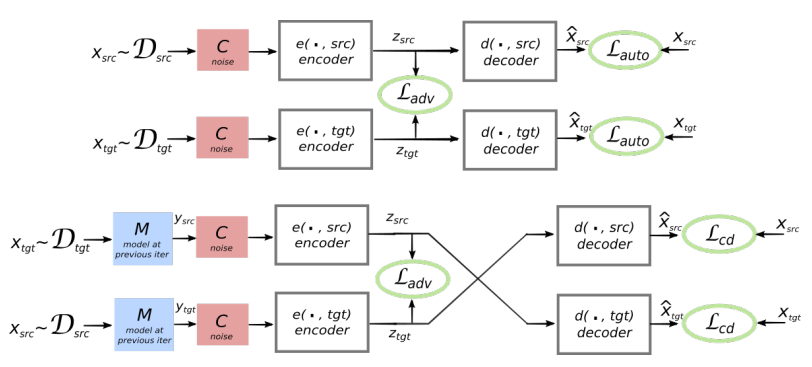
The architecture of the proposed system. For each sentence in the L1 language, the system learns the alternation of two steps: 1) noise reduction (denoising), which optimizes the probability of coding a noisy version of the sentence with a common encoder and its reconstruction by the L1 decoder; 2) back translation when the sentence is translated in the output mode (that is, encoded by a common encoder and decoded by the L2 decoder), and then the probability of encoding this translated sentence with a common encoder and restoring the original sentence by the L1 decoder is optimized. Illustration: a scientific article by Mikel Artetkse et al.
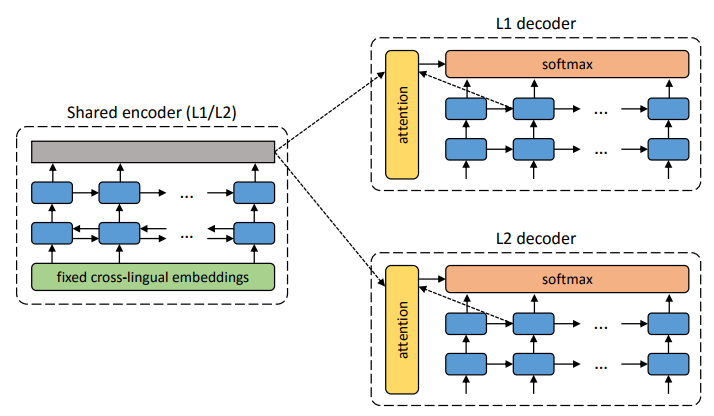
The proposed architecture and learning objectives of the system (from the second scientific work). The architecture is a translation model based on sentences, where both the encoder and the decoder work in two languages, depending on the identifier of the input language, which swaps the search tables. Above (auto-coding): The model learns to perform noise reduction in each domain. Below (translation): as before, plus we encode from another language, using as input the translation produced by the model in the previous iteration (blue rectangle). Green ellipses indicate terms as a function of loss. Illustration: a scientific article by Guiloma Lamble et al.
Both scientific papers use a noticeably similar technique with a few differences. But in both cases, the translation is carried out through some intermediate "language" or, rather, an intermediate dimension or space. So far, neural networks without a teacher show not very high quality of translation, but the authors say that it is easy to improve, if you use a little help from a teacher, just now for the sake of the purity of the experiment did not.
Note that the second scientific work published by researchers from the Facebook AI.
Works are presented for the International Conference on Educational Representations of 2018 (International Conference on Learning Representations). None of the articles have yet been published in the scientific press.
All Articles